
作者简介:

倪生华
淘宝网 资深技术专家
花名玄黎,12年加入淘宝无线事业部,经历了手淘从几十万日活到现在亿级日活的过程,一直负责手淘端研发运维等工程效率相关的工作,团队负责开发的支撑体系,很好的解决目前手淘目前快速迭代和大团队协作的问题,主导发起了客户端侧的技术监控、动态修复等体系。
一、前言
我个人比较关注于整个工程效率以及质量、性能、稳定性这一块。移动客户端运维这块,从一开始就没有专职运维工程师做,一直是研发工程师自己在做,所以我有时候也会关注一些所谓的移动化运维的事情,本文将围绕手淘 APP 的运维交付实践进行介绍。
二、我们面对的挑战

如果大家用过客户端或者有团队做 APP 开发的话,应该经常会被老板问到这个问题,突然有用户反馈说为什么我手机突然图片打不开了,或者视频打不开了,或者为什么老是网络错误,甚至可能老板突然跟你说,为什么我用着用着突然发现不行了。
你听到这个信息的时候,基本上会一头懵逼。因为这些情况会有很多种场景,有可能用户只在山东或者北京的某个区域出现,在我们的测试环境,根本没法重现。
传统运维中,我们运维的对象都是机房的服务器、PC机,到了客户端这一块,你运维的就是一个个独立的手机,问题的根源可能是某几个用户的反馈或者十几个用户的反馈。
因为这种运维对象的转变,整个运维的重点从原先的集群资源管控变成了更多是监控、排查、分析以及快速修复的能力。
三、我们的运维场景
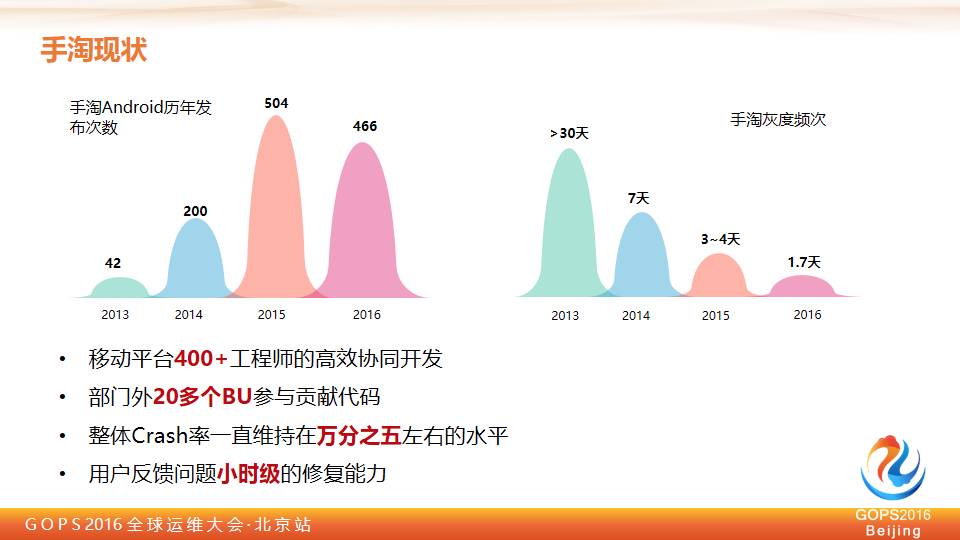
手机淘宝从2013年开始,整个团队快速发展,2013年开始整个手机淘宝每年会发版40多次,大概一个月或者半个月会发版一次。
到2014年的时候,整个阿里集团进行了 All-In,团队从之前的六七十人,突然扩张到两百多人,最多的时候到四百多人,整个发布突然从42次到200次。
到2015年开始,我们在思考今天有这么多人,我们怎么快速交付给用户一个非常好体验的 APP ?所以我们采取了一些措施,发布的策略从2014年的200多次变成500多次。
500多次什么概念?基本上我们每天都在给用户推送带用新的功能、新的版本的 APP 。到2016年9月份,发版466次,基本上一天会给用户推送1.7个版本。
目前整个手机淘宝,光手机淘宝部门大概会有400多个工程师,除了手机淘宝之外,整个阿里系还会有20多个BU同时在为手机淘宝贡献代码。
我们在这么快的节奏、这么多人的情况下,目前我们的崩溃率基本上在万分之五,从接到用户反馈到整个问题的定位、修复,基本上是小时范围内,把整个问题全部解决掉。
四、重压下的交付体系
我们经常讲传统的运维,等到开发工程师把所谓的机器部署上之后,真正上线了,运维工程师才开始接,我们只管我们的机器、机房、容器。
在整个客户端这块,我们内部有句话:“
在你测试完成开始,你的运维工作就开始了
”。测试完成之后,这就是一个最终的交付产物。
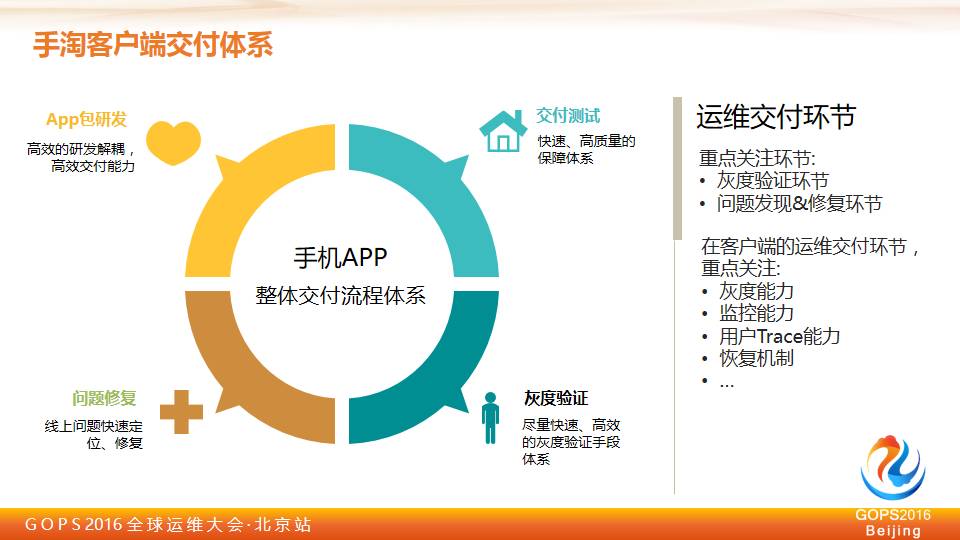
我们研发工程师会搞定所有的事情,主要核心的内容是
快速交付
,包括 APP 的研发,交付测试,灰度验证、问题修复。我们认为在整个移动端来说,运维重点关注是这两个环节。
-
灰度环节
因为移动端其实跟 PC 端还不太一样,PC 端很多东西都可控,在服务器里面发现问题了随时可以下掉。
但如果说今天你的 APP 用户大规模安装之后出现了问题,基本上是非常严重的问题,需要等到用户全部重新安装一遍,可能这个时间是7天或者14天。
在整个移动端来讲,多快能够灰度出一个 APP ,得到反馈验证,是一个非常重要的能力。
-
发现问题解决问题环节
另一个是发现问题解决问题的环节,今天你灰度出去了,你怎么快速发现问题?这些问题的原因是什么?怎么快速定位解决这个问题的能力?
可能以前在服务器端,所有东西在你自己的机房里,发现问题你自己上去看一下日志或者查一下监控就可以。
现在的挑战是,你所有的机器都在用户的手机上,用户机器的差别、网络的差别、手机上硬件的差别等,这方方面面的不一样带来了非常多的多样性,怎么样把这些个体的情况都能发现?
在这两个环节里,也有我们非常注重的几个能力。
-
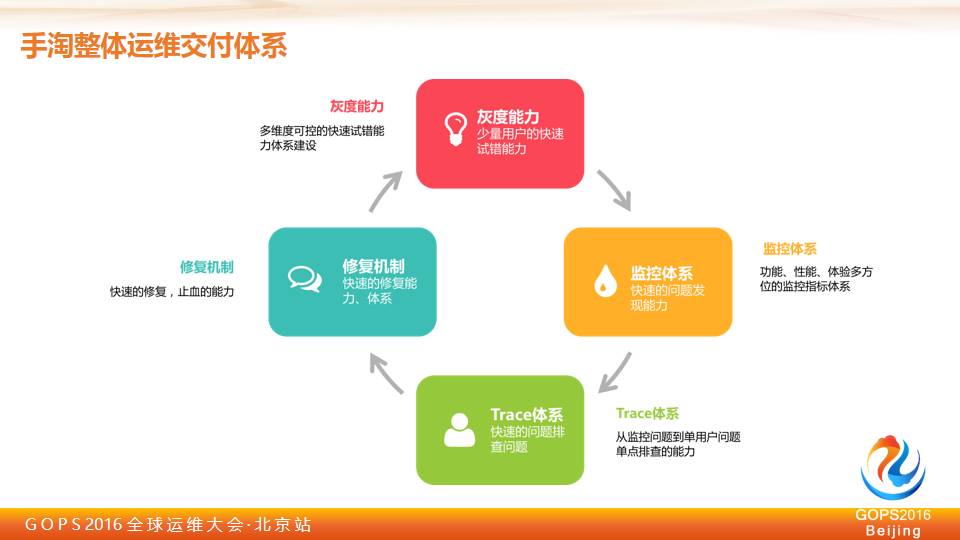
灰度能力
怎么样快速把我们的问题、我们新的包或新的改动,能够快速交付到用户上面去,能够通过用户的使用快速发现我们的问题,能够加快我们的迭代速度。
-
监控能力
灰度完之后需要一个监控体系,我们需要快速拿到我们所有的想要的东西,包括功能上、性能上甚至稳定性上的。所以整个监控体系的搭建是非常有必要的。
-
Trace能力
发现了问题,我怎么能够快速知道原因,到底是因为网络的问题还是因为我们程序的问题甚至因为其他问题,整个 Trace 体系也是非常重要的一块问题。
-
恢复机制
你发现问题了,要去修复,这可能不像服务端,今天把机器下掉就可以了,有可能你的 APP 已经放到用户手上去了,你怎么快速把它修复?
五、 APP的灰度体系建设
我们来看看整个 APP 的灰度体系是怎么建立起来的。
-
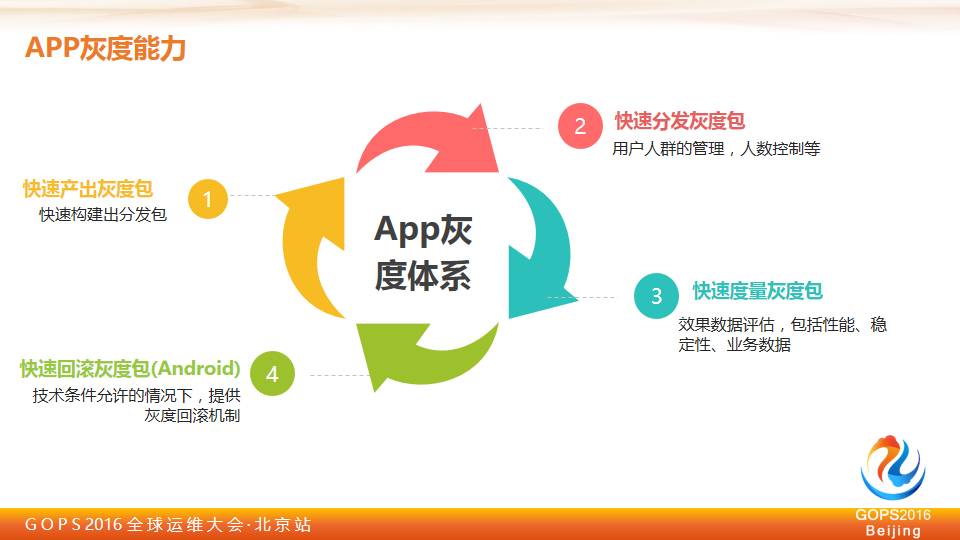
快速产出灰度包
一个好的灰度 APP 首先第一件事情是我们需要快速产出我们的灰度包,我们希望我们今天的灰度包变更能够尽量少,或者我今天发现问题以后,能够快速重新再出来一个灰度包去验证。
-
快速分发灰度包
今天灰度我包有了,我怎么样快速分发给用户。传统意义上的灰度像我们前几年,找一个20万用户的群体,发个消息给用户,让用户装一下,这在整个互联网公司是非常低效的。
怎么在几十分钟或者半个小时之内快速把整个改动包推送到用户端,甚至让用户是可以控制的。
-
快速度量灰度包
今天我的灰度包出去了,今天我们灰度上面的效果数据的评估,我们应该怎么来做?
-
快速回滚灰度包
这一块是说如果技术条件允许的情况下,希望我们的灰度包能够做一些回滚的机制,这个在安卓上是完全可以做到的,今天用户推送灰度包之后发现不行,我可以对用户进行回滚,可能用户完全没有感知。
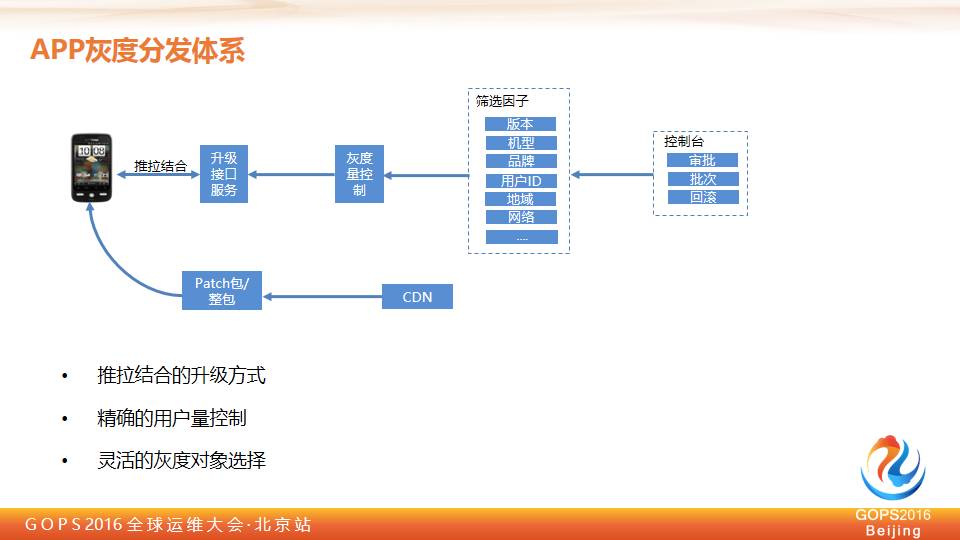
整体来讲,整个灰度体系的搭建我们通过三个手段来做
-
通过推拉结合的升级方式,这一块的做法,我们希望整个灰度的包能够快速的到达用户,希望用户说他今天可能在30分钟之内我们快速到达用户。
-
我们希望精确的用户量控制,我们可能一开始希望用户是10个,到100个,到1000个,到10000个。
-
希望灰度对象可灵活地选择。这个就要求今天我们的灰度接口里面,需要天然的放一些因子上去,在服务单中我们会对这些因子进行筛选,在整个服务端挑选出来一些符合我们条件的用户。
六、灰度操作控制台实例
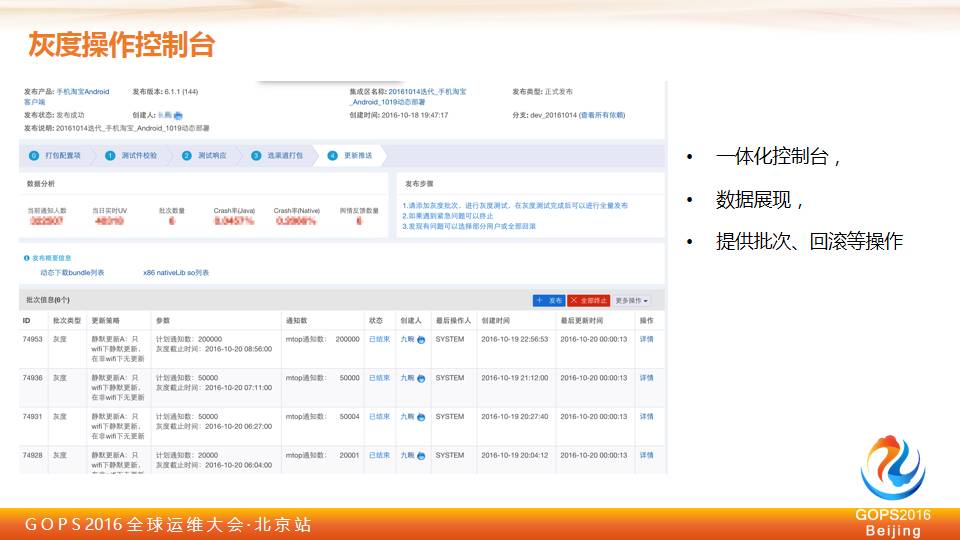
这个其实是在我们整个内部所谓的灰度常见的控制台操作,我们会对整个灰度进行批次操作。
当一开始灰度的时候只灰度2000或者2万个用户,在上面可以实时看到当天升级的用户数,包括我们当前的整个UV,这些灰度用户的用户反馈、舆情反馈数,我们希望在整个操作人员能够实时看到当前这批灰度用户的影响。
如果觉得没有问题,一开始可能推2万,2万发现没问题,再推10万,发现10万没问题,再推30万,依次往上加。这样它的灰度操作就可能很简单,也可能不需要专业的技术人员做这件事情。
我们把整个所谓的灰度的粉线控制做得非常小。
-
通过人的批次上来控制,风险是依次累加的过程,2万个用户没问题才会推送到5万个用户,5万个用户没问题才会推送到100万个用户。
-
我们把所有可能直接影响用户的反馈信息,他的数据信息在整个平台上做了一一的展现,甚至在我们整个系统上我们会有个阈值,如果灰度突然暴涨,平台自动会把整个灰度给终止掉。
这样做的好处是,今天我们把整个灰度能力放开给所有人,所有的开发工程师、测试工程师大家都可以做这个事情。
今天的手机淘宝,我们基本上10分钟就可以灰度到30万用户,全天24小时任何时候,你只要推送一个灰度上去,10分钟时间可以达到我们想要的用户数。在30分钟之内,我们就可以评估到我们的性能、稳定性、功能上是不是OK。
七、度量&监控体系的建设
我们通过灰度把包放出去后,我们怎么知道这个包好不好用?其实我们有一套监控体系,在手机端监控的面会分为四个方面。

-
稳定性
APP 这个端最关注的就是稳定性,我们会实时关注用户的包括 Crash、ANR、主线程卡顿甚至于耗电这些数据。
-
性能体验
因为可能在整个 APP 端,你的功能好用,但是如果非常耗电、非常卡,其实对整个产品的数据是非常有影响的。
所以希望能够灰度出去的数据,我们能够实时看到性能数据。其中最关心的包括我们的启动时间、页面响应时间、流畅度的数据。
-
核心指标
比如页面点击转化率、用户的停留时间。
-
用户舆情
我们在灰度上面可能会做一些特殊的事情,我们会把我们灰度的用户反馈的标在所有页面进行(透出),灰度可能在任何地方,用着用着就出现一个灰度的反馈。我们可能原来只有10个用户的灰度量,但是它的整个反馈量可以达到现网上几千万用户的反馈量,可以快速帮助我们得到非常多的信息
。
八、评估标准的制定
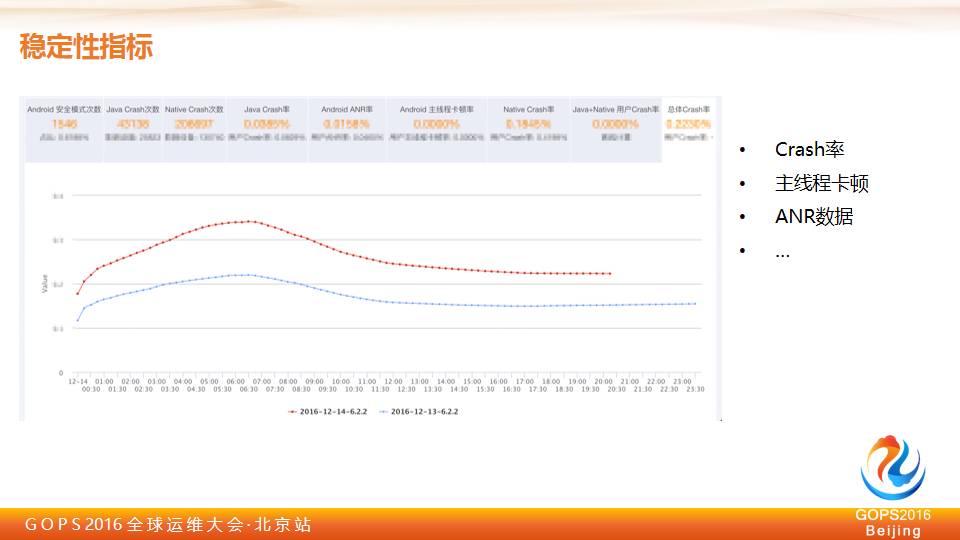
稳定性指标大家可能做 APP 的都会比较了解,今天我们关注的是哪些点?
发现这个版本的数据有没有变差或者有差异性,这个会作为我们发布之前非常重要的一个指标,我们会来判断今天整个稳定性上有没有因为你的改动导致我们 APP 变差。
九、性能监控体系实例
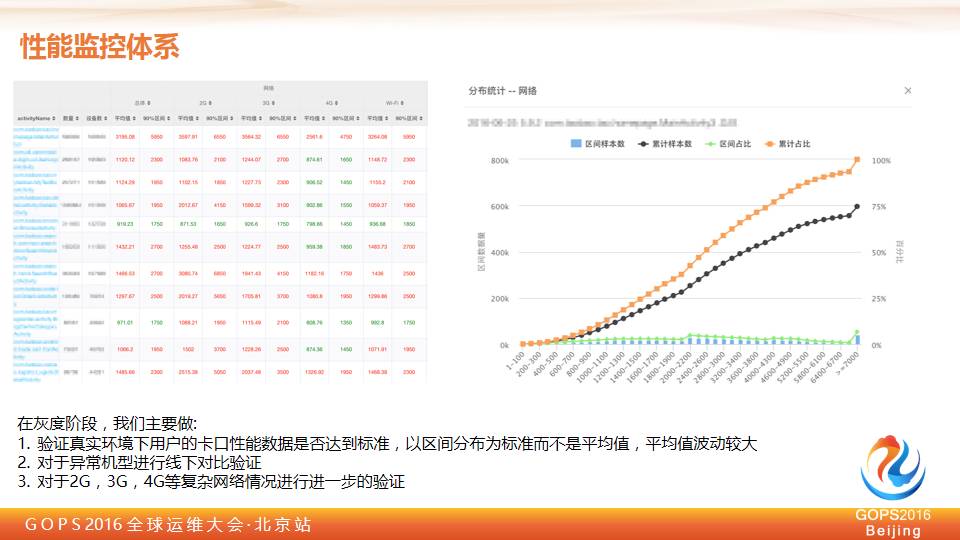
上图是一个性能监控的截图,大家知道在整个移动端或者说在服务端,做性能很简单,去压测一下。但现在很多人说服务端环境可能跟线上环境不一样,客户端来说这个东西更加不可信,所谓的网络的差异,机型的差异,带来的整个性能差异是非常大的。
在我们灰度完之后,我们会实时产出一份所有页面的整个性能数据,包括网络端甚至于各个端的性能的分布图,做监控数据都知道,这个平均值是非常容易欺骗人的,我们可能除了关注整个平均值之外,我们会更加关注长尾用户的情况。
因为这套机制,我们发现对整个阶段会进行区分,在测试阶段,更多的做卡口,拿一个标准的路径,比如大家同时是 Wifi 下面,只要你不超过一定的范围,没有做一些非常严重的(杀退),我们允许你灰度出去。
通过灰度出去,我们会做一些大规模的机型网络情况的验证。对于一些复杂情况,如果说一些非常异常的机型,这里会有分布图,我们会把我们的异常机型拿出来看一下,是不是对这个机型是一些普遍的现象。
这样通过我们灰度的机制加我们实时的反馈机制,可以在30分钟之内或者1个小时之内,可以拿到之前可能需要一天两天在实验室里面拿出来的数据,可能还不一定完整。
最后一点,技术的数据都是非常客观或者冰冷的数据,有时候我们还需要能够看到今天整个用户对整个产品的体验是怎么样的。
十、用户反馈体系实例
刚才讲到我们会在整个 APP 端进行很多的埋点的反馈布局,在用户操作一段时间之后,我们就会弹出来说今天你是不是要反馈一下,在整个后台上会实时打通我们所有的用户反馈体系。
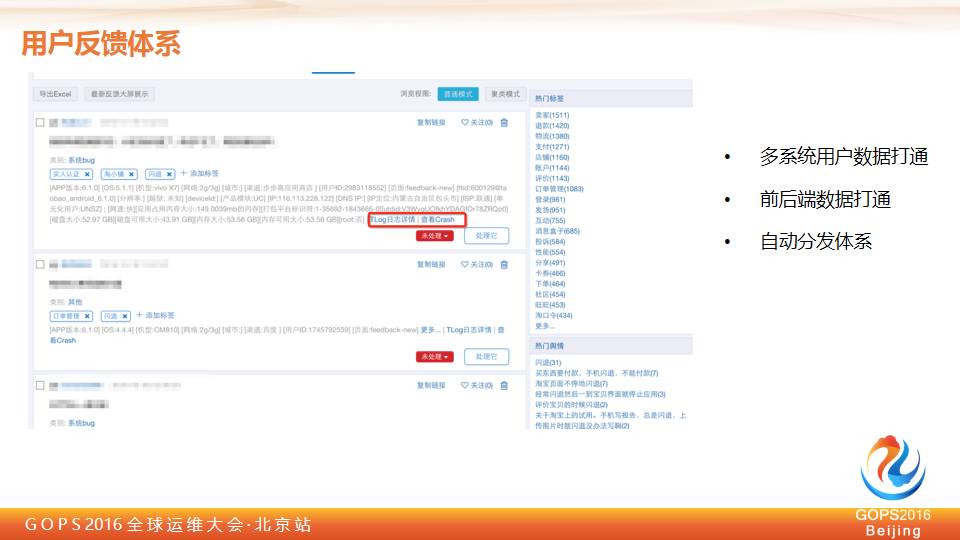
在这个反馈体系里会把用户当时所处的各种环境全部打下来,我们会把用户在舆情市场、新浪微博甚至在客户端反馈的所有舆情数据都能够实时抓取下来。
通过一些关键字的聚合,通过标签的分类,甚至通过一些语义的分析,自动能够产生各种类别,我们会把这些类别的信息自动推送给各个产品线的开发负责人、测试负责人甚至于产品负责人。
通过反馈的布点、自动化的语义分析以及报警,可以让所有的研发工程师、产品负责人,他在灰度完之后,半天时间之内能够快速观察他的产品对用户的体验的情况。
十一、远程日志体系的建设
刚才我们讲了很多今天我灰度出去之后突然来了一些数据,这些数据发现很多问题。
但是监控只是第一步,我发现问题说 APP 很卡,但很多时候不知道用户到底什么原因卡?肯定希望今天有个手段能够更加精确定位到用户到底什么原因卡。
在我们内部会有很多手段,简单讲两个手段。
1. 远程日志体系

我们会有一个远程日志体系,日志这一块大家在服务端可能都非常了解,所谓的日志,所谓的服务端的报警都是基于日志来做的,客户端日志大家可能很多没有感受过,因为客户端都是在手机上面,我们不可能让用户实时把整个日志传输上来。
在客户端上面我们自己做了一套高性能压缩的远程日志的方案,这个日志做什么事情,我们会在 APP 端对一些常见的操作,比如主要是做用户的网络流水、当时用户的网络情况甚至一些自己写的自定义协议的网络的调试信息。
这些日志我们会经过严格的加密以及压缩,在用户手机端上可能每天会有一个循环的日志产生,它可以存储下来一个用户在手机上操作的所有的日志情况。
不知道刚才大家看到整个用户反馈的时候有没有看到标红的东西,这里有所谓的 log 信息,在用户反馈的信息,比如他反馈打不开,我们自然会把这些日志信息全部带上来。
用个案例来讲,我们怎么利用这些日志快速定位到用户的问题,通过用户把这些日志循环的存储在整个手机端上,我们会有一种机制把这些日志存上来。
刚才大家看到今天反馈的同时自动带上来,我们称之为主动的方式,还有个被动的方式,我们会对用户推送上传信息,会把他的日志通过一个加密的通道上传到我们服务器端,通过自定义的方式展现出来。
这个基本上我们来做的是功能级别的定位,除了功能的问题之外还会有些性能的问题,性能问题可能会更复杂,因为你光看一个日志,你只能知道说这个功能是不是 OK,性能我可能需要得到信息会更多。
2. 远程性能 Trace 体系
所以在手机端上我们会简单实现一套所谓远程性能的Trace,大家如果做过性能测试,这个东西是开发工程师、运维工程师经常用的手段。
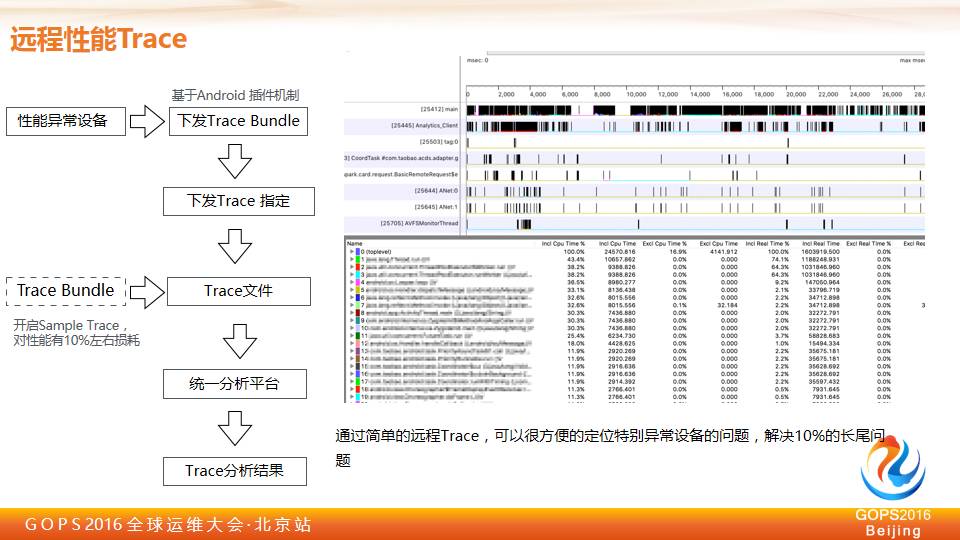
我们在客户端上怎么来做,我们可能自己在整个设备商会实现一套我们自定义的三波 Trace,但是这个 Trace 我们会基于整个客户端的插件机制,可能动态的下发给用户。
比如我们基于刚才看到的会有一个性能的日志情况,我们会抓取你最慢的几台机器,中间找一些用户,对这些用户我们内部称之为负面样本,就是它性能异常的设备。
对这些设备我们会下发一个 Trace Bundle,用户拿到这个 Trace Bundle 之后,我们会在用户手机上面开启三波 Trace,这三波Trace可能会对整个用户的性能会有10%的损耗。
采集完一次之后,Bundle 会自动把它下掉,会自动上传一个 Trace 信息到远程服务器上,我们会通过一个简单的远程 Trace,定位到今天他跟我们实验室的差别是什么,到底是哪个线程比较慢,是因为整个用户机器的问题还是说某种场景在我们开发环境、测试环境没有想到。
十二、主动日志上报体系
今天我们有这么多手段,除了今天我动态去拉之外,我们还希望有一些东西更加高效,我们其实会也一个上传的机制的体系设计。
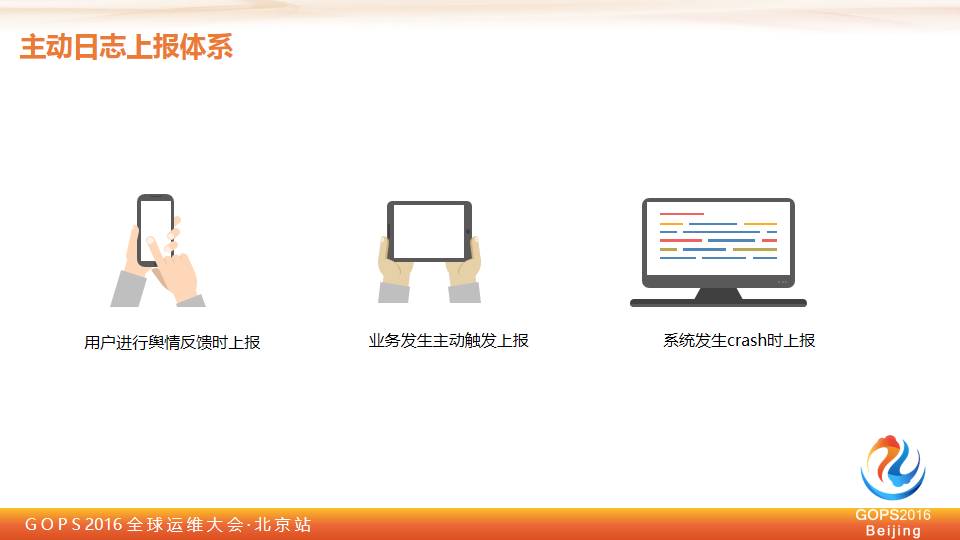
-
用户进行舆情反馈时上报
比如说用户在进行舆情反馈的时候,比如说打不开,为什么图片打不开,会自动触发我们的 Trace 抓取日志,我们会在远端配取一个自动抓取的关键词库,我们发现只要用户的反馈上面马上命中了我们这个关键词,会自动启动刚才所说的 Trace 体系,把用户所谓的日志体系随他的反馈同时带上来。
-
业务发生主动触发上报
我们现场经常会碰到一些问题,他打电话给客服说今天我这个东西下不了了,客服会要求说你上报一下信息过来。
-
系统发生Crash时上报
整个系统发生 Crash,或者说监控指标,大家都知道整个监控是基于大数据来做的。
但大数据只能告诉我们一个概要,我们还需要能看到更加细的东西,所以我们在内部会有一套机制,比如大数据上面我们会有个阈值,触达10%的用户,会在这10%的机器上去抽样,自动下发 Trace 信息过去,对这些信息自动上报我们的 Trace 信息过来。
十三、问题定位案例分析
简单讲几个案例,这几个案例可能是我们今年双十一之前经常碰到的一个问题,这个案例是双十一之前一个非常常见的问题,我们在整个灰度的过程中,突然发现用户反馈是说为什么我的评论我的图片不能展示,我不能评论了。
那个时候我们来看整个服务端、整个客户端都 ok,没有任何问题,我们就对整个用户下发了 Trace,右边可能是说今天 Trace 几分钟之后,用户当时的整个网络日志、网络情况,全部都要上报到整个服务器上。
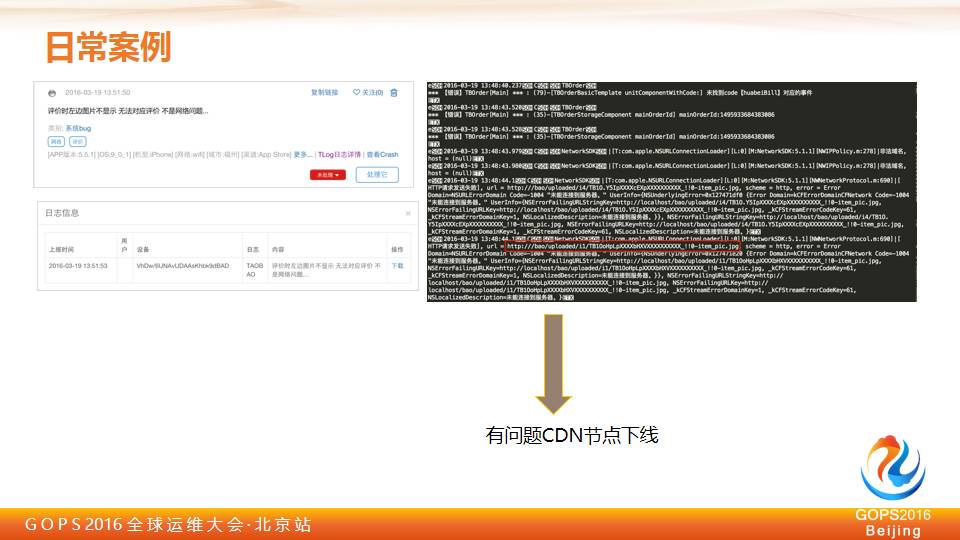
右边是经过我们解密过之后的整个服务器的流水信息,大家发现他去访问的一个 CDN 节点好像是有些问题,后来在这个日志去看,他访问了 UIO,报了一个404,我们拿过去一看,可能 CDN 节点有上千台甚至上万台机器,其中有一台机器有问题。
我们马上找到这个 CDN 节点,我们把它下掉。这个在以前的情况下,有些 CDN 节点可能监控上发现的没那么细,因为它整个百分比可能只有0.001%,但是得用户来讲,这个节点服务几十万用户,完全不能起作用了。
我们通过这个手段解决了很多之前所谓的 CDN 节点、网络节点上面的一些非常个例的问题。
这些东西其实对整个用户舆情是非常严重的,大家知道客户端上会有很不好的现象,用户如果用得好他不会来反馈,他用得差的时候,他会在所有的用户舆情、微博上进行产波,如果一不小心刚好一个大V碰到了,可能会引起公关事件。
通过这种手段你可以快速定位到一些大家之前认为基本上不可能会出现的小白问题。
十四、性能问题案例分析
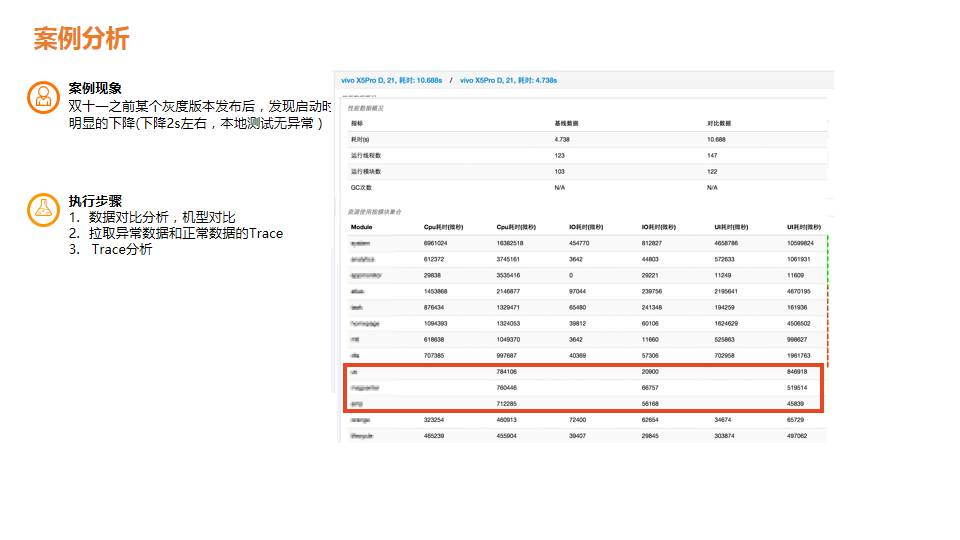
我们在双十一之前发了一个版本,我们突然发现某一个版本整个启动时间下降了2秒以内,但在实验室里怎么都发现不了。
这个时候做了一件事情,基于刚才的性能数据,我们对10%的数据下发了 Trace 异常数据,线上的正常用户我们也会拉一份 Trace 出来,异常用户也会拉一份 Trace 出来。
我们做了对比,左边是大家非常常见的火焰图的概念,我们把两份 Trace 进行了时间序列的拉平拟合之后,把这两份 Trace 做了一次拟合。红色的是两份 Trace,异常的样本 Trace 跟正常 Trace 差异超过10 毫秒以上,我们会对它进行标红。
看这个图就可以看出来,今天启动的时候,慢的那几个用户,他在某些 Trace 方法里多了很多。同时我们会对整个 Trace 的方法堆栈进行归类归总,因为所有的方法堆栈在我们内部都可以看出来是哪个模块发出来的。
对比之后大家会发现,正常的一个应用上发现某几个模块没有调用,但是在异常模块上多了这个调用,而且整个数量非常多,整个次数非常温和,一看时间刚好和异常时间是比较吻合的,原来是在某些场景下会触发一个我们之前从没有想过的流程,这个流程可能现在在线上概率还是比较高的。
知道原因之后,把这个问题解决掉就 ok 了。
十五、整体回顾
灰度也好,监控也好,Trace 也好,我们内部分类,其实整个东西可以分为好几块。





