前言
关于
前后端分离
,我的感觉其实也是:这么老土的话题,为什么还要拿出来老调重弹?
但越来越发现基于前后端分离的类RESTful架构,能很好的满足WebAPP的业务需求。尤其是WebAPP+NativeAPP产品为主的中小型公司,能让整个公司的服务端研发和部署更灵活。
PS:
已经了解前后端分离和koajs(不喜欢看背景和扯淡)同学可以直接跳到:“三、如何实践”。
一、什么是前后端分离?
前后端分离
的概念和优势在这里不再赘述,有兴趣的同学可以看各个前辈们一系列总结和讨论:
-
系列文章:前后端分离的思考与实践(1-6)
-
slider: 淘宝前后端分离实践
-
知乎提问:
尤其是《前后端分离的思考与实践》系列文章非常全面的阐述了前后端分离的意义和技术实现。如果不想看上面的文章,可以在脑海里留下这样一个轮廓就好:

本文主要阐述趣店团队基于Koajs的前后端分离实践方案。
二、为什么选择koa?
koa是由Express 原班人马打造的一个更小、更健壮、更富有表现力的 Web 框架。(koa官网需用梯子,中文文档可以参考郭宇大神的翻译:koa中文文档,这里也不详细介绍。)
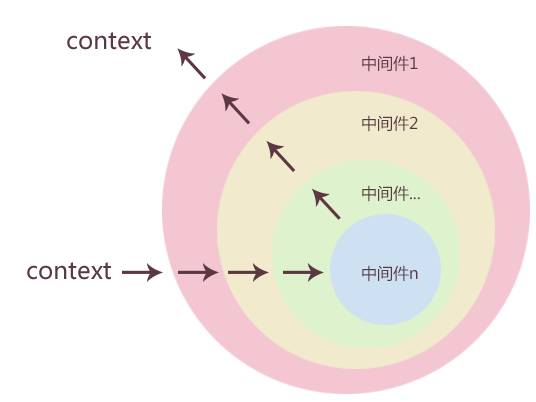
看到koa之后,简单看了下文档和源码,立刻感觉
koa不就是为前后端分离而诞生的轻量级框架吗?
因为:
-
如果要用koa实现一整套类似于PHP的Laravel或者Ruby on Rails的服务端MVC框架其实还有很长的路要走;
-
koa中间件的思路可以很好的被前后端分离的思路利用起来,比如:路由、模板引擎、数据代理等等;
-
koa基于ES6的generator特性(不了解generator的同学可以参考阮一峰老师的文章),利用co等模块让前端同学写一个路由再简单不过;
-
……
总之,koa给我的第一印象就是:如果用它来实现一套前后端分离的框架,非常
高效
、
轻量
、
易扩展
。
三、如何实践?
1、刀耕火种的年代
在谈如何实现基于koajs的前后端分离框架的之前,必须提一下在做分离之前趣店(原趣分期)的情况:
-
一个仓储托管了趣分期业务前后端所有代码,由于不断维护,这个仓储足足有
600M
;
-
后端为了满足NativeAPP的接口需求,
这个600M的仓储还包含了提供给客户端的代码
;
-
前后端开发流程为:
先由后端写一个路由 → 前端将这个路由写成可以交互的页面 → 前端提交代码后后端同学“套模板”填充数据
;
-
前后端开发都在一台远程开发机上,通过samba隐射到本地进行开发;
-
前端几乎没有做任何打包编译;有时候为了偷懒,甚至把CSS和JS直接以内嵌的方式写在模板里(不要去联想vue,两码事儿)
写到这儿想贴代码来着,想想还是算了……
2、基于koa的实现
无论使用什么工具要实现前后端分离框架,无非要满足这样几点:
-
更便捷地创建路由
-
更高效地代理数据请求
-
更灵活地环境部署
先看一个已经实现了demo应用的目录结构:
.
└── demo
├── controller
│ ├── data.js
│ ├── defaultCtrl.js
│ └── home.js
├── static
│ ├── css
│ ├── image
│ └── js
└── views
└── home.html
这个结构大家再熟悉不过:
controller
提供路由;
static
包含静态文件;
views
提供模板文件。
这里可能大家会有疑问,如果我的前端构建是components的模式怎么办呢?
├──components_a
│ ├── home.js
│ ├── home.css
│ └── home.html
├──components_b
...
没关系,do what u want!很多boilerplate可以直接拿到这个框架下直接使用,我们团队自己也正在使用了requirejs和vue的构建方案。
1. 更便捷地创建路由:controller
回到上文提到的案例:
controller
├── data.js
└── home.js
这段代码生成的是一个
/data/*
,
/home/*
路由,用过Express的同学对这种路由实现肯定一点都不陌生。
但有一点不一样的是,koa下面每一个路由是一个独立的generator函数(很遗憾,generator函数不能使用箭头函数的语法来表示),参看
controller/home.js
:
exports.index = function* () {
yield this.bindDefault();
yield this.render('home', {
title: 'Hello , Grace!'
});
}
你还可以用一个对象把一个controller包起来,,参看
controller/data.js
:
exports.info = {
repo: function*(){
yield this.proxy('github:repos/xiongwilee/koa-grace')
}
}
这种写法非常适用于仅仅用来做一个数据代理的ajax请求的控制器。当然,如果需要的话,你还可以在控制器里对数据做一些加工。
另外,还有几个细节与express的路由控制器不太一样:
-
终止请求的动作都有koa来完成,在这里的controller里,你不需要通过
res.end()
来终止请求;
-
这里的controller的作用域,就是koa的上下文,所以你可以通过
this.req
获取request对象;
-
这里的controller里,异步回调的语法成为了往事,请尽情的使用
yield
。
我们对现在的路由方式做了一个压测:8核CPU/8G内存的机器,通过一个路由返回
hello world!
,结果显示:
8核CPU/8G至少能扛住1000QPS
的压力(cpu idle不到60%,cpu load接近8)。
2. 更高效地代理数据请求:proxy
前后端分离模式下的,数据代理主要有这两种使命:
第一种场景,比如:一个用户中心的页面,需要展示用户的用户信息、订单列表、喜欢的商品推荐等等信息。由于后端的架构,用户、订单、商品可能都是属于不同的服务,这就意味着,后端同学需要给你同时拼装这么多数据,拼装还有可能是同步获取每个接口然后再一起返回给前端。
现在,就可以尽情的发挥
nodejs异步并发及koa的generator同步语法
的优势,我们还可以这么写:
repo: function*(){
yield this.proxy({
data1:'github:repos/xiongwilee/data1',
data2:'github:repos/xiongwilee/data2',
data3:'github:repos/xiongwilee/data3'
})
}
koa会
自动并发请求所有接口
,然后将结果返回给你,然后可以在上下文的
backData
中获取结果集。
另外一种场景,比如用户需要上传一张图片或者提交一篇文章,你也可以这样写:
submit: function*(){
yield this.proxy('http://test.com/submit')
}
不用做任何配置,koa会直接把request数据buffer直接通过管道pipe给后端接口。
值得一提的是:
最后,我们也做了一个压测:8核CPU/8G内存的机器,通过一个路由将请求代理到另外一个接口,结果显示:
8核CPU/8G至少能扛住300QPS
的压力,这个结果比纯路由的压测情况要低很多,值得注意。
不过有意思的一点是,我们压测发现:
proxy的性能与接口响应时间无关,与接口响应content大小有密切关系:接口响应内容越大,proxy性能越差
。
3. 更灵活地环境部署
基于koa可以实现各类有意思的中间件。比如:可以拦截请求计算请求总耗时中间件、可以匹配路径实现本地的静态文件服务器、可以不需要再另开server实现一个mock数据的功能……
a) 开发环境
上文提到过一个DEMO的文件目录,具体在开发环境和生产环境中整体目录结构中其实是这样的:
├── app // 开发模式下应用模块目录
│ ├── blog
│ └── demo
├── cli // 配套命令行工具
│ ├── bin
│ ├── lib
│ └── package.json
├── log // 日志目录
└── server // 服务器目录
├── app // 实际服务端引用的模块目录
│ ├── blog
│ └── demo
├── bin
├── config
├── src
└── package.json
在开发环境下,你可以将
./app










