岳良, 携程信息安全部高级安全工程师。2015年加入携程,主要负责渗透测试,安全评审,安全产品设计。
在web应用攻击检测的发展历史中,到目前为止,基本是依赖于规则的黑名单检测机制,无论是web应用防火墙或ids等等,主要依赖于检测引擎内置的正则,进行报文的匹配。虽说能够抵御绝大部分的攻击,但我们认为其存在以下几个问题:
1. 规则库维护困难,人员交接工作,甚至时间一长,原作者都很难理解当初写的规则,一旦有误报发生,上线修改都很困难。
2. 规则写的太宽泛易误杀,写的太细易绕过。
例如一条检测sql注入的正则语句如下:
Stringinj_str = "'|and|exec|insert|select|delete|update|count|*|%|chr|mid|master|truncate|char|declare|;|or|-|+|,";
一条正常的评论,“我在selected买的衬衫脏了”,遭到误杀。
3. 正则引擎严重影响性能,尤其是正则条数过多时,比如我们之前就遇到kafka中待检测流量严重堆积的现象。
那么该如何解决以上问题呢?尤其在大型互联网公司,如何在海量请求中又快又准地识别出恶意攻击请求,成为摆在我们面前的一道难题。
近来机器学习在信息安全方面的应用引起了人们的大量关注,我们认为信息安全领域任何需要对数据进行处理,做出分析预测的地方都可以用到机器学习。本文将介绍携程信息安全部在web攻击识别方面的机器学习实践之路。
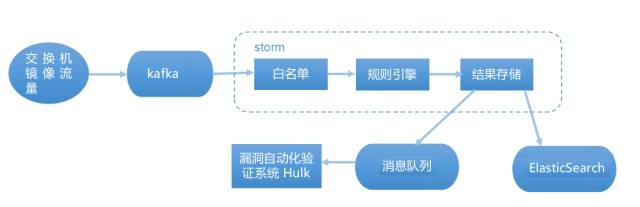
图1: 携程nile 攻击检测系统架构第一版
首先我们简单介绍一下携程攻击检测系统nile的最初架构,如上图1所示,我们在流量进入规则引擎(这里指正则匹配引擎)之前,先用白名单过滤掉大于97%的正常流量(我们认为如http://ctrip.com/flight?Search?key=value,只要value参数值里面没有英文标点和控制字符的都是“正常流量”,另外还有携程的出口ip流量等等)。
剩下的3%流量过正则规则引擎,如果结果为黑(恶意攻击),就会发到漏洞自动化验证系统hulk(hulk介绍可以参考https://zhuanlan.zhihu.com/p/28115732),例如调用sqlmap去重放流量,复验攻击者能否真的攻击成功。
目前nile系统我们改进到了第五版,架构如下图2,其中最重要的改变是在规则引擎之前加入了spark机器学习引擎,目前使用的是spark mllib库来建模和预测。如果机器学习引擎为黑,则会继续抛给正则规则引擎做二次检查,若复验依然为黑,则会抛给hulk漏洞验证系统。

图2:携程nile 攻击检测系统架构最新版
这么做带来了以下好处:
1. 机器学习的处理速度比较快,能够过滤掉大部分流量再扔给正则引擎。解决了过去正则导致kafka堆积严重的问题(即使是原始流量中的3%也存在此问题)。
2. 可以对比正则引擎和机器学习引擎的结果,互相查缺补漏。例如我们可以发现正则的漏报或误报,手工修改或补充已有的正则库。若是机器学习误报,白流量识别为黑,首先想到的是否黑样本不纯,另外就是特征提取有问题。
3. 如果机器学习漏报,那怎么办呢?按图2的流程我们根本不知道我们漏报了哪些。最直接的想法就是并列机器学习引擎和正则引擎,来查缺补漏,但这样违背了我们追求效率的前提。
最近的一个版本我们加入了动态ip黑名单,时间窗口内多次命中的的高风险ip重点关注,直接忽略storm白名单。在实践中,我们借鉴了此部分黑ip的流量来补充我们的学习样本(黑ip的流量99%以上都是攻击流量),我们发现了referer,ua注入等,其他还发现了其他逻辑攻击的痕迹,比如订单遍历等等。
有人可能会问,根据上面的架构,如果对方拿新流出的攻击poc来攻击你,只攻击1次,那不是检测不出来了么?首先如果poc中还是有很多的特殊英文标点和敏感单词的话,我们还是能检测出来的;另一种情况如果真的漏了,那怎么办,这时候只能人肉写新的正则加入检测逻辑中,如图2中我们加入了“规则引擎(新上规则)”直接进行检测,经过不断的打标签吐到es日志,新型攻击的日志又可以作为学习用的黑样本了,如此循环。
加入机器学习前后的效果对比:kafka消费流量:1万/分钟->400万+,白名单之后的检测量:1万/分钟->10万+。
我们设置了一分钟一个批次消费,每分钟有10万+数据从storm过来,只花了10秒钟左右处理完,所以如果我们缩短消费批次窗口,理论上还可以提高5-6倍的吞吐,如下图3。

图3:新架构下storm处理速度
我们先看一个机器学习的识别结果,如下图4:

图4:机器学习es记录日志
rule_result标签是正则的识别结果,由于当时我们没有添加struts2攻击的正则,但是由ES日志结果可知,机器学习引擎依然检测出了攻击。
介绍了完了架构,回归机器学习本身,下面将介绍如何建立一个web攻击检测的机器学习模型。而一般来讲,应用机器学习解决实际问题分为以下4个步骤:
定义目标问题
收集数据和特征工程
训练模型和评估模型效果
线上应用和持续优化
核心的目标问题:
1. 二分类问题,预测流量是攻击或者正常
2. 漏报率必须<10%以上(在这里,我们认为漏报比误报问题更严重,误报我们还可以通过第二层的正则引擎去纠正)
3. 模型预测速度必须快,例如knn最近邻这种带排序的算法被我们剔除在外
机器学习应用于信息安全领域,第一道难关就是标签数据的缺乏,得益于我们的ES日志中已有正则打上标签的真实生产流量,所以这里我们决定使用基于监督学习的二分类来建模。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。当然也有人提出过无监督的思路,建立正常流量模型,不符合模型的都识别为恶意,比如使用聚类分析,本文不做进一步讨论。
没有一个机器学习模型可以解决所有的问题, 我们可以借鉴前人的经验,比如贝叶斯适用垃圾邮件识别,HMM适用语音识别。具体的算法对比可参考https://s3-us-west-2.amazonaws.com/mlsurveys/54.pdf
明确了我们需要达到的目标,下面开始考虑“收集数据和特征工程 ”,也是我们认为模型成败最关键的一步。
我们写段脚本,分别按天分时间段取ES黑白数据,并将其分开存储,再加上自研waf的告警日志,以及网上收集的poc,至此我们的训练原始材料准备好了 。另外特别需要注意的是:get请求和post请求我们分开提取特征,分开建模,至于为什么请读者自行思考。
一开始本地实验时,我是选用的python的sklearn库,训练样本黑白数据分别为10w+条数据,达到1比1的平衡占比。项目上线的时候,我们采用的是spark mllib来做的。本文为了介绍方便,还是以python+sklean来进行介绍。
再来聊聊“特征工程”。我们认为“特征工程”是机器模型中最重要的一部分,其更像是一门艺术,往往依赖于专家的“直觉”和专业领域经验,更甚者有人调侃机器学习其实就是特征工程。你能相信一个从来不看NBA的人建模出来的NBA总决赛预测结果模型么?
限于篇幅,这里主要介绍我们认为项目中比较重要的“特征工程”的步骤:
核心需求:从训练数据中提取哪些有效信息,需要这些信息如何组织?
我们观察一下ES日志中攻击语句和正常语句的区别,如下:
攻击语句:flights.ctrip.com/Process/checkinseat/index?tpl_content=&name=test404.php&dir=index/../../../..¤t_dir=tpl
正常语句:flights.ctrip.com/Process/checkinseat/index?tpl_content=hello,world!
明显我们看到攻击语句里面最明显的特征是,含有eval, ../等字符、标点,而正常语句我们看到含有英文逗号,感叹号等等,所以我们可以将例如eval的个数列出来作为一个特征维度。在实际处理中我们忽略了uri,只取value参数中的值来提特征。比如上面的2条语句flights.ctrip.com/Process/checkinseat/index?tpl_content部分都被我们忽略了。
转自:携程技术中心
完整内容请点击“阅读原文”







