从0诞生

2013年初,京东商城研发布局虚拟化技术方向。那时的我们从0起步。从几人小团队开始起航。
在物理机时代,应用上线等待分配物理机时间平均在一周。应用混部要看脸看颜值的,没有隔离的应用混部如履薄冰,所以在物理机时代混部的比例平均每台物理机低于9个不同应用的Tomcat实例。
从痛点入手可以极大提升新项目的落地实践机会。即刻我们着手规划京东虚拟化平台项目。从痛点以及当时2013-2014年的技术氛围可以容易想到,京东是从OpenStack开始,那个时代OpenStack研发人员炙手可热就像今天深度学习人才一样。京东强大的人才自培养传统发挥作用,在6个月内,就组建了一支14人的研发团队,并迅速掌握了OpenStack的核心代码。
OpenStack对VM支持是天生的最好,所以接入第一个核心业务,就发现了问题。业务是一个并发量非常大又对延迟要求40ms以内的0级系统,我们对VM做了所有我们能知道的优化,依然无法达到预期,一直徘徊在60ms左右,但从VM切到物理机上运行性能稳稳的在40ms以内,期间动用了多种性能定位工具,如SystemTap等。 在那2周只有黑夜和香烟的日子里面是漫无目的的郁闷,团队骨干已经杀红了眼做各种try。结果是残酷的,核心系统研发同事安慰着:兄弟,我们等你。在整个2013年夏到2014年夏,退而求其次支撑了几百个非核心系统运行在KVM环境。在团队看来这是一个不小的挫折和压力。这一年是郁闷是压力也是积攒经验;这一年团队对京东业务有了极其深刻的了解,在OpenStack的掌控能力已经到了极高的段位并在此期间代表京东主导了OpenStack几个BP研发。
时光来到2014年秋,公司安排研发首席架构师刘海锋带领虚拟化团队,首席架构师带来新的启发和规划。团队重新出发,新的方案,新的思路。Docker进入我们的视野,那时候Docker非常单薄,单薄到只有镜像和对CGroup简便的操作等功能是可用之外,其他基本是无法生产环境使用的。稍加改造做了基本性能测试,tp99可以有部分降低到40ms范围,这就是曙光。虽然还不完美,只是部分请求可以满足40ms要求,但是这就是未来。
虽然有了Docker,拿什么来管理数以万计的Docker容器实例。14年秋,没有Kubernetes,没有Swarm,没有……通过2013——2014推广KVM所了解的业务,不难发现,直接彻底按容器的方式太过脱离业务研发的现状。作为最底层的计算层,稳定性,可靠性等质量要求极高,质量承诺坚如磐石。如果自研一套容器集群管理平台,时间是最大的成本,并且团队积累的openstack经验。最终团队选择OpenStack + Docker的架构,并定义为京东第一代容器引擎平台 JDOS 1.0(JD DataCenter OS)。后面的故事京东研发同事基本是知晓。
基础平台部推出的京东第一代容器引擎平台推广速度极快,从15年的起步到到16年618完成100%应用运行环境容器化。
研发上线申请计算资源由之前的一周缩短到分钟级,不管是1台容器还是1千台容器,在京东IDC经过计算资源池化后随时不限量秒级供应。京东第一代容器引擎强隔离特点,解决了研发同事再也不用靠颜值来争取和别的业务混合部署了。所有的研发同事从部署艰难选择求合体中解放出来,0级系统不再有vip待遇,应用不分0级和非0级,是否混部完全依靠京东第一代容器引擎平台通过算法预测和部署之后动态调度。
平均部署应用密度提升3倍,近似可以认为物理机使用率提升3倍,带来极大的经济收益。在容器化过程中,我们创造的容器新世界有效借力了京东已经运行了多年的多个稳定系统,包括数据库,缓存JIMDB,JMQ,服务框架JSF等。在容器化之前,基础设施以物理机为主。因此,京东容器落地的第一件主要工作是基础设施容器化,同时在应用的运维方面,兼用了之前的配套系统。
当我们向研发同事讲述什么是容器的时候,常常用虚拟机作类比。在给用户进行普及的时候,我们可以告诉他,容器是一种轻量级的虚拟机。但是在真正的落地实践的时候,我们要让用户明白这是容器,而不是虚拟机。这两者是有本质的区别的。虚拟机的本质上是模拟。通过模拟物理机上的硬件,向用户提供资源。容器的基石是经过隔离与限制的Linux进程。容器提供的是性能损失更小的原生物理机的计算能力,容器之间唯一共享的是Linux内核。
成长之痛
京东第一代容器引擎(JDOS)1.0版本从2015年开始部署,并在10月份陆续将部分业务迁移到弹性云平台。第一批业务包括核心和非核心系统如单品页,图片处理,订单等。
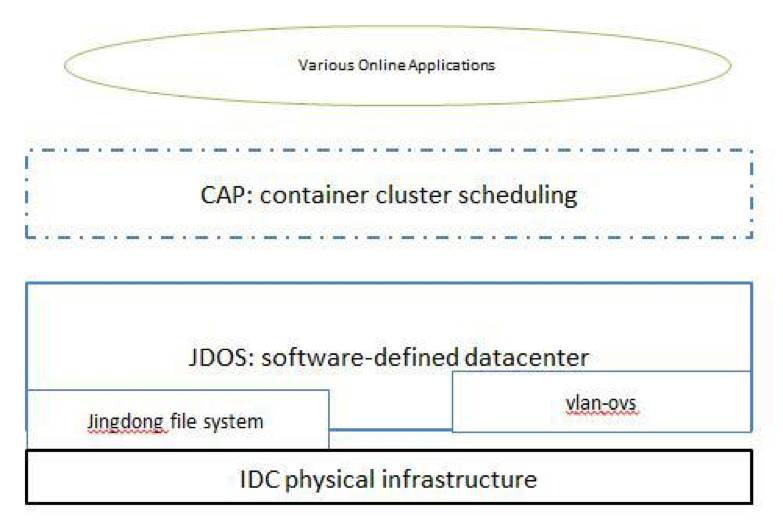
JDOS1.0架构
京东第一代容器引擎基于OpenStack Icehouse + Docker 1.3 + OVS 2.1.3架构简单,可靠。但随着集群规模越来越大,痛就开始显现:
OpenStack集群规模受限
很快OpenStack就遇到集群规模的问题,发生严重的不可靠问题;如:创建容器消息在MQ传输过程丢失,容器状态挂起,DB连接数过大,计算节点各种Agent定时任务hang,部署升级无法核对升级结果。
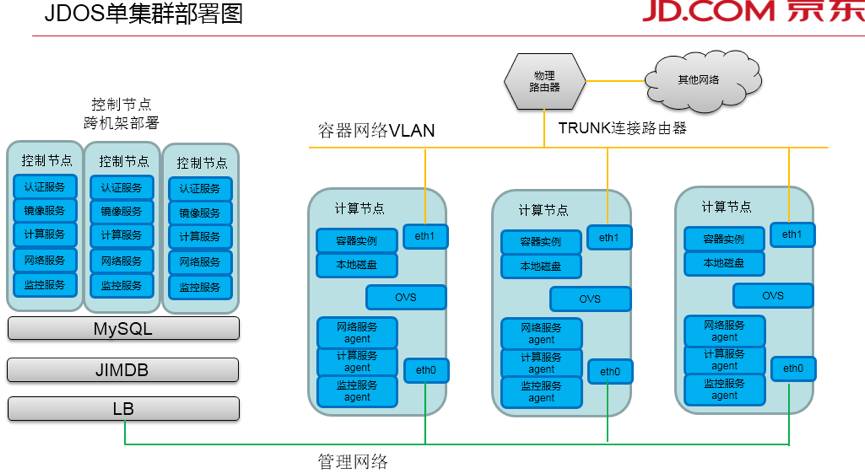
京东基础平台部团队在OpenStack领域已经深入遨游许久,社区暂时没有遇到这么大规模,那研发团队只能自己动手创造了。如上图,设计目标单个集群1万台物理节点,对的,单个OpenStack集群管理1万台物理计算节点。首先改造的是MQ,原理也简单,自己实现一个Python版本的RPC(brood),解除对MQ依赖。特别是依赖MQ操作DB的全部替代使用京东自研的Python版本RPC框架,对数据库的全部操作均使用RPC自带支持的京东JIMDB(内存缓存集群)。这样计算节点的定时任务无需直接update数据库,支持透明通过京东的RPC update到JIMDB。
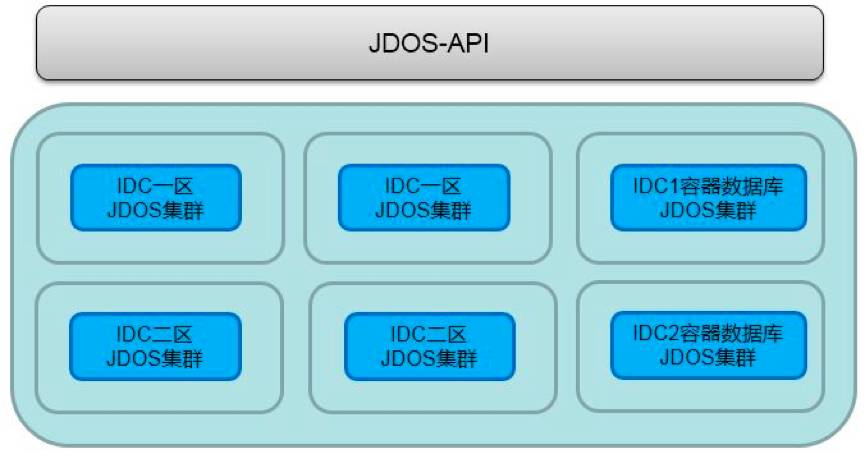
我们采用多IDC部署方式,使用同一的全局API开放对接到上线系统。支撑业务跨IDC部署。
可运维性挑战
单个OpenStack集群京东最大是1万台物理计算节点,最小是4K台计算节点。京东容器化战略是非常彻底的,应用运行环境100%全部容器化。这么多物理机和容器,运维是一个非常有意思的挑战。在研发京东第一代容器引擎之初,即定下来一个特点可运维性,所以目前运维这几万台物理机和几十万容器的运维工程师共2人,把日常运维工作系统归类。
京东第一代容器引擎扩容,一套基于Chef的自动部署,在大促前集中上线扩容时候核算过,从机器上架加电完后开始计算到新的节点加入集群资源池可用的效率是 4千台物理节点/天/每人。
物理机硬件故障,值得一提的是京东统一监控平台也是基础平台部设计研发推出。全新设计,跨IDC,基于容器部署,监控效率高效,故障信息自动收敛。特别是对硬件故障的感知特别靠谱,网卡CRC错误,内核信息关于硬件故障,ILO口获得的硬件状态等途径,还特别与机器学习Team合作,对硬件故障智能预测,特别对磁盘故障预测收获极大。这些信息都会自动通知到机房现场IDC同事进行处理,并自动通知受影响业务方,并预测给出恢复时间。
新一代容器引擎平台自身故障,设计之初所有组件都是无状态,停止新一代容器引擎的组件,不影响已经正在运行容器的正常运行提供服务。
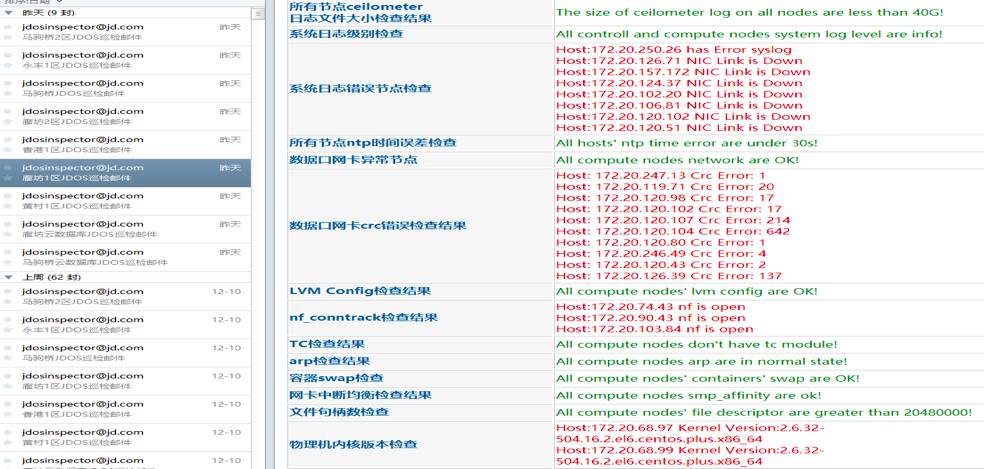
每日X光检查所有集群。从物理机,OS,OpenStack,依赖的组件,内核日志,进程,京东第一代容器引擎的一切都检查一遍。
性能&稳定性是最致命的
规模大之后,遇到很多低概率但是实实在在发生了性能和稳定性问题;如MAC表满导致无法网络通信,UDP大报文硬塞,丢包,中断异常,系统Slab集中回收性内存申请锁住时间过长;很快我们意识到原来做容器其实是在做Linux Kernel,一切性能和稳定性问题都回归到最根本的点—Linux Kernel。
即刻组建了Linux Kernel团队,当然最应该感谢的是京东所有研发同事,在大家的包容与呵护下,京东第一代容器引擎才有机会不断实践不断改进。特别是组建Linux Kernel团队之前,很多性能&稳定性问题,虽然解决但是并不能知其所以然。作为京东所有业务运行依赖之基石,不之所以然是非常不踏实的。任何性能瓶颈,稳定性现象,一定能找到那段代码,做到知其所以然。
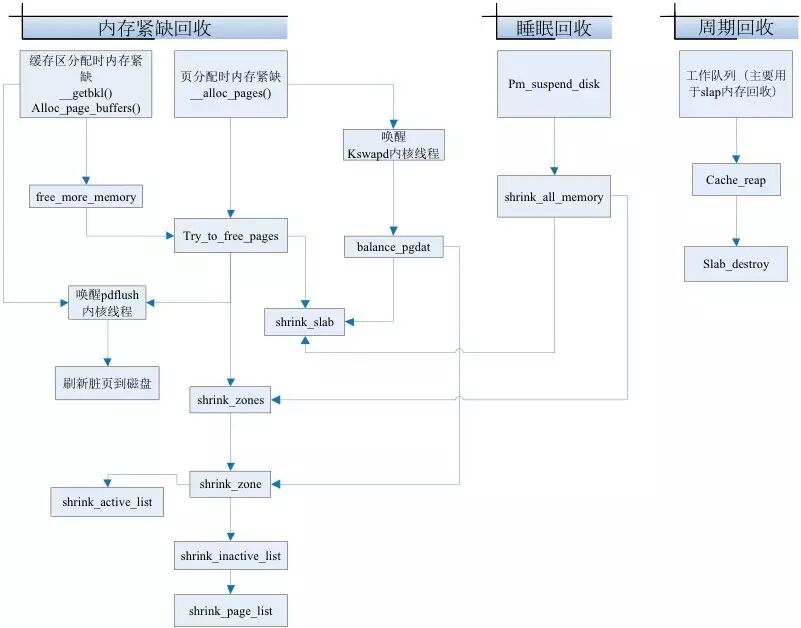
该图是京东一个优化Slab回收策略和机制原理。大家知道容器虽然隔离了CPU,内存,各种IO,但是依然是一个内核,内核要做内存回收是统一的策略,类比到很多的资源。京东Linux Kernel团队一条一条梳理,一点一滴建设,调优,最终维护京东Linux Kernel分支。踏实感油然而生。
至此,基础平台部完成了京东第一代容器引擎的研发&推广&运营。
快速发展
——15万容器助力16年京东618大促
经过近两年的运营,容器集群团队的技术能力也得到了业务研发团队的普遍认可。京东已经将所有业务迁移到容器集群平台中,并且第一代容器引擎平台也顺利保障了本年度618和双11大促活动。
当下,我们生产环境中的容器数量已超过15万,我们不知道这个规模是不是全球最大的,但能肯定的是,这应该是国内容器规模最大的。越努力,越上进。第一代容器引擎平台收获的不仅仅是成功上线和运营,更大的收获是研发同事对容器技术的认可和信任。
在第一代容器引擎正直壮年时候,团队又接受新的挑战,把京东数据库迁移到容器环境上,把京东实时计算Storm,Spark集群迁移到容器环境上。在团队内部,京东数据库容器化叫CDS,同样解决2个痛点,物理机资源利用率和申请DB速度。JDOS 1.0解决这2个痛点,做的非常好。只是做了2方面改进,即可直接支持:
项目很快上线,也很快见到成果收益。数据库实例创建时间缩短到现在的1分钟,机器资源利用率提升5倍。到16年双11期间,70%的DB实例运行在容器环境上。
当下,实时计算平台,上容器平台是水到渠成的事,资源弹性伸缩的便利性,是最大的吸引。目前第一代容器集群运行的最大Storm集群是1K容器实例,充分的容器资源伸缩,镜像发布,极大方便实时计算平台的对部署和资源的诉求。
回望——不忘初心
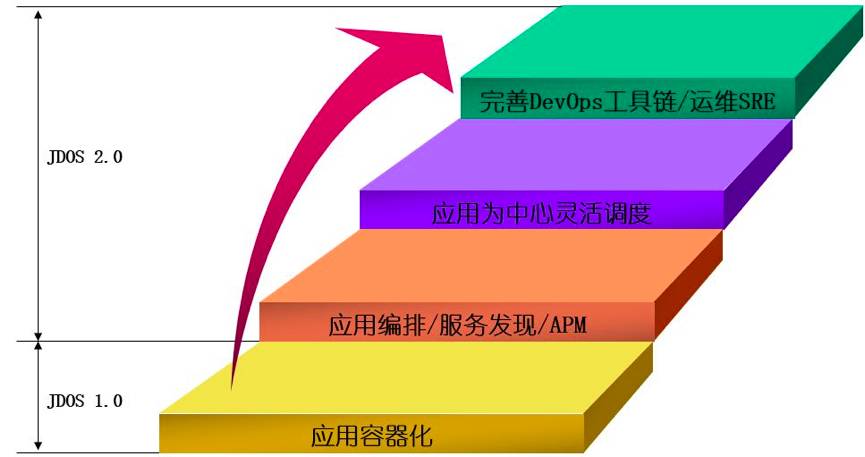
在完成的第一代容器引擎落地实践中,我们更多的是使用IaaS的思维,管理VM的方式来管理容器。
这种方式有利于业务的转变,从物理机和虚拟机上直接迁移到云上来。但是弊端在于,我们是一种“重”型的思维,因此JDOS 1.0是一个基础设施层而不是应用平台。私有云的弹性更多的是空壳容器的弹性伸缩,并没有真正意义上的应用的伸缩。但是京东第一代容器引擎的实践是非常有意义的,其意义在于把业务迁到了容器中,已经尽可能的踩过了应用容器化的坑,容器的网络、存储都逐渐磨合成熟。而这些都为我们后面基于1.0的经验,开发一个全新的应用平台打下了坚实的基础。
不畏将来,不念过往,我们的征途是星辰大海。当JDOS 1.0从一千、两千的容器规模,逐渐增长到六万、十万的规模时,基础平台部已经启动新一代容器引擎平台研发。这次我们的目标不仅仅是一个基础设施的管理平台,更是一个直面应用的容器平台,整合了1.0的存储、网络,打通从源码到镜像,再到上线部署的CI/CD全流程,提供从日志、监控、排障,终端,编排等一站式的功能。
让研发同事专注产品快速交付,让运维同事专注于系统线上高质量运行;京东新一代容器引擎平台已经上线,并在快速推广阶段。
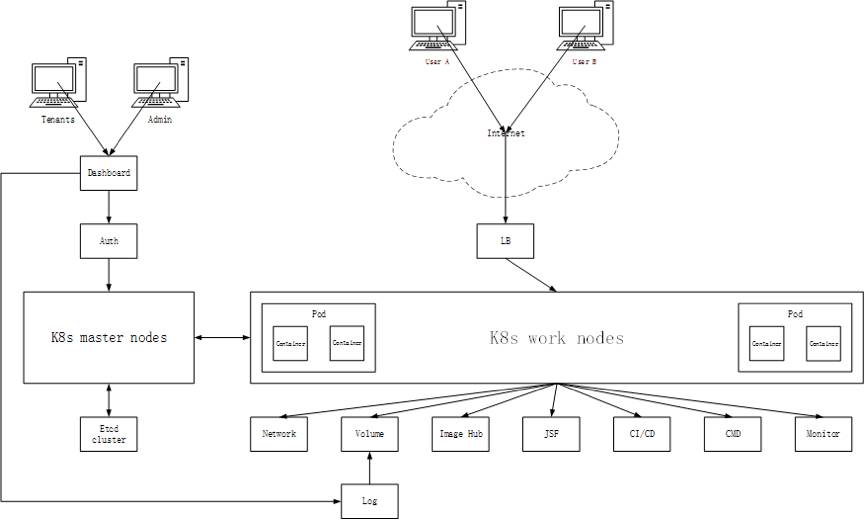
新一代容器引擎项目在原1.0基础上,支持应用研发上线全流程:应用构建、镜像仓库、配置中心、应用上线、运维、监控、日志、排障等。
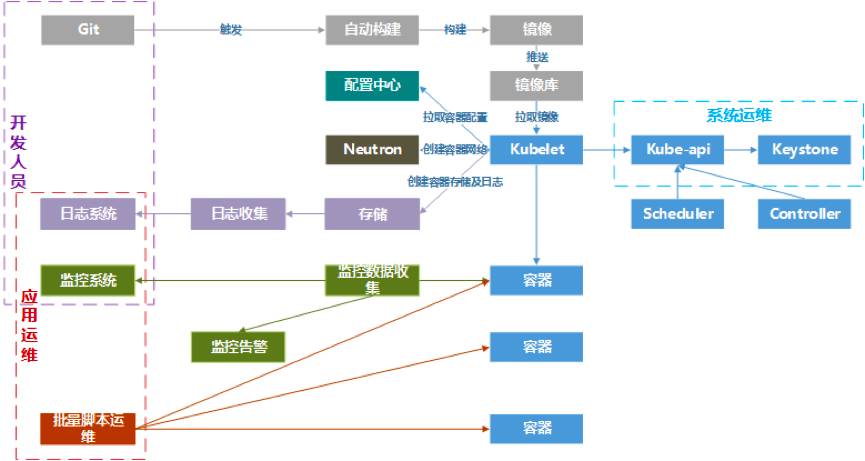
新一代容器引擎项目架构
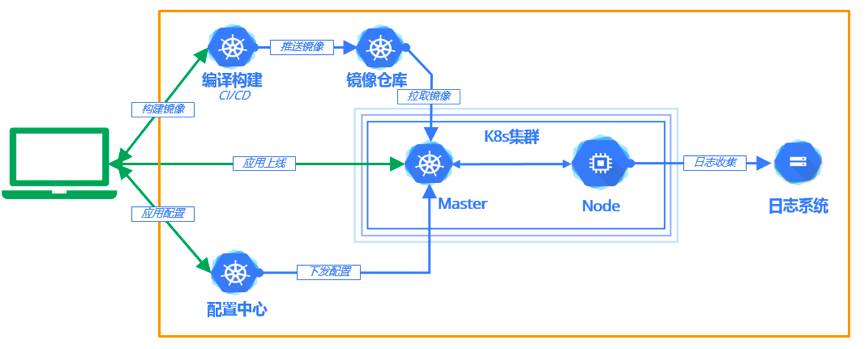
版本预发布
新一代容器引擎平台目标体现在:
调度数据中心全部计算资源;
不仅仅线上生产环境的资源调度,还希望可以把整个数据中心的全部资源都统一调度,包括测试环境,预发环境,借助京东第一代容器引擎在虚拟化网络的积累和优势,有信心在确保网络隔离安全情况下,在大促期间借助测试环境,预发环境的计算能力一起为大促贡献计算能力。
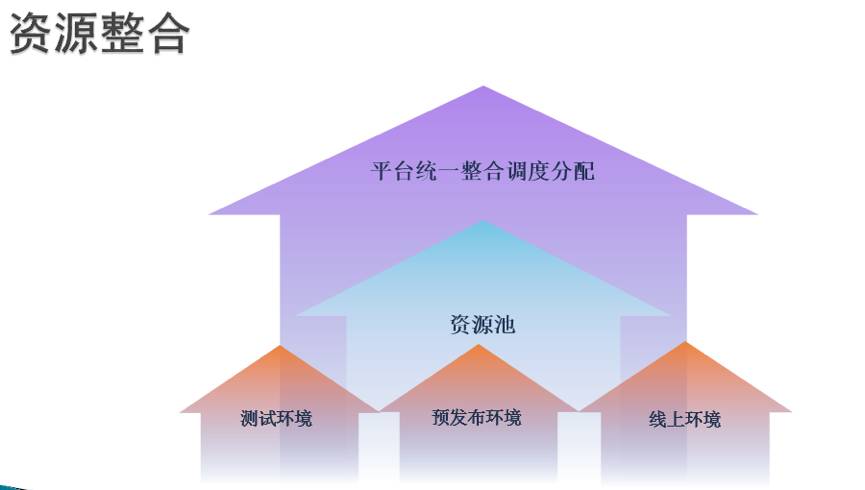
开发者一站式解决平台
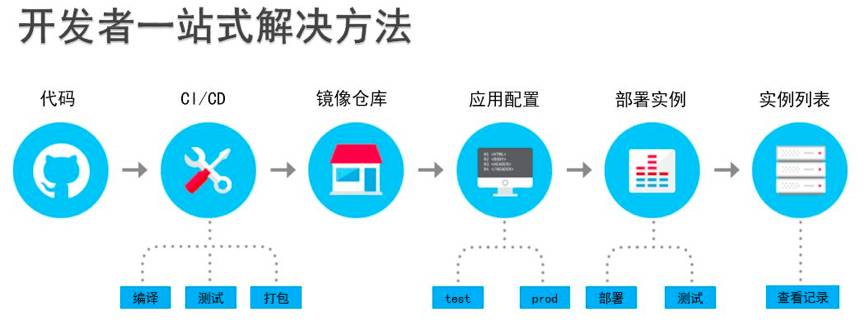
应用广泛
不仅仅应用,数据库,实时计算。我们还计划支持离线计算,深度学习,中间件等系统,做数据中心计算的统一载体。
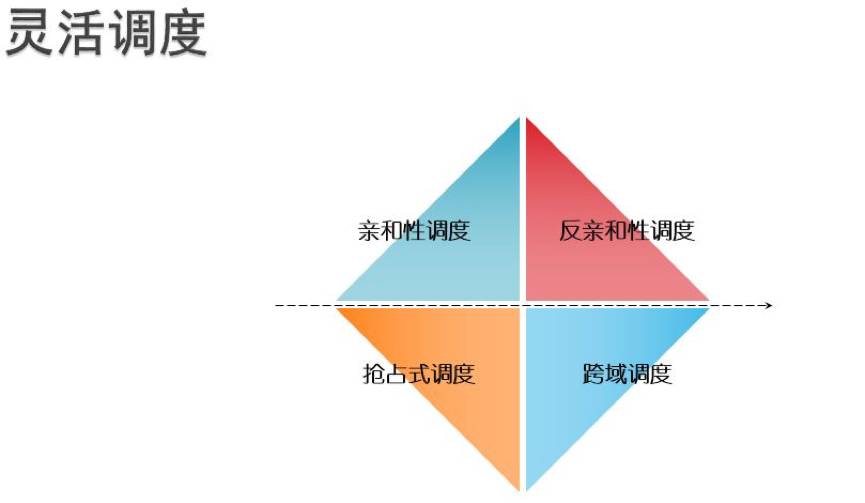
灵活调度
特别是抢占式调度,有效支撑离线大数据计算任务,深度学习算法训练。基于第一代容器引擎带来的业务100%容器化的红利,新一代容器引擎从调度IaaS资源提升到调度应用业务为中心。
星辰大海
新一代容器引擎平台研发已经完成,正在紧张的推广阶段。
京东第一代容器引擎借助OpenStack和Docker社区的力量快速上线&演进,打磨。京东新一代容器引擎基于Kubernetes、Docker、OVS等等开源社区项目,京东研发经过一线大规模实践的检验,目前是一个非常好的时机与社区互动,贡献社区。京东CNCF-JD在社区贡献top30,希望可以继续多多与社区互动。把京东一线大规模实践的经验与社区分享,并主动开源一批生产环境正在使用的项目:
Hades;分布式智能DNS,基于DPDK对UDP加速能力,实现一个性能极高的DNS服务
Cane;Kubernetes网络项目集中了京东在两代容器引擎平台上高性能网络经验
JNX;京东维护的nginx分支,特别加强适应容器集群平衡切换功能,以及防刷模块
JLK;京东维护的Linux kernel分支,在大规模容器实践过程对内核的心得和改进
MDC;京东统一监控平台,适应应用Cloud Native设计注重告警聚合&收敛,集中了高效运维所需的功能支持
Spider;京东东西向无阻塞网络,有效支持分布式系统在容器运行运行
本文转载自公众号:IPD-Chat,该公众号为京东商城基础平台部门官方公众号,会对基础平台目前的技术实践方案、最新项目动态等进行分享,纯技术干货,共同寻求突破~欢迎大家多多关注、共同交流!。
【基于Docker的DevOps实战培训 | 南京站】培训内容涉及容器编排框架(应用部署)、Ansible 简介、持续集成常用方式、典型案例分析、容器的选择、架构设计(百万级日活,亿级API 请求)、数据系统构建、持续集成的开发流程等,点击下面图片即可查看具体培训内容。

点击阅读原文链接可直接报名。





