深圳 - 腾讯大数据已在Github上推出面向机器学习的第三代高性能计算平台Angel的代码。
去年 12 月腾讯大数据在 KDD China 技术峰会上宣布准备开源,经过半年的准备后,正式开源代码:https://github.com/Tencent/angel。
Angel 是一个基于参数服务器(Parameter Server)理念的机器学习框架,它能让机器学习算法轻松运行于高维度模型之上。
Angel 的核心设计理念围绕模型。它将高维度的大模型,合理切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数,以及多变的同步协议,轻松实现各种高效的机器学习算法。
Angel 由 Java 和 Scala 开发,基于 Yarn 调度运行,既能独立运行,高效运行特有的算法,亦能作为 PS Service,支持 Spark 或其它深度学习框架,为其加速。它基于腾讯内部的海量数据进行了反复的实践和调优,并具有广泛的适用性和稳定性,模型维度越高,优势越明显。
腾讯公司是一家消息平台 + 数字内容的公司,本质上也是一家大数据公司,每天产生数千亿的收发消息,超过 10 亿的分享图片,高峰期间百亿的收发红包。每天产生的看新闻、听音乐、看视频的流量峰值高达数十 T。这么大的数据量,处理和使用上,首先业务上存在三大痛点:
第一,需要具备 T/P 级的数据处理能力,几十亿、百亿级的数据量,基本上 30 分钟就要能算出来。
第二,成本需低,可以使用很普通的 PC Server,就能达到以前小型机一样的效果;
第三,容灾方面,原来只要有机器宕机,业务的数据肯定就有影响,各种报表、数据查询,都会受到影响。
其次是需要融合所有产品平台的数据的能力。“以前的各产品的数据都是分散在各自的 DB 里面的,是一个个数据孤岛,现在,需要以用户为中心,建成了十亿用户量级、每个用户万维特征的用户画像体系。以前的用户画像,只有十几个维度主要就是用户的一些基础属性,比如年龄、性别、地域等,构建一次要耗费很多天,数据都是按月更新”。
另外就是需要解决速度和效率方面的问题,以前的数据平台“数据是离线的,任务计算是离线的,实时性差”。
“所以,我们必须要建设一个能支持超大规模数据集的一套系统,能满足 billion 级别的维度的数据训练,而且,这个系统必须能满足我们现网应用需求的一个工业级的系统。它能解决 big data,以及 big model 的需求,它既能做数据并行,也能做模型并行。”
经过 7 年的不断发展,历经了三代大数据平台:第一代 TDW(腾讯分布式数据仓库), 到基于 Spark 融合 Storm 的第二代实时计算架构,到现在形成了第三代的平台,核心为 Angel 的高性能计算平台。
Angel 项目在 2014 年开始准备,15 年初正式启动,刚启动只有 4 个人,后来逐步壮大。项目跟北京大学和香港科技大学合作,一共有 6 个博士生加入到腾讯大数据开发团队。目前在系统、算法、配套生态等方面开发的人员,测试和运维,以及产品策划及运维,团队超过 30 人。
Angel 平台是使用 Java 和 Scala 混合开发的机器学习框架,用户可以像用 Spark, MapReduce 一样,用它来完成机器学习的模型训练。
Angel 采用参数服务器架构,支持十亿级别维度的模型训练。采用了多种业界最新技术和腾讯自主研发技术,如 SSP(Stale synchronous Parallel)、异步分布式 SGD、多线程参数共享模式 HogWild、网络带宽流量调度算法、计算和网络请求流水化、参数更新索引和训练数据预处理方案等。
这些技术使 Angel 性能大幅提高,达到常见开源系统 Spark 的数倍到数十倍,能在千万到十亿级的特征维度条件下运行。
自今年初在腾讯内部上线以来,Angel 已应用于腾讯视频、腾讯社交广告及用户画像挖掘等精准推荐业务。未来还将不断拓展应用场景,目标是支持腾讯等企业级大规模机器学习任务。
首先需要一个满足十亿级维度的工业级的机器学习平台,蒋杰表示当时有两种思路: 一个是基于第二代平台的基础上做演进,解决大规模参数交换的问题。另外一个,就是新建设一个高性能的计算框架。
当时有研究业内比较流行的几个产品:GraphLab,主要做图模型,容错差;Google 的 Distbelief,还没开源;还有 CMU Eric Xing 的 Petuum,当时很火,不过它更多是一个实验室的产品,易用性和稳定性达不到要求。
“其实在第二代,我们已经尝试自研,我们消息中间件,不论是高性能的,还是高可靠的版本,都是我们自研的。他们经历了腾讯亿万流量的考验,这也给了我们在自研方面很大的信心”。
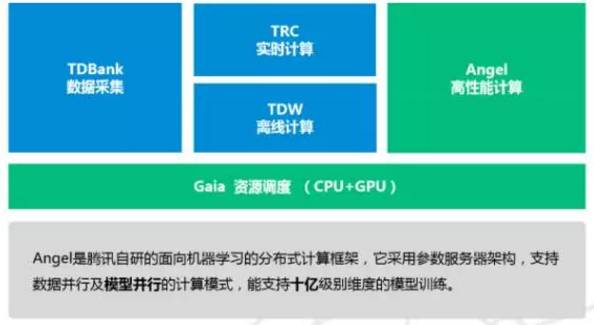
第三代高性能计算平台
“同时,我们第三代的平台,还需要支持 GPU 深度学习,支持文本、语音、图像等非结构化的数据”。
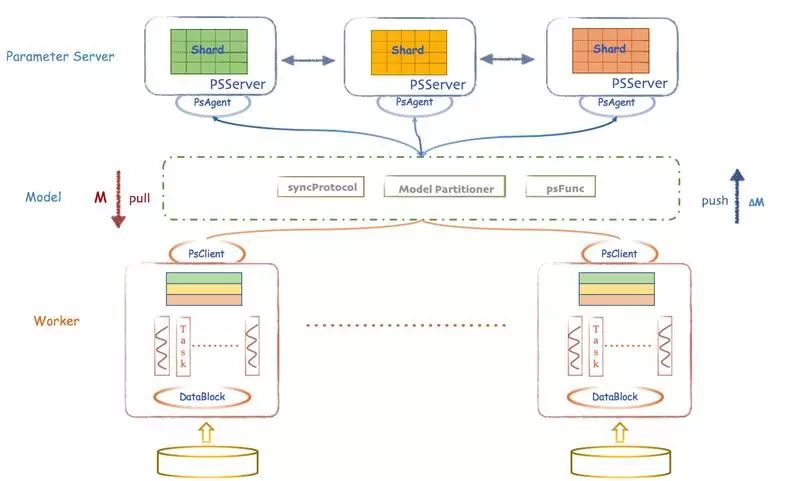
Angel 架构图
Angel 是基于参数服务器的一个架构,整体架构上参考了谷歌的 DistBelief。Angel 在运算中支持 BSP、SSP、ASP 三种计算模型,其中 SSP 是由卡耐基梅隆大学 EricXing 在 Petuum 项目中验证的计算模型,能在机器学习的这种特定运算场景下提升缩短收敛时间。Angel 支持数据并行及模型并行。
在网络上有原创的尝试,使用了港科大杨强教授的团队做的诸葛弩来做网络调度,
ParameterServer 优先服务较慢的 Worker,当模型较大时,能明显降低等待时间,任务总体耗时下降 5%~15%。
另外,Angel 整体是跑在 Gaia(Yarn)平台上面的。
主要的模块有 4 个:
Angel 的客户端,它给应用程序提供了控制任务运行的功能。目前它支持的控制接口主要有:启动和停止 Angel 任务,加载和存储模型,启动具体计算过程和获取任务运行状态等。
Master 的职责主要包括:原始计算数据以及参数矩阵的分片和分发;向 Gaia(一个基于 Yarn 二次开发的资源调度系统)申请 Worker 和 ParameterServer 所需的计算资源; 协调,管理和监控 Worker 以及 ParameterServer。
ParameterServer 负责存储和更新参数,一个 Angel 计算任务可以包含多个 ParameterServer 实例,而整个模型分布式存储于这些 ParameterServer 实例中,这样可以支撑比单机更大的模型。
Worker 负责具体的模型训练或者结果预测,为了支持更大规模的训练数据,一个计算任务往往包含许多个 Worker 实例,每个 Worker 实例负责使用一部分训练数据进行训练。一个 Worker 包含一个或者多个 Task,Task 是 Angel 计算单元,这样设计的原因是可以让 Task 共享 Worker 的许多公共资源。
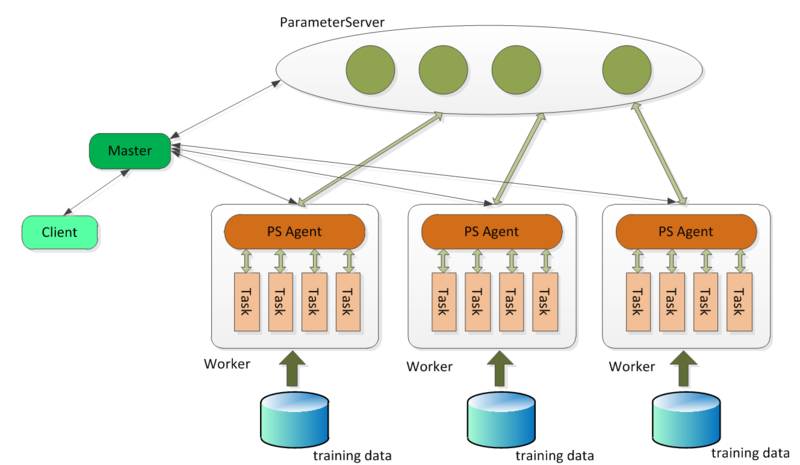
Angel 的系统框架:
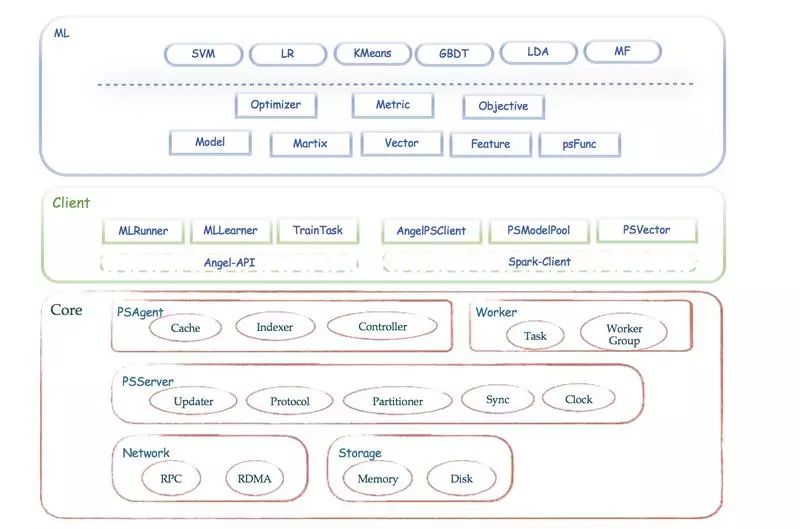
Angel 支持两种运行模式:ANGEL_PS & ANGEL_PS_WORKER
支持多种同步协议:除了通用的 BSP(Bulk Synchronous Parallel)外,为了解决 task 之间互相等待的问题,Angel 还支持 SSP(Stale Synchronous Parallel)和 ASP(Asynchronous Parallel)










