(点击
上方公众号
,可快速关注)
来源:张开涛
链接:
jinnianshilongnian.iteye.com/blog/2232271
从入职京东到现在,做读服务已经一年多的时间了,经历了各种亿级到百亿级的读服务;这段时间也进行了一些新的读服务架构尝试,从架构到代码的编写,各个环节都进行了反复尝试,压测并进行调优,希望得到一个自己满意的读服务架构。
一些设计原则
-
无状态
-
数据闭环
-
缓存银弹
-
并发化
-
降级开关
-
限流
-
切流量
-
其他
无状态
如果设计的应用是无状态的,那么应用就可以水平扩展,当然实际生产环境可能是这样子的: 应用无状态,配置文件有状态。比如不同的机房需要读取不同的数据源,此时就需要通过配置文件指定。
数据闭环
如果依赖的数据来源特别多,此时就可以考虑使用数据闭环,基本步骤:
1、数据异构:通过如MQ机制接收数据变更,然后原子化存储到合适的存储引擎,如redis或持久化KV存储;
2、数据聚合:这步是可选的,数据异构的目的是把数据从多个数据源拿过来,数据聚合目的是把这些数据做个聚合,这样前端就可以一个调用拿到所有数据,此步骤一般存储到KV存储中;
3、前端展示:前端通过一次或少量几次调用拿到所需要的数据。
这种方式的好处就是数据的闭环,任何依赖系统出问题了,还是能正常工作,只是更新会有积压,但是不影响前端展示。
另外此处如果一次需要多个数据,可以考虑使用Hash Tag机制将相关的数据聚合到一个实例,如在展示商品详情页时需要:商品基本信息:p:123:, 商品规格参数:d:123:,此时就可以使用冒号中间的123作为数据分片key,这样相同id的商品相关数据就在一个实例。
缓存银弹
缓存对于读服务来说可谓抗流量的银弹。
浏览器端缓存
设置请求的过期时间,如响应头Expires、Cache-control进行控制。这种机制适用于如对实时性不太敏感的数据,如商品详情页框架、商家评分、评价、广告词等;但对于如价格、库存等实时要求比较高的,就不能做浏览器端缓存。
CDN缓存
有些页面/活动页/图片等服务可以考虑将页面/活动页/图片推送到离用户最近的CDN节点让用户能在离他最近的节点找到想要的数据。一般有两种机制:推送机制(当内容变更后主动推送到CDN边缘节点),拉取机制(先访问边缘节点,当没有内容时回源到源服务器拿到内容并存储到节点上),两种方式各有利弊。 使用CDN时要考虑URL的设计,比如URL中不能有随机数,否则每次都穿透CDN,回源到源服务器,相当于CDN没有任何效果。对于爬虫可以返回过期数据而选择不回源。
接入层缓存
对于没有CDN缓存的应用来说,可以考虑使用如Nginx搭建一层接入层,该接入层可以考虑如下机制实现:
1、URL重写:将URL按照指定的顺序或者格式重写,去除随机数;
2、一致性哈希:按照指定的参数(如分类/商品编号)做一致性Hash,从而保证相同数据落到一台服务器上;
3、proxy_cache:使用内存级/SSD级代理缓存来缓存内容;
4、proxy_cache_lock:使用lock机制,将多个回源合并为一个,减少回源量,并设置相应的lock超时时间;
5、shared_dict:此处如果架构使用了nginx+lua实现,可以考虑使用lua shared_dict进行cache,最大的好处就是reload缓存不丢失。
此处要注意,对于托底/异常数据不应该让其缓存,否则用户会在很长一段时间看到这些数据。
应用层缓存
如我们使用Tomcat时可以使用堆内缓存/堆外缓存,堆内缓存的最大问题就是重启时内存中的缓存丢失,如果此时流量风暴来临可能冲垮应用;还可以考虑使用local redis cache来代替堆外内存;或者在接入层使用shared_dict来将缓存前置,减少风暴。
分布式缓存
一种机制就是废弃分布式缓存,改成应用local redis cache,即在应用所在服务器中部署一个redis,然后使用主从机制同步数据。如果数据量不大这种架构是最优的;如果数据量太大,单服务器存储不了,还可以考虑分片机制将流量分散到多台;或者直接就是分布式缓存实现。常见的分片规则就是一致性哈希了。
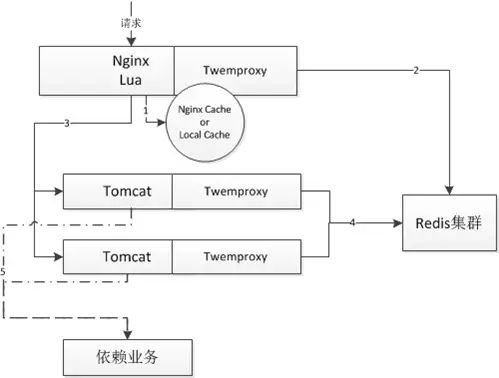
如上图就是我们一个应用的架构:
1、首先接入层读取本地proxy cache / local cache;
2、如果不命中,会读取分布式redis集群;
3、如果还不命中,会回源到tomcat,然后读取堆内cache;如果没有,则直接调用依赖业务获取数据;然后异步化写到redis集群;
因为我们使用了nginx+lua,第二、三步可以使用lua-resty-lock非阻塞锁减少峰值时的回源量;如果你的服务是用户维度的,这种非阻塞锁不会有什么大作用。
并发化
假设一个读服务是需要如下数据:
1、数据A 10ms
2、数据B 15ms
3、数据C 20ms
4、数据D 5ms
5、数据E 10ms
那么如果串行获取那么需要:60ms;
而如果数据C依赖数据A和数据B、数据D谁也不依赖、数据E依赖数据C;那么我们可以这样子来获取数据:
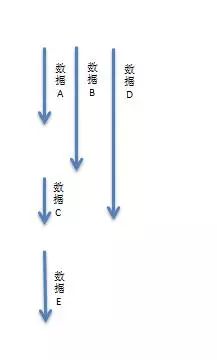
那么如果并发化获取那么需要:30ms;能提升一倍的性能。
假设数据E还依赖数据F(5ms),而数据F是在数据E服务中获取的,此时就可以考虑在此服务中在取数据A/B/D时预取数据F,那么整体性能就变为了:25ms。
降级开关
对于一个读
服务,很重要的一个设计就是降级开关,在设计降级开关时主要如下思路:
1、开关集中化管理:通过推送机制把开关推送到各个应用;
2、可降级的多级读服务:比如只读本地缓存、只读分布式缓存、或者只读一个默认的降级数据;
3、开关前置化:如架构是nginx—>tomcat,可以将开关前置到nginx接入层,在nginx层做开关,请求不打到后端应用。
限流
目的是防止恶意流量,恶意攻击,可以考虑如下思路:
1、恶意流量只访问cache;
2、对于穿透到后端应用的可以考虑使用nginx的limit模块处理;









