行为识别技术在智能监控、人机交互、视频序列理解、医疗健康等众多领域扮演着越来越重要的角色,而视频中的行为识别技术受到遮挡,动态背景,移动摄像头,视角和光照变化等因素的影响而具有很大的挑战性。
今天,美亚柏科技术专家就近年一些比较有代表性的视频行为识别技术和算法进行了一个整理与简述,抛砖引玉,期望与相关技术爱好者交流进步。
每年iPhone的发布都是一场不亚于春晚的大型段子手狂欢秀,今年iPhone X的黑科技人脸识别技术也没有逃过魔爪。
事实上,虹膜识别,指纹识别和已经被玩坏的人脸识别等,各种各样的生物识别技术已经慢慢的从《碟中谍》这类电影迈入了现实生活中,然而除了这些已经被大众熟知的技术,还有一些更加黑科技的技术,比如我们今天要介绍的技术在电影里长这样:

《碟中谍5》中的步态分析系统
图中的步态分析系统,是通过记录、观察、分析身体运动方式,建立步态模型,并提取稳定的参数特征,通过计算机去识别的过程。如同每个人拥有一幅独特的面孔,每个人也拥有一种与众不同的步态。从解剖学的角度分析,步态唯一性的物理基础是每个人生理结构的差异性,不一样的腿骨长度、不一样的肌肉强度、不一样的重心高度、不一样的运动神经灵敏度,共同决定了步态的唯一性。
在人工智能研究领域,这一技能是行为识别中的一种。在多个领域都有广泛的应用。如通过智能监控实时检测和分析老人的行动,判断老人是否正常吃饭、服药、是否保持最低的运动量、是否有异常行动出现(例如摔倒),确保老人的生活质量。或者是人机交互系统,通过对人的行为进行识别,猜测用户的“心思”,预测用户的意图,及时给予准确的响应。在安防领域,更是可以利用行为识别来进行寻找失踪人口和嫌犯追逃的工作。
对行为识别的研究可以追溯到1973年,当时Johansson通过实验观察发现,人体的运动可以通过一些主要关节点的移动来描述,因此,只要10-12个关键节点的组合与追踪便能形成对诸多行为例如跳舞、走路、跑步等的刻画,做到通过人体关键节点的运动来识别行为。另一个重要分支则是基于RGB视频做行为动作识别。
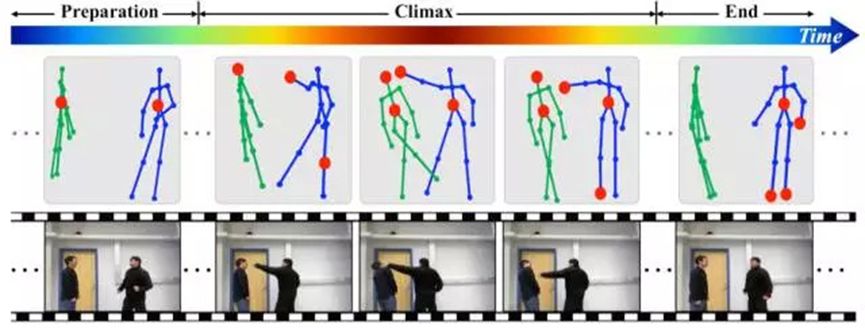
然而行为识别是一项具有挑战性的任务,受光照条件各异、视角多样性、背景复杂、类内变化大等诸多因素的影响。主要的关键点与难点如下:
1、强有力的特征:
即如何在视频中提取出能更好的描述视频判断的特征。特征越强,模型的效果通常较好。
2、特征的编码(encode)/融合(fusion):
这一部分包括两个方面,第一个方面是非时序的,另外一个方面是时序上的,一些动作看单帧的图像是无法判断的,只能通过时序上的变化判断,所以需要将时序上的特征进行编码或者融合,获得对于视频整体的描述。
3、算法速度:
虽然在发论文刷数据库的时候算法的速度并不是第一位的。但高效的算法更有可能应用到实际场景中去。
在深度学习进入该领域前,效果最好的方法是iDT方法(improved dense trajectories),但是该算法速度很慢。深度学习大热之后,自然也没有放过在该领域大展身手的机会,以下选取一些比较有代表性的深度学习方法论文进行简要介绍。
(1) Two Stream Network及衍生方法
“Two-Stream Convolutional Networks for Action Recognition in Videos”(2014NIPS)
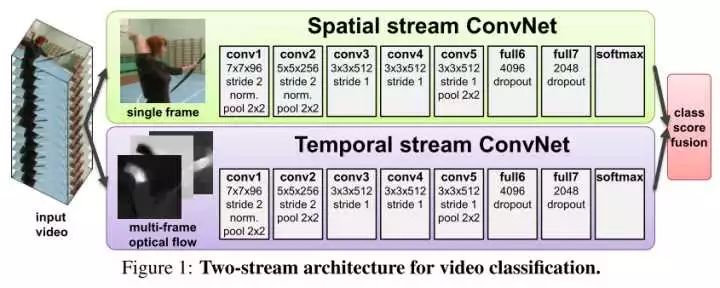
TwoStream方法最初在这篇文章中被提出,基本原理为对视频序列中每两帧计算密集光流,得到密集光流的序列(即temporal信息)。然后对于视频图像(spatial)和密集光流(temporal)分别训练CNN模型,两个分支的网络分别对动作的类别进行判断,最后直接对两个网络的class score进行fusion(包括直接平均和svm两种方法),得到最终的分类结果。注意,对与两个分支使用了相同的2D CNN网络结构,其网络结构见下图。
实验效果:UCF101-88.0%,HMDB51-59.4%
在two streamnetwork的基础上的衍生算法有
1. Convolutional Two-StreamNetwork Fusion for Video Action Recognition(2016CVPR)
在two stream network的基础上,利用CNN网络进行了spatial以及temporal的融合,将基础的spatial和temporal网络都换成了VGG-16 network。
实验效果:UCF101-92.5%,HMDB51-65.4%
2.
”
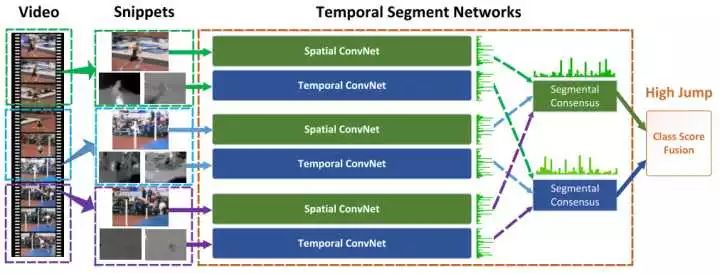
Temporal Segment Networks: Towards Good Practices for Deep ActionRecognition
”
这篇文章提出的TSN网络也算是spaital+temporal fusion,结构图见下图。这篇文章对如何进一步提高twostream方法进行了详尽的讨论。
实验效果:UCF101-94.2%,HMDB51-69.4%
(2) C3D Network
"Learning spatiotemporal features with 3dconvolutional networks"
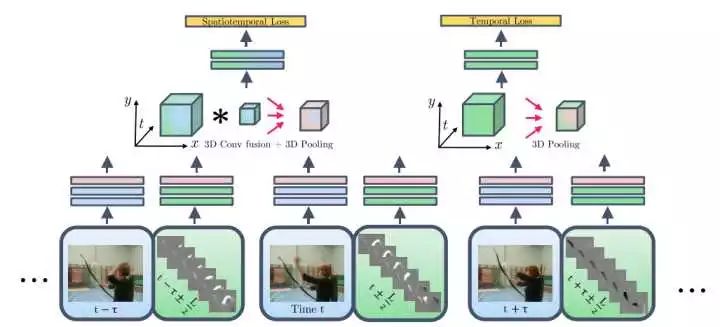
C3D是facebook的一个工作,采用3D卷积和3D Pooling构建了网络。通过3D卷积,C3D可以直接处理视频(或者说是视频帧的volume)。C3D的最大优势在于其速度,在文章中其速度为314fps。而实际上这是基于两年前的显卡了。用Nvidia 1080显卡可以达到600fps以上。所以C3D的效率是要远远高于其他方法的。
实验效果:UCF101-85.2%

(3) 其他方法
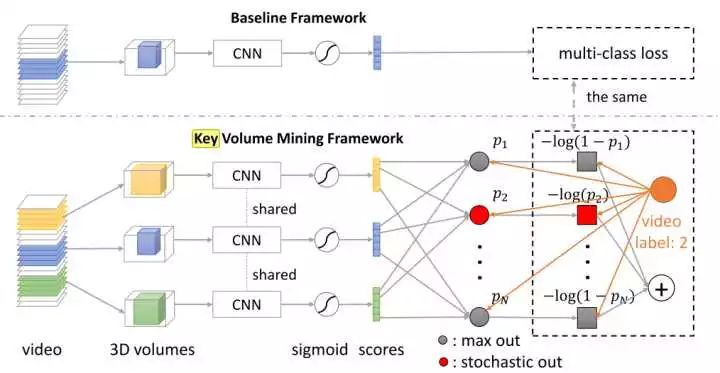
1.“A Key VolumeMining Deep Framework for Action Recognition”
本文主要做的是keyvolume的自动识别。通常都是将一整段动作视频进行学习,而事实上这段视频中有一些帧与动作的关系并不大。因此进行关键帧的学习,再在关键帧上进行CNN模型的建立有助于提高模型效果。
实验效果:UCF101-93.1%,HMDB51-63.3%
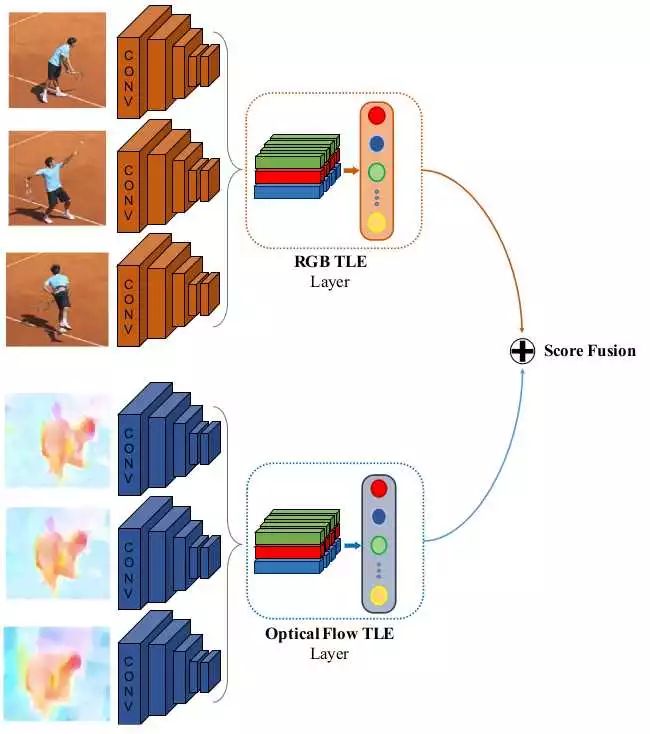
2. ”Deep Temporal Linear Encoding Networks”
本文主要提出了“TemporalLinear Encoding Layer”时序线性编码层,主要对视频中不同位置的特征进行融合编码。至于特征提取则可以使用各种方法,文中实验了two stream以及C3D两种网络来提取特征。
实验效果:UCF101-95.6%,HMDB51-71.1%(特征用two stream提取)。应该是目前为止看到效果最好的方法了。
然而,实际应用中,行为识别远比想象中的困难。实际环境复杂,需要从连续的视频流和其他传感设备中获取动态的目标信息,对目标进行定位、跟踪、判断动作的起止、分解交织的动作等等,这本身就是一部分艰难的研发任务,同时还要克服背景变化,遮挡、摄像头抖动等因素。当然,光靠识别单一动作是远远不够的,需要结合画面中的人脸、衣服颜色、步态等多维特征构建人体基本信息。
以上只是对近年一些比较有代表性的技术和算法进行了一个整理与简述,除了上述的论文外,这个方向这几年的论文还有许多,有兴趣的读者可以自行上网查阅文献。可以看出,这几年行为识别领域发展的非常快,各种各样的方法被提出。尽管还未被大规模应用,但也不妨提前学习研究,做好准备,毕竟做IT的人不服输。










