pysipder 是一个很受欢迎的爬虫库,而且还是国人开发的。不看不知道,一看吓一跳。本文是该库的作者写的一篇介绍,说明了为什么会出现 pysipder。
作者:binux
原文:https://binux.blog/2014/11/introduction-to-pyspider/
缘起
pyspider 来源于以前做的一个垂直搜索引擎使用的爬虫后端。
我们需要从200个站点(由于站点失效,不是都同时啦,同时有100+在跑吧)采集数据,并要求在5分钟内将对方网站的更新更新到库中。
所以,灵活的抓取控制是必须的。同时,由于100个站点,每天都可能会有站点失效或者改版,所以需要能够监控模板失效,以及查看抓取状态。
为了达到5分钟更新,我们使用抓取最近更新页上面的最后更新时间,以此来判断页面是否需要再次抓取。
可见,这个项目对于爬虫的监控和调度要求是非常高的。
主要特性
python 脚本控制,可以用任何你喜欢的html解析包(内置 pyquery)
WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出
支持 MySQL, MongoDB, SQLite
支持抓取 JavaScript 的页面
组件可替换,支持单机/分布式部署,支持 Docker 部署
强大的调度控制
由于功能太多,更多请参考脚本编写指南。
感谢 +PhoenixNemo 提供的VPS,提供了一个 demo: demo.pyspider.org。无需安装即可体验。
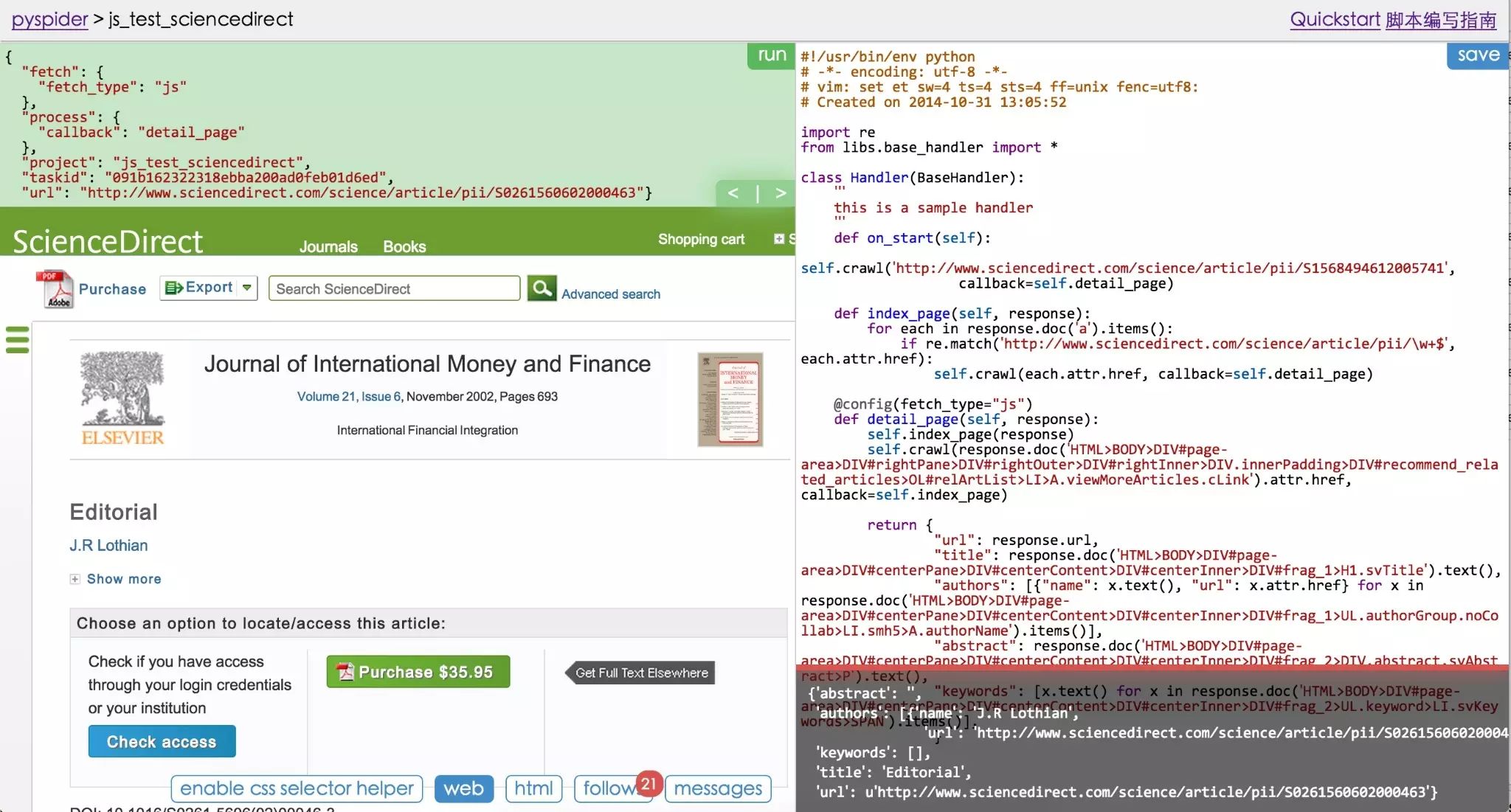
脚本样例
from libs.base_handler import *
class Handler(BaseHandler):
'''
this is a sample handler
'''
@every(minutes=24*60, seconds=0)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10*24*60*60)
def index_page(self, response):
for each in response.doc('a[href^="http://"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
例如这就是创建任务后默认生成的一个脚本示例。
通过 on_start 回调函数,作为爬取的入口点,当点击主面板上的 run 的时候,就是调用这个函数,启动抓取。
self.crawl 告诉调度器,我们需要抓取 'http://scrapy.org/' 这个页面,然后使用 callback=self.index_page 这个回调函数进行解析。
所有 return 的内容默认会被捕获到 resultdb 中,可以直接在 WEBUI 上看到。
题图:pexels,CC0 授权。

点击阅读原文,查看更多 Python 教程和资源。









