
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
长短期记忆(LSTM)网络是一种流行并且性能很好的循环神经网络(RNN)。
像在python深度学习库Keras中,这些网络有明确的定义和易用的接口,但是它们一般都是很难配置的,可以解决任意序列的预测问题。
在库Keras中出现这个困难的原因是采用了TimeDistributed包装层,并且一些LSTM层需要返回的是序列而不是单独一个值。
在这个教程中,你会学习到配置LSTM网络的不同方式,来解决序列预测问题;也会了解到TimeDistributed层的作用,学会怎样利用它。
学习这个教程,你会了解到:
-
如何构建一个解决序列预测问题的一对一LSTM网络;
-
如何构建一个解决序列预测问题的多对一LSTM网络,不采用TimeDistributed层;
-
如何构建一个解决序列预测问题的多对多LSTM网络,采用TimeDistributed层;
现在开始!
教程目录
此教程分为5个部分:
1. TimeDistributed层
2. 序列学习问题
3. 用于解决序列预测问题的一对一LSTM网络
4. 用于解决序列预测问题的多对一LSTM网络(无TimeDistributed层)
5. 用于解决序列预测问题的多对一LSTM网络(TimeDistributed层)
环境
此教程需要Python2或者Python3开发环境,依赖SciPy、NumPy、Pandas库。此教程也需要scikit-learn库和安装Keras v2.0+,以Theano或TensorFLow为后端均可。
配置Python环境请参考这里:
http://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
TimeDistributed层
LSTMs性能很好,但是运用较难,并且配置也很难,特别是对于新手。
另外一个困难之处就是被描述为层包装的TimeDistributed层(以前是TimeDistributedDense层):
这个包装可以将层应用到输入的每一个时间片上
在LSTMs中,怎样、什么时候应该运用这个包装呢?
当你在Keras Github和StackOverflow上搜索关于包装层讨论时,你会发现越来越迷惑、复杂难解。
例如,针对问题When and How to use TimeDistributedDense(
https://github.com/fchollet/keras/issues/1029
),fchollet(Keras的作者)解释说:
TimeDistributedDense将同样的密集(全连接)操作应用到3D张量的每一个时间间隔上。
当你已经理解TimeDistributed是干什么的,什么时候运用它时,这样的回答是有意义的,但是对于新手来说是没有任何帮助的。
此教程的目的就是解决在LSTMs中运用TimeDistributed层出现的疑惑,并且利用可运行的例子来帮助读者理解。
序列学习问题
下面利用一个简单的序列学习问题来阐述TimeDistributed层。假设输入序列为[0.0,0.2,0.4,0.6,0.8],每次输入一个,每次按顺序输出一个结果。可以把它看作学习一个简单的重复程序,当输入为0.0时,希望输出结果为0.0,重复序列中的每一个元素。
生成此序列的代码如下:

运行此代码将会得到如下序列:
[ 0. 0.2 0.4 0.6 0.8]
这个例子是可配置的,读者自己可以改变序列的长短,欢迎在评论区分享你的结果。
用于解决序列预测问题的一对一LSTM网络
在叙述之前,首先说明这个序列学习问题是可分段学习的。也即是,把序列中的每一个元素,转化成一个输入-输出一一对应的数据集。假设输入0那么网络应该输出0,当输入为0.2时,网络应该输出0.2,其它一样。这是此问题最简单的模型,把输入序列分割成输入-输出一一对应的结果,对输入序列在网络外部每次给出一个预测结果。
输入-输出一一对应结果如下:
X,
y
0.0,
0.0
0.2,
0.2
0.4,
0.4
0.6,
0.6
0.8,
0.8
LSTMs网络的输入必须是三维的,我们可以把一个二维序列映射成有5个样本、时间步长为1、1个特征的三维序列,并定义输出为5个采样值、1个特征。
x = seq.reshape(5, 1, 1)
y = seq.reshape(5, 1)
定义一个每次有1个输入的网络模型,第一个隐藏层是有5个神经元的LSTMs,输出层是只有一个输出的全连接层,模型采用有效的ADAM优化算法,均方差误差作为损失函数。
为了避免必须采用手动方式来使得LSTM有输出和复位其状态,即使这在更新权重时很容易做到,但是每轮训练时还是把batch大小设置为样本的大小。
全部的代码如下:

运行此代码可打印网络的结构,LSTM层有140个参数,这个可以参考如下计算方式得到:
n = 4 * ((inputs + 1) * outputs + outputs^2)
n = 4 * ((1 + 1) * 5 + 5^2)
n = 4 * 35
n = 140
全连接层只有6个参数,参数个数计算方式如下:
n = inputs * outputs + outputs
n = 5 * 1 + 1
n = 6

网络可以正确学习这个预测问题:
0.0
0.2
0.4
0.6
0.8
用于解决序列预测问题的多对一LSTM网络(无TimeDistributed层)
在这一部分,我们构建一个没有TimeDistributed层的LSTM网络,并且立即输出结果序列。LSTMs网络的输入必须是三维的,我们可以把一个二维序列映射成有1个样本、步长为5、1个特征的三维序列,并定义输出为1个采样值、5个特征。
X = seq.reshape(1, 5, 1)
y = seq.reshape(1, 5)
马上你就可以看到在没有TimeDistributed包装的情况下,问题的定义需要稍加调整以满足序列预测问题的网络模型,具体来说,就是输出一个向量而不是每次一步一步建立一个输出序列,这个差别看起来非常小,但这是理解TimeDistributed包装的关键所在。
下面我们定义一个有1个输入,时间步长为5的模型。第一个隐藏层是有5个神经元的LSTM,输出层为全连接层。

接下来,训练此模型500轮,在训练数据集中仅有1个数据,因此batch大小为1.
# train LSTM
model.fit(X, y, epochs=500, batch_size=1, verbose=2)
把上述代码整合在一起,完整的代码如下:
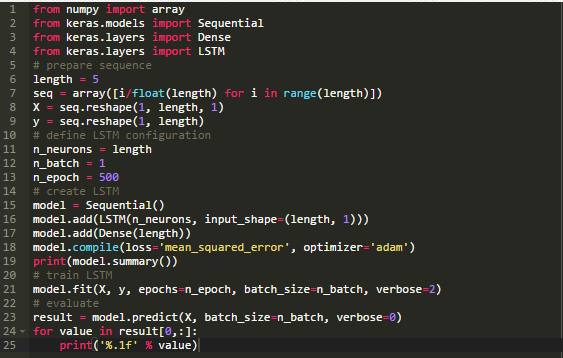
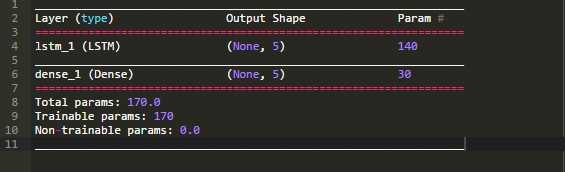
运行代码可以打印网络的结构,可以看到这个LSTM模型同前面一样也有140个参数。LSTM单元被破坏并且每一个单元输出一个值,产生有5个元素的向量,作为全连接层的输入。时间纬度或者说序列信息被丢弃,转化为一个具有5个元素的向量。
全连接输出层有5个输入,期望产生5个输出,可以根据下式算出需要30个权重系数:
n = inputs * outputs + outputs
n = 5 * 5 + 5
n = 30
网络的概要信息如下:
模型训练过程中会打印损失函数信息,最后输出序列预测的结果。该序列会被正确地以一个单一的块再现,而不是序列中每个元素逐步再现。我们可以用一层密集连接层作为第一个隐藏层,而不是采用LSTMs,这个原因在于后者的用法没有完全发挥序列学习处理的能力。
0.0
0.2
0.4
0.6
0.8
用于解决序列预测问题的多对多LSTM网络(TimeDistributed层)
这部分利用TimeDistributed层来处理LSTM隐藏层的输出,在运用TimeDistributed包装层的时候需要记住两个关键点:
定义一个有1个样本,时间步长为5,1个特征的输出,形如输入序列,如下:
y = seq.reshape(1, length, 1)
通过将“return_sequences”参数设置为“True”来定义LSTM隐藏层返回序列而不是单独的一个值。
model.add(LSTM(n_neurons, input_shape=(length, 1), return_sequences=True))
这样会使得每一恶搞LSTM单元返回一个具有5个输出元素的序列,每次产生一个对应于输入数据的输出,而不是像前面例子中的输出单个值。当然也可以利用TimeDistributed包装全连接层的输出,以得到单个的输出。
model.add(TimeDistributed(Dense(1)))
输出层的单个输出值是很重要的,它表示对于输入序列,我们希望每一次只输出一个值,这样一来可以一次处理时间步长为5的输入序列。TimeDistributed的技巧在于,每次都是将同样的密集层应用到LSTMs的输出,这样输出层仅需要一个连接到每一个LSTM单元(加上一个偏置)。因此,为了应对较小的网络容量,需要增加训练的轮数。可以从500增加到1000以匹配第一个一对一的例子。
把代码整合在一起,完整的代码如下:

运行这个例子,得到此网络的结构信息。同前面的例子,LSTM隐藏层依然有140个参数。完全连接输出层正好符合一对一的例子,对于每一个LSTM单元就有一个有权重的神经元,另外一个用于偏置输入。
这个有两个地方需要注意:
每次将更简单的完全连接层应用到上一层的输出序列上以得到输出序列。

网络的输出结果如下:
0.0
0.2
0.4
0.6
0.8
在第一个例子中,可以把利用时间步长进行问题建模和TimeDistributed层看作是一个更加紧凑的实现一对一网络模型的方式,这样可以在空间或者时间上提升会非常明显。
深入理解
下面是一些关于TimeDistributed层的资源或者讨论。
-
TimeDistributed Layer in the Keras API(
https://keras.io/layers/wrappers/#timedistributed
)
-
TimeDistributed code on GitHub(
https://github.com/fchollet/keras/blob/master/keras/layers/wrappers.py#L56
)
-
The difference between ‘Dense’ and ‘TimeDistributedDense’ of ‘Keras’ on StackExchange(
http://datascience.stackexchange.com/questions/10836/the-difference-between-dense-and-timedistributeddense-of-keras
)
-
When and How to use TimeDistributedDense on GitHub(
https://github.com/fchollet/keras/issues/1029
)
总结
此教程你可以学到如何构建用于序列预测的LSTM网络模型,并且帮助理解TimeDistributed层的作用。
具体地,有以下内容:
英文原文:http://machinelearningmastery.com/timedistributed-layer-for-long-short-term-memory-networks-in-python/
译者:章川





