点击上方
“
小白学视觉
”,选择加"
星标
"或“
置顶
”
重磅干货,第一时间送达

文章分析了深度卷积神经网络(CNNs)在进行推理时近似乘法的影响。
作者丨橘子玉米@知乎
链接丨https://zhuanlan.zhihu.com/p/586050382
近似乘法可以减少底层电路的成本,以便在硬件加速器中更有效地执行CNN推理。该研究确定了卷积、全连接和批归一化层中的关键因素,允许更精确的CNN预测,尽管有来自近似乘法的错误。同样的因素也从算术上解释了为什么bfloat16乘法在cnn上表现良好。
实验在公认的网络架构下进行,
结果表明近似乘法器可以产生与FP32参考数据几乎一样准确的预测,而无需额外的训练
。例如,带有Mitch-w6乘法的ResNet和Inception-v4模型会产生Top-5错误与FP32参考数据相比,仅为0.2%。给出了Mitch-w6和bfloat16的简单成本比较,其中MAC操作比bfloat16算法节省高达80%的能量。本文最深远的贡献是分析论证:在CNN MAC操作中,乘法可以近似,而加法需要精确。
首先解释一下bfloat16:Bfloat 格式使用 8 位指数和 7 位尾数,而不是 IEEE 标准 FP16 的 5 位指数和 10 位尾数。Bfloat 可以表示从~1e-38 到~3e38 的值,其动态范围比 IEEE 的 FP16 宽几个数量级,从而有利于更准确的对神经网络进行训练。
在以往的工作中有两个普遍的局限性。1.有些技术的计算成本很高,因为要优化每个网络模型或重新训练网络以补偿其方法带来的性能下降。2.许多技术仅对小型网络有效,不能扩展到更深层次的cnn,因为在更深层次的网络测试时,它们报告的性能结果要差得多。它们利用了这样一个事实:少量的比特对小型cnn来说就足够了,但更复杂的网络需要更多的比特才能恰当地表示信息量。
一种很有前途的基于硬件的方法是将近似乘法应用于CNN推理。它包括设计和应用乘法电路,降低了硬件成本,但产生的结果并不精确。与牺牲数值精度的激进量化不同,乘法器牺牲的是对网络模型依赖性较小的算术精度,这使它们变得更加适合deep cnn。该方法不涉及对目标网络模型的任何优化,也不需要对网络模型进行额外的处理,因此可以轻松适应ASIC和FPGA加速器。
虽然在之前的几项研究中已经证明了
通过近似乘法优化CNN推理
,但人们对为什么它对CNN有效知之甚少。这些有希望的结果导致人们普遍观察到cnn对小的算术错误具有弹性,但没有一个发现这种弹性背后的完全原因。具体来说,
尚不清楚当所有的乘法都有一定数量的错误时,CNN层如何保持它们的功能。缺乏理解使得识别每个网络模型的合适近似乘法具有挑战性,导致在一些研究中使用昂贵的基于搜索的方法。
本文研究了近似乘法误差对CNN深度推理的影响。这项工作的动机是硬件电路,但它关注的是从深度学习的角度。主要贡献为:
1.解释卷积和全连接(FC)层如何在近似相乘的情况下保持其预期功能。
2.演示批处理归一化在适当调整参数时如何防止更深层次的错误累积。
3.讨论这些发现也解释了为什么bfloat16乘法当精确度的降低时在cnn上表现良好。
4.实验表明,具有近似乘法的deep cnn性能相当好。
5.通过简单地比较硬件成本与bfloat16算法的硬件成本,讨论该方法的潜在成本效益。
一、简介
CNN中的卷积层由大量的乘法累积(MAC)操作组成,它们占用了CNN推理的大部分计算。MAC操作最终在硬件电路中执行,重要的是最小化这些电路的成本,以使用相同的资源执行更多的计算。对于MAC运算,乘法比加法更复杂,并且消耗大部分资源。所提出的方法是通过用近似的乘法代替传统的乘法来减少乘法的成本。近似乘法器比精确乘法器划算得多,但它们在结果中引入了误差。有许多不同类型的近似乘法具有不同的代价和误差特性。有些设计使用电子属性,有些则通过故意翻转逻辑中的位来近似,而另一些则使用算法来近似乘法。
本文研究了用了前人给出的近似对数乘法进行近似乘法的影响,以及其他一些有前途的设计。近似对数乘法是基于mitchell 算法,它在对数域中执行乘法。图1显示了传统定点乘法器与对数乘法器之间的区别。
基于算法的近似的一个重要好处是一致的错误特征,这允许在不同的CNN实例中一致地观察影响
。其他类型的近似有更多不一致的误差,使它们不适合研究。例如,基于电子性质的近似乘法器不仅依赖于操作数,而且依赖于过程、电压和温度(PVT)的变化,这使得很难获得一致的观测结果。然而,这项研究的发现并不局限于对数乘法,而且可能有助于解释其他方法在满足下面所讨论的条件时的可行性。
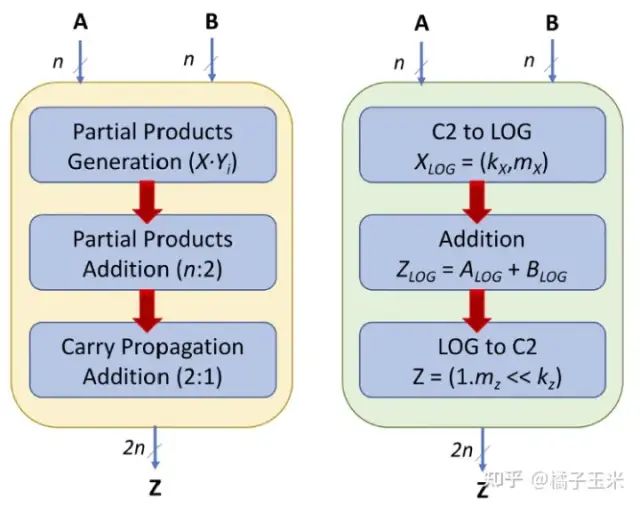
图1 传统定点乘法器与对数乘法器
定义相对误差为:|
Z
′
|
代表近似值,|
Z
|
代表准确值。
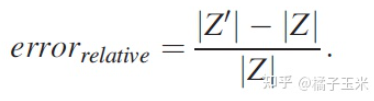
近似对数乘法需要单独的符号处理,同时不影响乘积的符号。与原始的Mitchell log乘法器相比,Mitch-w6有一个由1的补(C1)符号处理引起的小频率的高相对误差,但它们是可以接受的误差。应该注意的是,近似对数乘法器在输入范围内有相当均匀的误差分布,但只能有负误差,导致乘积的量级小于精确乘积的量级。近似乘法器的平均误差是通过随机输入重复多次乘法和Mitchell乘法器来测量的。Mitchell乘法器平均有-3.9%误差,Mitch-w6平均误差为-5.9%。
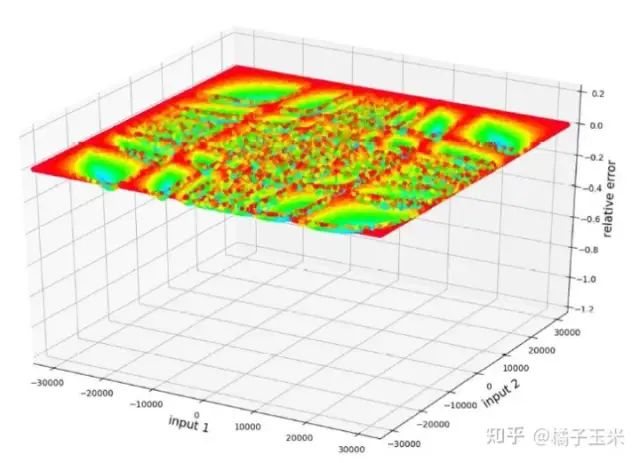
图2 Mitchell乘法器误差
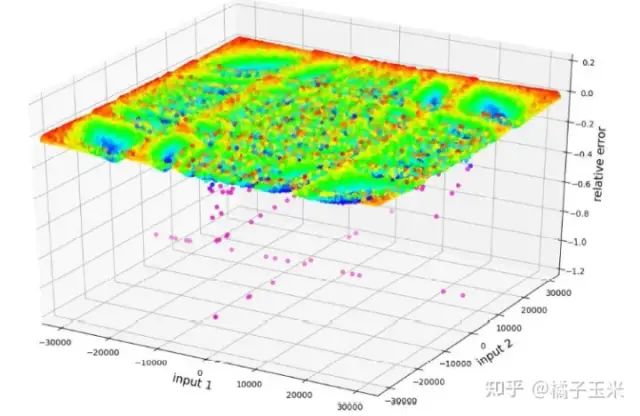
图3 Mitch-w6误差
除了卷积层,FC层也有MAC操作,但与卷积相比,它们的计算量更少。我们的方法仍然适用于FC层的近似乘法,以与使用1x1卷积作为分类器的网络一致。另一方面,批处理归一化中的操作不是近似的,因为它们在推理过程中会被吸收到相邻的层中。
了解量化方法和近似乘法之间的区别是很重要的。量化是将CNN模型中的浮点值转换为定点值的过程,以便在硬件中进行更具成本效益的推理。量化的目标是找到能充分表示值分布的最小定点位数。事实上,有一些具有少量定点位的近似方法无法与浮点格式的范围和精度相匹配。这种近似的误差取决于网络模型,因为每个模型都有不同的分布值。网络依赖性是为什么更复杂的网络需要更多的比特数,激进量化的好处减少的原因。虽然许多研究已经成功地证明了量化的有效性,但它们通常报告,当只在deep CNN上使用8bit量化时,CNN预测精度显著下降。
近似乘法对网络的依赖性较小,因为它的误差来自于近似方法,而不是缺乏范围和精度。在适当的量化条件下,近似乘法进一步将给定比特数的乘数器的成本降至最低。近似乘法是量化的一种正交方法,因为近似乘法可以设计为任意数量的位,它补充了量化,以最大限度地提高CNN推理的计算效率。
二、卷积中的累计误差
本节将解释卷积层和FC层如何在近似乘法产生错误的情况下实现其预期功能。
1.理解卷积层和FC层
解释近似乘法的效果必须从理解卷积层和FC层如何实现其预期功能开始。图4显示了卷积和FC的输出。CNN卷积层通过在其输入通道和内核之间进行卷积来实现抽象特征检测。它们生成特征映射,如图4(a)和(b)所示,其中与内核匹配的位置用相对于其他位置的高输出值表示。与sigmoid或阶跃激活不同,广泛所使用的ReLU激活函数只是将负输出值强制为零,而没有用于识别抽象特征的绝对阈值。这意味着抽象的特征不是通过它们的绝对值来识别的,而是通过每个特征图中相对较高的值来识别的,这一主张也得到了一个事实的支持,即卷积之后通常是一个池化层。同样,当FC层基于抽象特征对图像进行分类时,
分类的概率由所有FC输出的相对强度和顺序决定
。cnn只是选择最好的分数作为最可能的预测,而不是设置一个阈值来进行预测。
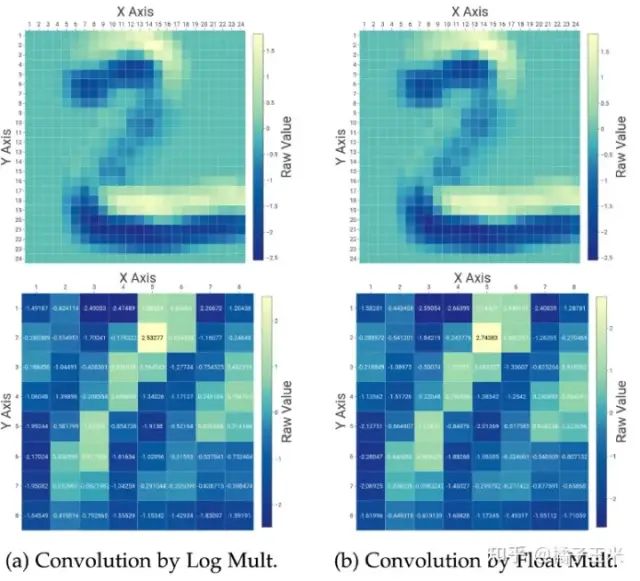
图4 卷积输出和来自LeNet样本推理的最终原始分数。
因为特征是用相对的值而不是绝对值表示的,所以在对卷积进行近似乘法运算时,
最小化卷积输出之间的误差方差比最小化误差的绝对平均值要重要得多。换句话说,只要误差对卷积的所有输出的影响尽可能相等,那么在乘法运算中存在一定的误差是可以接受的
。FC层的行为方式相同,因此最小化节点之间的误差方差非常重要。图4演示了这一原理,并显示Mitchell对数乘法器可以产生正确的推断,因为所有输出同时受到影响。从图4也可以看出,当使用近似对数乘法时,卷积层和FC层的累积误差的方差非常小,卷积虽然量级较小,但仍然能够定位抽象特征。然而,之前的工作并没有说明为什么应用近似乘法时累积误差的方差是最小的更有效。
2.最小误差方差
本文对卷积层和FC层中累积误差方差最小的原因进行了解析。这些层由大量的乘法和累加组成,将误差归结为一个平均值。由于这种收敛性,累积误差的方差被最小化,所有层的输出都受到相同的影响,然后保持输出之间的相对量具有抽象特征检测的功能。
每个CNN模型和层的权重和输入分布是不同的。乘法的输入、权重和输入像素是大量的,而且实际上是不可预测的,具有伪随机性,这反过来又使近似乘法的误差为伪随机。近似对数乘法器在输入范围内具有均匀分布的误差模式,如图2所示,因此无论来自cnn的输入范围不同,误差的期望值都接近近似乘法器的平均误差。当每个卷积输出由近似乘法累积许多个乘积时(一个输出需要累加多个乘法的结果),累积误差在统计上更接近期望值,即近似乘法的平均误差。这种融合减少了输出之间累积误差的方差,这些值的比例大致相同,将变化的误差对特征检测的影响最小化。
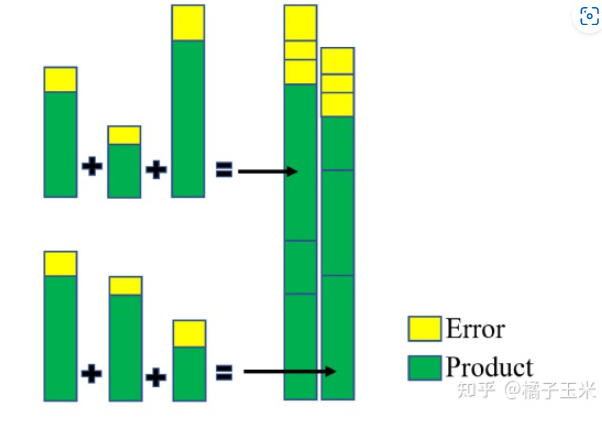
图5 许多具有不同误差量乘积的累积将误差收敛到一个平均值
如图5所示,可以看到加了三次之后最后的绝对误差虽然很大,但是相对值还是没有变化。因此,在大量积的情况下,简单地用近似乘法的平均误差对特征进行缩放。
上述观察结果仅适用于正负乘积之间对称误差的近似乘法。本文所研究的近似乘法都满足这一条件,因为它们都分别处理符号和大小。
虽然我们主要使用Mitch-w乘法来证明这个假设,但这个假设并不依赖于log乘法的内部工作,而只依赖于输出误差特征。因此,该理论可以同样适用于任何满足本节假设的近似乘法,即
均匀分布误差和正负乘积之间的对称误差
。只有像Mitch-w这样的负错误并不是必须的。应该注意的是,均匀分布误差的假设是用来容纳不同范围的输入
,当近似乘法器可以为特定的输入分布产生一致的误差期望值时,可以放宽这种假设
。在本文中,我们还使用DRUM6和截断迭代对数乘法进行实验,以说明假设可以应用于其他近似乘法。
三、对卷积层和FC层的影响
卷积中累积的次数是有限的,所以收敛并不能完全抵消累积误差的方差。然而,来自近似乘法的少量误差方差是可以接受的,因为CNN被设计为具有一般性和鲁棒性。正则化的技术,比如pooling和dropout,故意丢失一些信息来抑制过拟合,增加CNN预测的普适性。一些研究发现,小的算术错误也有类似的积极影响。例如,一只眼睛需要被识别为眼睛,尽管它与训练样本有一点不同。CNN的设计作为忽略这些微小的差异和一些计算上的不准确性不仅是可以容忍的,而且往往有助于提供这样的概括性。
deep CNN通常从少量的卷积通道开始获得一般的特征,而在更深的层中,特征变得更具体的通道数量会增加。在这类CNN上的近似乘法显示出所需的趋势,即在深层产生较小的影响。
浅层累积误差的较大差异是可以容忍的,因为特征检测需要考虑输入图像中的小变化
。
这个假设暗示了精确加法在cnn中的重要性,因为
乘法误差不会在不精确累加的情况下正确收敛
。其中近似的添加对CNN准确性有更大的影响。由于定点算法中的乘法器要比加法器昂贵得多,所以在CNN推理中,仅近似乘法器就能以最小的退化获得最大的效益。
近似乘法还得益于卷积输出接收来自同一组输入通道的输入。对于每个卷积输出,都有两种类型的累积。
一种类型发生在跨kernel维度的每个输入通道中,而另一种类型发生在跨输入通道以产生最终输出
。通道内积累结合了来自相同输入通道和kernel的乘积,因此每个通道都有一个特定的值范围,这些值位于特性所在的范围内。由于每个输入通道都有自己的kernel和输入值,因此通道间的累积可能有更多不同的乘积范围。不同的输入范围可能会在近似乘法器上触发不同的误差特性,但每个卷积输出都会从所有输入通道累积,因此它不会影响输出之间累积误差的方差。这一观察结果的一个含义是当每个输出都不是来自同一组数据时,近似乘法不起作用。
四、分组和逐通道卷积
通过与分组卷积和深度可分离卷积的比较,可以更好地理解和验证传统卷积的近似乘法的优点。
深度可分卷积由逐通道卷积和逐点卷积组成
。逐通道卷积是分组卷积的一种特殊情况,它消除了跨输入通道的累积,累积次数的减少导致输出中累积误差的方差的增加。图6为常规卷积与逐通道卷积的累积模式对比。此外,每个输出通道只从一个输入通道接收输入,在接下来的逐点卷积中发生通道间累积之前,输出通道之间的误差差受另一个近似的误差乘法和方差的影响。
由于近似乘法的误差不能很好地收敛,因此使用深度可分卷积的CNN需要更精确的近似乘法。
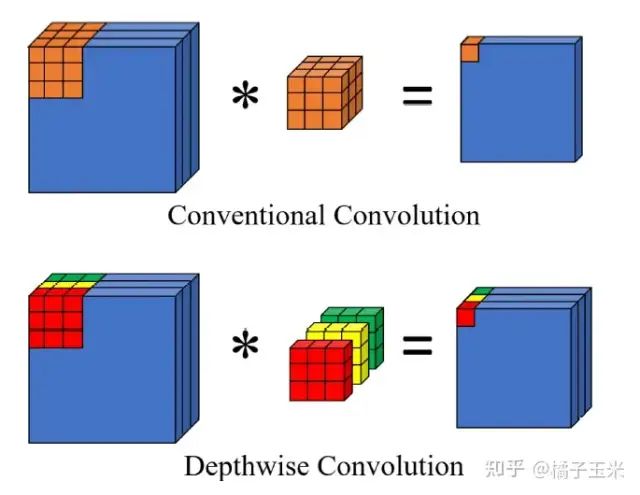
常规卷积和逐通道卷积
另一种减少累积数量的技术是1x1卷积,但它被发现与近似乘法相兼容。1x1卷积没有任何通道内累积,而是跨输入通道累积乘积。由于deep cnn需要大量与其深度结构相适应的通道,1x1卷积的输入通常包含许多输入通道,因此为误差收敛提供了足够的累积。1x1卷积的每个输出也接受来自所有输入通道的输入,这使得输出之间的误差积累更加一致。
五、批处理归一化的效果
近似对数与米切尔算法的乘法在结果中产生负误差,这意味着与精确乘法相比,乘积具有更小的量级。在每一卷积层中进行对数乘法,特征具有较小的量级。有许多卷积层会反复导致减少,以前的工作报告说这对更深的层来说是一个问题。它对网络性能的不利影响可以在只有8层卷积和FC的AlexNet中观察到,而且尚不清楚平均错误累积在更深层的网络中会如何表现。
拥有数十或数百个卷积层可以显著减少特征的量级,从而使较深层的层接收到难以区分的输入分布
。另一方面,如果近似乘法具有正偏的平均误差,则有可能放大量化设置的范围以外的值,导致算术溢出。这些不利影响是在ReLU激活的最佳情况下发生的,而其他类型(如sigmoid函数)在激活时可能会出现额外的错误。因为对于正值来说,rulu不改变数的大小,而其他的激活函数会改变大小。
批处理归一化是在大多数deep cnn中使用的流行技术,它可以缓解这个问题,并帮助近似乘法深入网络。批处理归一化的一个关键功能是重新分配输出特征映射,使更深层的输入分布更加一致。虽然训练过程需要这个函数,但对结果模型的推理仍然需要使用存储的期望分布的全局参数进行归一化。这些全局参数可以适当调整,以考虑由于近似乘法而导致的分布变化,这可以防止跨层的平均误差积累。
批处理归一化的抽象概述如图7所示。在训练过程中,每个批处理归一化层计算并存储输入分布的均值和方差值。用这些均值和方差值对输入分布进行归一化处理,生成均值为0,方差为1的归一化分布。然后,批处理归一化使用可学习的参数对归一化分布进行缩放和移位,恢复网络的表示能力。从本质上说,批处理归一化在激活函数之前或之后重新分配特征映射,以便下一层可以接收到输入的一致分布。所有这些参数都是在训练过程中学习到的,并以数值的形式存储在CNN模型中,如果需要,可以很容易地修改它们。CNN推理使用这些存储的参数来执行规范化,假设它们在推理期间表示相同的输入分布。
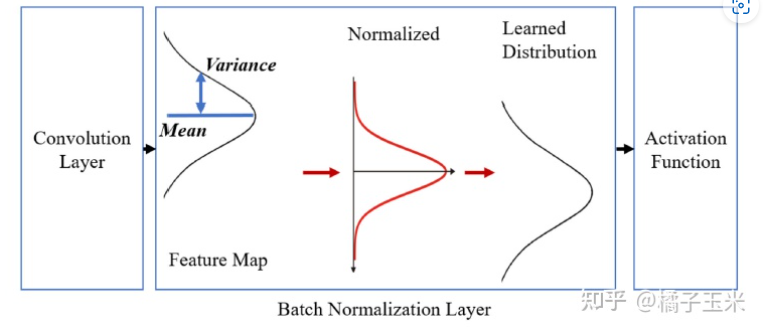
图7 批处理归一化概述
均值和方差参数是近似乘法的误差来源,因为近似乘法的结果会改变卷积输出的分布。当具有平均误差e时,卷积输出分布的均值(u')和方差(o')2如下所示。
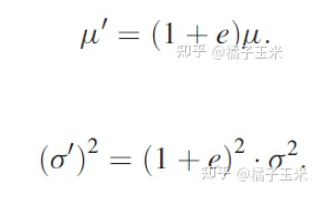
因此,存储的批量归一化的平均值必须缩放(1 + e),方差值缩放(1 + e)2。使用调整后的参数,批处理归一化层正确地归一化卷积输出,并将其缩小到所需的分布。在此过程中,输出的均值和方差与精确乘法的均值和方差一致,平均误差累积的影响消失。如果不能调整这些参数,就会导致特征图的重新分配不正确,CNN的准确性也会下降。该方法只需要对存储的参数进行缩放,并显著提高了深度神经网络上近似乘法器的性能。它不引入任何新的操作,也不阻止批处理归一化折叠到相邻层的能力。







