选自hackernoon
作者:Chanchana Sornsoontorn
参与:朱朝阳、微胖、高静怡
GAN 暨生成对抗网络(Generative Adversarial Networks)是由两个彼此竞争的深度神经网络——生成器和判别器组成的。
生成器和辨别器的目标是生成与训练集中一些数据点非常相似的数据点。
GAN 是一个非常强有力的想法。甚至 Yann LeCun 都称赞道这是近 20 年最酷的想法。他希望是自己发现了 GAN 而不是 Ian Goodfellow。
目前,人们利用 GAN 可以完成不同种类的生成任务,它能够生成现实中的图片,三维模型,视频和其他更有价值的成果。
GAN 的生成样例

生成类似于 MNIST 数据库的手写数字图片——甚至连人类都无法区别生成的图片和真实图片

使用 StackGAN 基于文字描述生成图片

使用 DCGAN(深度卷积对抗生成网络)生成人脸

使用 DCGAN (https://github.com/mattya/chainer-DCGAN) 生成动漫人物
利用一张静止的图像预测下一帧图像
生成三维模型
除了生成实物外,你还能基于抽象的想法做算术运算,比如摘掉人脸上的眼镜!
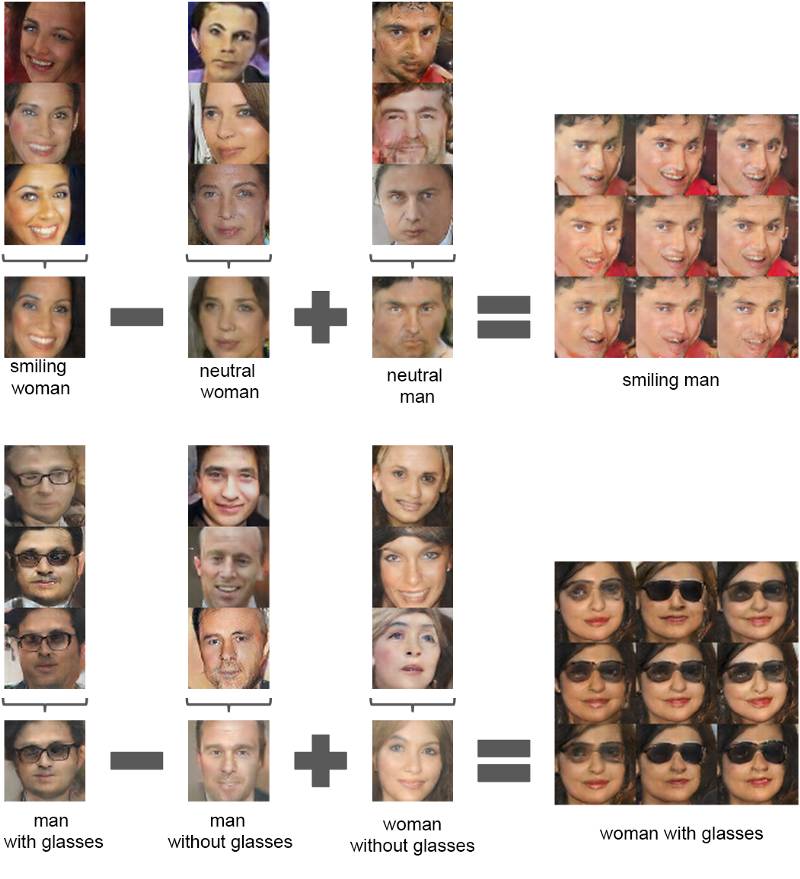
面部的数学运算: DGGAN-code (https://github.com/Newmu/dcgan_code#arithmetic-on-faces)


那么添插图片会怎样呢?
给定两张图片,它能生成从一张图片转化成另一张图片这个过程的所有图片。
还有许多你能
让人印象非常深刻,不是吗?
GAN 背后的理念
举个例子吧,假设我们想让 GAN 生成类似于训练集(如 CelebA 数据库)中的人脸图片
我们生成器的架构可能会像下面这样:

对于一个 DGGAN 生成器而言 , 输入是一个随机法向量并通过反卷积栈输出图像
辨别器
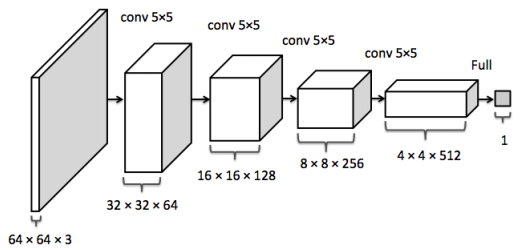
辨别器的输入是一张图片,通过卷积栈后输出这幅图是否为真的概率
我们的整个 GAN 架构将会是这样的:
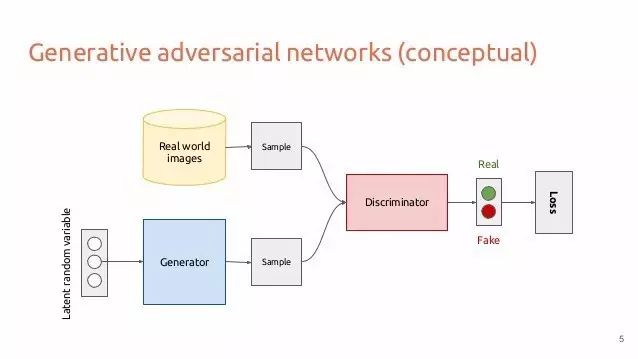
GAN 架构
「生成器努力生成让辨别器认为是真的假图片。然后当一张图片输入时,辨别器会尽最大的努力试着辨别真的图片和生成的图片」
生成器和辨别器会共同进步直到辨别器无法辨别真实的和生成的图片。到了那时,生成式对抗网络只能以 0.5 的概率猜一下哪张是真实的哪张是生成的,因为生成器生成的人脸图片太真实了。
官方 GAN 论文:
生成模型可以被看作是一队伪造者,试图伪造货币,不被人发觉,然而辨别模型可被视作一队警察,努力监察假的货币。游戏当中的竞争使得这两队不断的改善方法,直到无法从真实的物品中辨别出伪造的。
在理想最优状态,生成器将知道如何生成真实的人脸图片,辨别器也会知道人脸的组成部分。
最优生成器
直观来说,之前在生成器中展示的代码向量将会代表抽象的东西。例如,如果代码向量有 100 维度,可能会由一维自动代表了「面部年龄」或「性别」。
为什么生成器会学习到这种表示呢?因为知道了人们的年龄和性别会帮助你画出更适合他们的人脸图片。
最优辨别器
给定一张图片,辨别器必须找到正确区分真实和生成的人脸的部分。
直观上说,当辨别器中的一些隐藏神经元看到比如眼睛,嘴巴,头发等物体时,他们就会被激活。这些特征对之后的其他任务比如分类是很有用的。
如何训练
我们共同训练生成器和辨别器,让他们变得强壮,通过反复训练防止其中一个网络比另一个网络强大太多。
为什么轮回训练网络使双方共同变强而不是单独训练让他们的性能更强大?










