在数据分析和机器学习领域,聚类作为一种核心技术,对于从未标记数据中发现模式和洞察力至关重要。聚类的过程是将数据点分组,使得同组内的数据点比不同组的数据点更相似,这在市场细分到社交网络分析的各种应用中都非常重要。然而,聚类最具挑战性的方面之一在于确定最佳聚类数,这一决策对分析质量有着重要影响。
虽然大多数数据科学家依赖肘部图和树状图来确定K均值和层次聚类的最佳聚类数,但还有一组其他的聚类验证技术可以用来选择最佳的组数(聚类数)。我们将在sklearn.datasets.load_wine问题上使用K均值和层次聚类来实现一组聚类验证指标。以下的大多数代码片段都是可重用的,可以在任何数据集上使用Python实现。
接下来我们主要介绍以下主要指标:
-
Gap统计量(Gap Statistics)(
!pip install --upgrade gap-stat[rust]
)
-
Calinski-Harabasz指数(Calinski-Harabasz Index )(
!pip install yellowbrick
)
-
Davies Bouldin评分(Davies Bouldin Score )(作为Scikit-Learn的一部分提供)
-
轮廓评分(Silhouette Score )(
!pip install yellowbrick
)
引入包和加载数据
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snspd.set_option("display.max_columns", None)pd.set_option("display.max_rows", 200)from sklearn.preprocessing import StandardScalerfrom scipy.spatial.distance import cdist, pdistfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_scorefrom yellowbrick.cluster import KElbowVisualizer, SilhouetteVisualizerfrom sklearn.cluster import AgglomerativeClusteringfrom scipy.cluster.hierarchy import dendrogram, linkage, cophenetsns.set(color_codes=True)
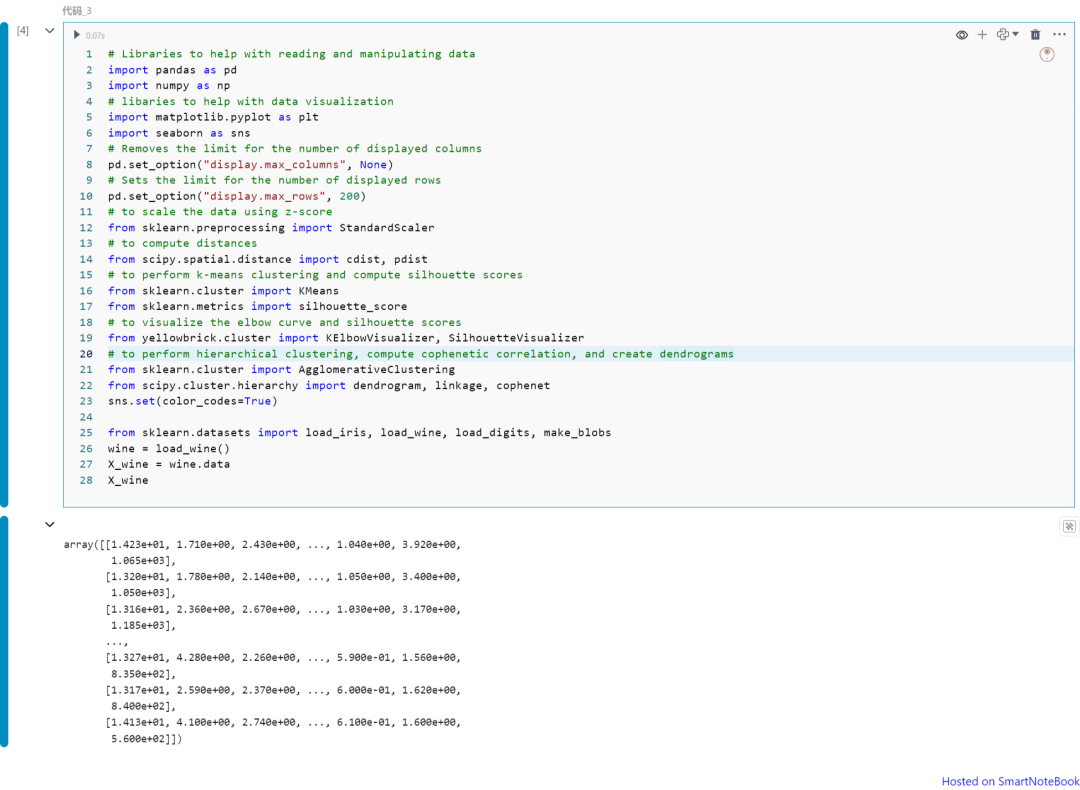
from sklearn.datasets import load_iris, load_wine, load_digits, make_blobswine = load_wine()X_wine = wine.dataX_wine
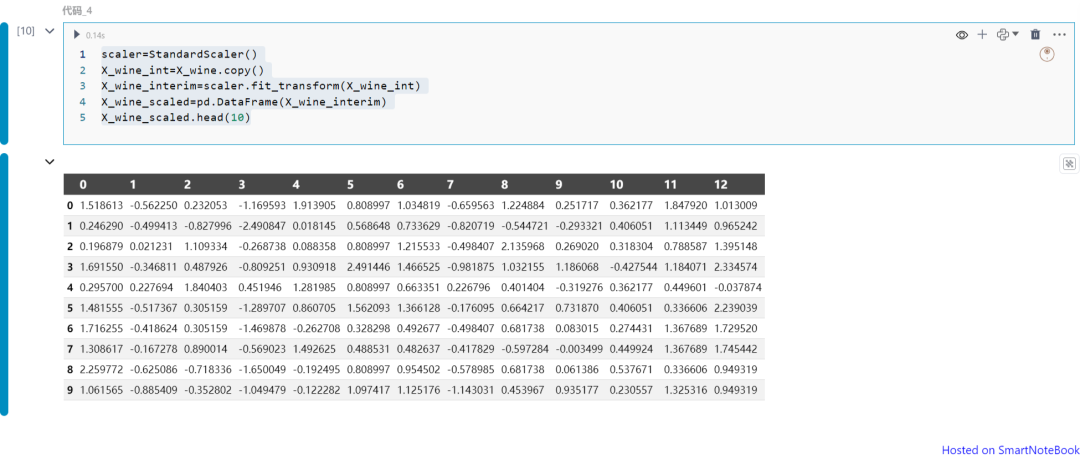
标准化数据:
scaler=StandardScaler()X_wine_int=X_wine.copy()X_wine_interim=scaler.fit_transform(X_wine_int)X_wine_scaled=pd.DataFrame(X_wine_interim)X_wine_scaled.head(10)
Gap统计量(Gap Statistics)

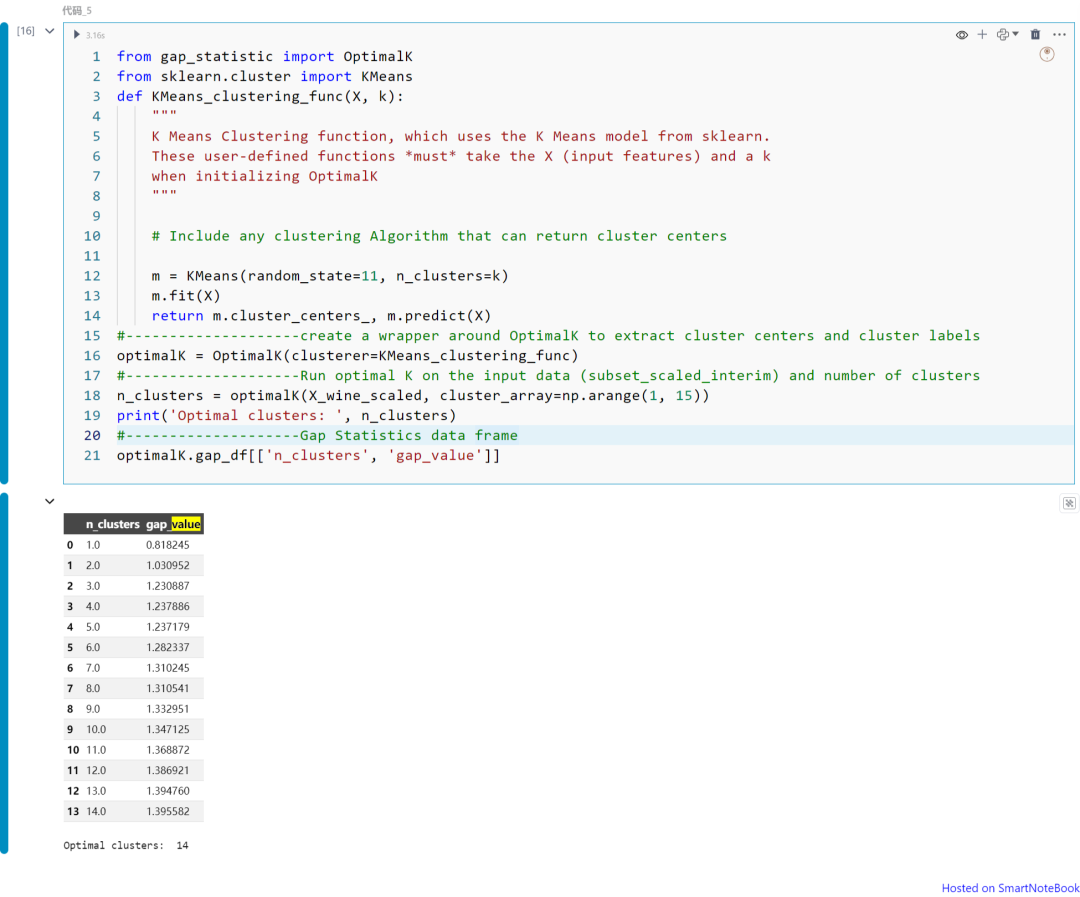
from gap_statistic import OptimalKfrom sklearn.cluster import KMeansdef KMeans_clustering_func(X, k): """ K Means Clustering function, which uses the K Means model from sklearn. These user-defined functions *must* take the X (input features) and a k when initializing OptimalK """ m = KMeans(random_state=11, n_clusters=k) m.fit(X) return m.cluster_centers_, m.predict(X)optimalK = OptimalK(clusterer=KMeans_clustering_func)n_clusters = optimalK(X_wine_scaled, cluster_array=np.arange(1, 15))print('Optimal clusters: ', n_clusters)optimalK.gap_df[['n_clusters', 'gap_value']]
plt.figure(figsize=(10,6))n_clusters=3plt.plot(optimalK.gap_df.n_clusters.values, optimalK.gap_df.gap_value.values, linewidth=2)plt.scatter(optimalK.gap_df[optimalK.gap_df.n_clusters == n_clusters].n_clusters, optimalK.gap_df[optimalK.gap_df.n_clusters == n_clusters].gap_value, s=250





