人生的博弈,输赢不是最重要的,但狗生的博弈就是要赢!

今天将进行柯洁和AlphaGo对弈三番棋的最后一局,下午对局结果出来后,恐怕再鲜有这样的人机对弈了。
在这之前,AlphaGo已经和柯洁对弈过两局,和古力、连笑配对赛一局、和五大高手团队赛一局。四局比赛均是AlphaGo胜,棋下到这,AlphaGo开始展现出了更多让人疑惑不解的下棋风格。
比如
官子退让
。
AlphaGo在中盘走棋的风格都是很强势的,但是到了官子阶段,表现往往大跌眼镜。
到底是Bug还是“故意放水”,我们先了解一下这个让狗非常纠结“官子”到底是什么。
所谓官子,也就是收官的意思,“收官”这个词也是这么来的,跟一场球、一个大会、甚至一个自然年一样,一场围棋进入官子阶段的时候,就是快要结束的时候,这个时候,大局基本已定,只需要处理一些零碎的事物。
对于一盘棋来说,就是处理一些零碎的空地
。专业点的说法也叫“
详细点目
”。
下围棋就是一个占地盘的过程,每走一步棋的目的,都是希望能拥有更大的地盘。等到棋越下越多,大的空地已经被抢完,双方就要从小的空地入手,这时候就是在收官子。
虽然中盘被认为是确立胜负的关键,但高手对弈的时候,即便在官子阶段也不会掉以轻心,因为
棋没有下到最后一步,谁也不知道会发生什么
,对手随时有可能在官子翻盘。
在23日和柯洁对弈的第一局比赛的官子阶段,面对柯洁的强硬招数,AlphaGo反而一改之前的凶悍,变得非常保守,能让的子都让了。
在26日的团队赛中,面对五位围棋高手,AlphaGo依然取胜,但是仍在官子阶段给了对手机会,并且规避一切复杂变化。甚至在小官子阶段走出了看起来完全没用的棋,被团灭的五大棋手哭笑不得,甚至代为执棋的黄博士都忍不住要笑了。

这不是AlphaGo第一次出现这种“事故”。
今年一月AlphaGo化身Master键盘侠在网上横扫各大高手的时候,就常在官子阶段退让,芈昱廷和朴廷桓都曾仅以半目惜败。这造成人类棋手在官子阶段比AlphaGo强的印象:失了中盘,也总能在官子追回一二吧。
此前日本围棋老将赵治勋和日版阿法狗DeepZenGo进行对局的时候,柯洁就在微博上给赵治勋提建议:
“和AlphaGo拥有同样技术的ZenGo,私底下我有一定的了解。我其实一直在研究、与别人探讨,深度学习技术的计算机到底有何弱点,也亲自实战过。如果赵老能看的见我的微博,请留心我的建议:无论局面如何都不要认输,拖到官子,刮爆它。”
在Zen的身上,柯洁认为官子阶段是弱点。
但也有很多人认为,在官子阶段,人类棋手虽然还在对棋盘上剩下的领地焦灼,但是狗已经认准了自己能赢。所以才一再退让,狗其实就是故意在让子。

至于狗为什么会在官子处处退让,大家此前有很多猜测,不过大致集中在两个方向上:
猜想一:你们都以为围棋下到官子就简单了,但实际官子才是对AI来说最难的。
人的“棋感”是多年的走棋的经验判断,AlphaGo的“棋感”则是神经网络训练的结果。首先通过策略网络缩小落子的选择范围,然后通过穷举搜索模拟走棋到一定程度,这时候会生出许多可能性的分支。
但是这些分支太多,即便对于能力再强大的计算机来说也是过重的负担,所以要进行“剪枝”,通过价值网络评分,权衡比较,剪掉没用的支,选择一个最能赢的点。
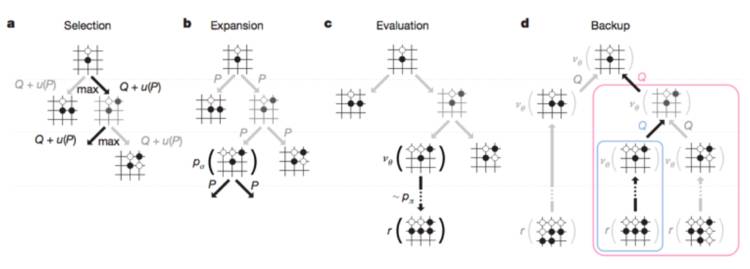
在布局和中盘阶段,棋子落在不同的地方,导致的后果是很不一样的,长枝和短枝差得多,剪起枝来非常方便,同时计算的负担也会小很多。
但是官子带来的困惑就多了,官子阶段,棋盘上到处都是棋子,到处都是子力(每一个棋子给外界带来的影响)。对于算法来说,可以选择的点越来越多,并且这些点之间的差距越来越小。
所以,看似棋局接近尾声,对于人类棋手来说,可能棋局是越来越明朗,但是对于对于算法来说是越来越困惑。
在这个时候如果盲目剪枝,就可能会遗漏有价值的落子点。但是如果扩大选择范围,又会带来大量搜索和计算的负担。
最后导致AlphaGo在官子阶段漏洞百出。
猜想二:狗的策略是“赢不贪多”。
AlphaGo寻求的是简明处理,也就是说,在模拟出来的众多胜利之路中,找到第一条胜率更大的路一直走到黑。
可以假设,AlphaGo在棋盘上找到了1000种赢的可能,但是有990种都是只赢半目,只有10种可以赢十目。
按照既定的策略,也就是价值网络评分的标准,狗会选择最保守但能确保获胜的那990种棋。赢的多少,并没有作为AlphaGo价值判断和打分的目标。
如果一个点收官可能赢50目但有50%的几率崩盘,另一个点可以赢5目但100%取胜,胜率优先原则永远是后者,不是故意退让。
到底AlphaGo如何能保持精准的只赢半目,在25日第二局比赛结束的发布会上,DeepMind创始人Demis Hassabis给出了标准答案:
“第一盘棋的官子阶段,AlphaGo在做的只是让自己的
胜率最大化
,因此在比赛的最后阶段,可能会在某些局部的点做一些放弃,AlphaGo只是专注于胜率,其它并不重要。 ”
所以正确答案是猜想二,包含一些猜想一的猜测,
整个狗在下整盘棋的时候,是一个很复杂的计算过程,但是它的目标是很简单的,就是保证能赢,为此可以放弃一些局部。
甚至可以反过来应用这个规律,只要在官子阶段狗开始步步退让,就说明它已经赢了。
所以为什么不在AlphaGo的程序中写入一个“赢越多越好”的目标呢?
被当做故意放水,狗也很委屈,如果想要保证每盘即能赢,又能赢得多,还要看工程师是否能加上一个“赢几目”的补丁了。
等等,这样的补丁原来也是有的!
有一种叫做Dynamic Komi的东西,翻译过来叫做动态贴目。这个补丁的用途,简单来说就是防止电脑在被让子时下出太保守的棋,AlphaGo的团队曾在一篇论文《Mastering the game of Go with deep neural networks and tree search》中明确指出Alpha Go没有使用动态贴目。









