从 EMNLP 入选论文《Neural Response Generation via GAN with an Approximate Embedding Layer》出发,就自动对话领域的特点到发展方向和亟待解决的问题,我们与三角兽首席科学家王宝勋聊了聊。

三角兽首席科学家王宝勋
限于闲聊的、无信息需求的对话生成是自动对话领域一个比较前沿的学术方向。在应用方面,生成式聊天相比于前一代的基于信息检索的(IR-based)架构也有一些天然的优势:它不需要维护大规模问答库,也不需要排序、筛选等子模块,这种更加一体化的构架,在部署上也很有实际意义。
然而,生成式聊天也有自己的弱点:因为模型通常以相关性为核心构建损失函数,所以非常容易生成严重趋同的答案,这种现象被称为「安全回答」问题(safe response)。一句「我也这么认为。」确实可以回复许多问题,但是这样「鸡肋」的回答难免让用户失去继续聊下去的兴趣。因此,生成式对话系统在获得大范围应用前,一定要解决安全回答问题。
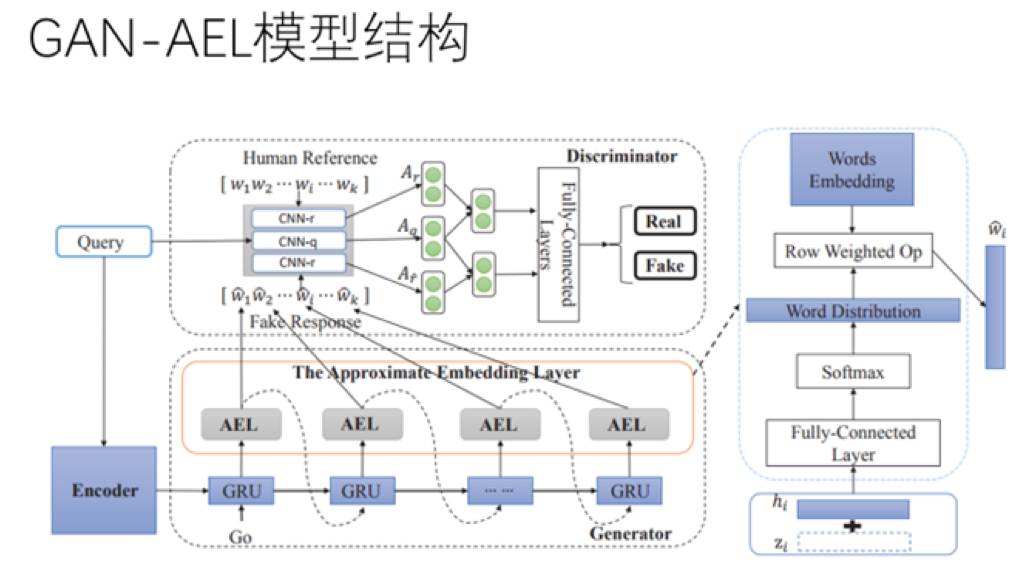
三角兽与哈工大合作的这篇论文(GAN-AEL)就旨在通过生成对抗网络解决这个问题,让生成器考虑「相关性」问题,同时,引入具有对抗属性的判别器,把「多样性」也纳入考量之中。实现这个思路的障碍来自生成对抗网络和自然语言本身的特性。生成对抗网络成功用于图像领域有赖于图像信号的连续特点,然而文本信号是离散的,离散意味着不可导、意味着判别器的信息无法顺利通过反向传播到达生成器。因此,作者提出了一种新的结构:近似嵌入层(Approximate Embedding Layer, AEL)来获得判别器和生成器中间的连续性。
论文:数据需求特点与模型结构选择
在数据需求方面,生成式对话系统相比于信息检索式的对话系统,乃至于神经机器翻译系统,有哪些不同呢?对此,王宝勋表示,首先相比于信息检索式架构,生成模型在训练阶段对数据量有较高需求,然而一旦学习结束,在理想状态下就可以直接端到端地生成答案,不需要再对数据进行维护。而相比于机器翻译,虽然对话数据比翻译常见,可以从论坛、贴吧等众多途径获得,但是数据质量远远不如翻译数据。以本文所提出的模型为例,相比于神经机器翻译,在数据体量上要求较低而在质量上要求较高。数量上要求低,是因为对抗的过程在不停地生成数据,这一轮和下一轮生成的样本可以被看成是不同的样本。质量上要求高,是因为模型的目标是避免安全回答,因此从一开始就要对数据进行严格的预处理,避免数据集中出现安全回答。
在模型结构上,生成器选择了基于 GRU 的编码器-解码器结构,判别器选择了 CNN。GRU 虽然不像 LSTM 那么明确地有不同门负责不同任务,但从实践效果来看,两个模型效果相差不多,因此最终选择参数较少的 GRU。选择 CNN 则和近似嵌入层(Approximate Embedding Layer, AEL)的引入有关。这一层在做句子表示时,虽说有近似,但还是以词的嵌入(embedding)向量串联的形式来表示一个句子。在这之上,可以做一些其他的表示,甚至可以直接加在一起。但是根据以往的经验,分类器还是用一个不太深的 CNN 比较好。虽然没有纯理论的推导,但经验上表明,对于对抗学习这种架构来说,判别器不能太强。如果判别器过强,一下子就把两类样本分开,说明生成的样本对判别器来说没什么太大挑战,判别器也无法给生成器提出什么建议,导致误差传导、生成器底层更新的频率和幅度都会小一些。因此生成器和判别器在学习速度上还是要相匹配的。
对话生成研究:一对多问题,缺失的评价标准和多轮的挑战
「人机对话之前都是自然语言处理领域稍微小众的一个方向,但是今年的 ACL 收录了超过十篇做对话的论文,这个数字是前所未有的」。研究方向的热度随着人工智能整体的热度而急速攀升,即使是走在最前沿的研究者也对此感到惊讶。处在这样的一个时间节点,王宝勋眼里的对话生成领域是什么样子?研究的挑战在何处,不同的处理方式的特点是什么,又如何对成果进行客观评价?
在开放域闲聊对话中,一个问题对应多个可能答案的情况很常见。王宝勋解释道,一对多现象会对模型产生一些挑战是因为它会引入语义上的不确定性。相比之下,机器翻译虽然也存在一对多现象,但是多种翻译在语义上基本上是平行的。在问答或者聊天任务上,没有办法保证每一个答案在语义上的一致性,这种语义上的漂移会对机器学习模型产生很大挑战。
统一的评价标准的缺失也很让研究者头疼。机器翻译中的 BLEU、迷惑度(perplexity),乃至文本摘要任务的评价标准都会被聊天系统借用。「引入一个行业通行的标准很有必要」,王宝勋肯定地说。但和问答、翻译、文摘等几个领域一样,如何将主观性的东西进行量化,始终是一个难题。如果强行引入太多标签,则势必形成不了上规模的应用。什么样的评价标准才是一个好的标准?GAN-AEL 在「相关性」之外引入了「多样性」。除此之外,「延展性」也很重要。延展性评价一个回答能否引发更多轮数的对话,评价用户看到回答之后是否有兴趣继续聊下去。当然了,延展性非常难直接衡量。一个「曲线救国」的办法是在系统上线之后,看用户的 cps(conversation per session)。王宝勋还补充道,比起评价标准缺失,或许更亟待解决的问题是高质量评测集和训练集的缺乏,常用的几个数据集在质量方面参差不齐。
最后,能让用户「多聊几句」的回答才是好回答,而系统从「给用户一个回复」到「多聊几句」,存在一个指数级的难度提高。多轮对话要更多考虑情境、考虑和前文的关联。它和前文哪句话关联?多大范围关联?有潜在关联怎么办?都是需要考虑的问题。然而,多轮对话始终是对话系统绕不开的一个题目。一方面,任务型对话通常都有多轮的需求,因为在一轮以内收集到完成任务所需的所有信息是非常困难的。例如,用户说「我要订饭店」,别的什么都没说,那机器人总要追问,「你要定在哪里?几点?多少人?」。主流的对话系统都会通过对话状态跟踪(dialog state tracking)模块来记录状态的转移,以配合策略(policy)模块。而另一方面,王宝勋也看好聊天在多轮对话上的发展。「一段时间以后,我们也会看到一个相对让人满意的多轮聊天的机制。这个事情不会太远,我对多轮对话相对比较乐观」,他如是说。




