快要过年了,朋友聚会时,经常玩的两个就是“谁是卧底”和“杀人游戏”了。而想在这两个游戏上变现得技惊四座,绝对不能只靠演技,还需要一点概率思维。贝叶斯公式,这个机器学习中最基础的原理,也可以用在指导我们玩好这两个游戏。

首先谈概率,概率这件事大家都觉得自己很熟悉, 叫你说概率的定义 , 你却不一定说的出,我们中学课本里说概率这个东西表述是一件事发生的频率, 或者说这叫做客观概率。
而贝叶斯框架下的概率理论确从另一个角度给我们展开了答案, 他说概率是我们个人的一个主观概念, 表明我们对某个事物发生的相信程度。 如同Pierre Lapalace说的: Probability theory is nothing but common sense reduced to calculation. 这正是贝叶斯流派的核心,换句话说,它解决的是来自外部的信息与我们大脑内信念的交互关系。
两种对于概率的解读区别了频率流派和贝叶斯流派。如果你不理解主观概率就无法理解贝叶斯定律的核心思想。
在谈论游戏之前,先说说贝叶斯统计的一个有趣的案例案例:假如你是一个女生, 你在你的老公书包里发现了一个别的女人的内裤那么他出轨的概率是多少。

图: 贝叶斯分析可以解决家庭纠纷
稍微熟悉这个问题的人对会知道做这个题目你要先考察基率,你要把这个问题分解为几步考虑:
1,你老公在没有任何概率情况下出轨的概率是多少? 如果他是个天生老实巴交的程序员或者风流倜傥的CEO, 那么显然不该一视同仁
2,如果你老公出轨了, 那么他有一条内裤的概率是多少, 如果他没出轨, 出现这个情况概率有多少? 想想一般人即使出轨也不会犯那么傻的错误, 会不会有没出轨而出现内裤的状况? 有没有可能是某个暗恋你老公的人的陷害?
3, 根据1 和2求解最终问题,这才是拥有大学数学能力的你该做的分析。
在这里1其实就是先验概率P(A),而2是条件概率P(B|A), 最终得到3后验概率P(A|B)。这三种即是贝叶斯统计的三要素。
基于条件概率的贝叶斯定律数学方程极为简单:
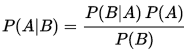
A即出轨, B是内裤出现, 你得到1,2,就可以根据公式算出根据根据内裤出现判断出轨的概率。
先验概率在贝叶斯统计中具有重要意义,首先先验概率即我们在取得证据之前所指定的概率P(A), 这个值通常是根据我们之前的常识,带有一定的主观色彩。 就像刚刚说的出轨的问题, 你的先验概率代表了你对你男人的信心。
同样的道理,你在玩谁是卧底的游戏中,你每拿到一个词,你首先要记住的最重要信息是你这个词是卧底的先验概念,比如6个人在一起玩,一个人做法官,那么你是卧底的先验概率就是1/5。
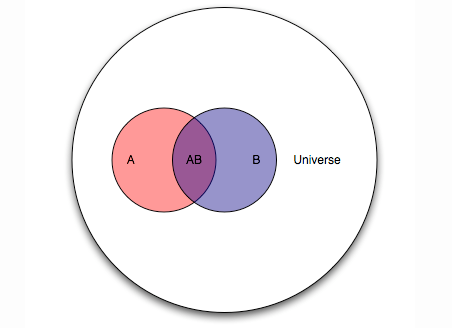
理解贝叶斯分析最好的方法即图像法, 这里的A的面积即先验(你什么都没有听到时对自己是否是卧底的估计), 后验是阴影占蓝圈的百分比(你听到了其他的描述后觉得自己是卧底的概率)。
拿到词之后的第二件要做的事是猜测另一个不同的词(以下称卧底词)是什么,为什么要猜测另一个词了,是为了再你有多种描述这个词语的时候给不同的描述方式排顺序。假设你拿到的词是杨过,你猜测另一个词也是一个武侠小说中的人物,可能是郭靖,也可能是小龙女,还有可能是杨康。那么你根据这些假设,去计算那种描述方式可能会最少的暴露信息。而这里就涉及到香农信息论中的概念,信息的度量方式是看其能消除多少的不确定性。而谁是卧底这样的游戏,就是要在透露信息时尽可能的保留不确定性。所以在第一轮情况未明时,你要说的尽可能的含混。而这时比较哪一个描述方式更好,就需要你设定好一个可能的卧底词的集合,数一数哪一种描述方式排除的卧底词最少。
随着游戏的进行,你会根据别人的描述去调整自己是卧底的概念,如果你足够熟练,还会去判断场上其他人是卧底的概念。怎么更新自己的认识,就是按上文描述的例子,应用贝叶斯公式。同样的,随着新的信息,你也会排除之前认为的可能的卧底词,从而调整自己下一轮该提供哪些信息。
关于怎么玩谁是卧底这个游戏,我们就说到这里,为什么要将一个轻松的游戏这样给出这样烧脑的玩法。主要是我觉得玩游戏不应该只是瞎玩,而要玩过之后去思考,
用游戏中的道理去指导自己的生活
。我最初玩的时候觉得谁是卧底是一款关于维度和发散思维的游戏,你要能从更多的视角,更高的维度,更具想象力的情景去描述一个词,从而不会被迫说的很具体,导致暴露了自己。但相关性的爆炸性性增长需要我们去对其进行排序,而这就需要贝叶斯思维。
谁是卧底这个游戏给我的另一启发就是如果我们的先验概率审定为1或0(即肯定或否定某件事发生), 那么无论我们如何增加证据你也依然得到同样的条件概率(此时P(A)=0 或 1 , P(A|B)= 0或1)。如果你在某一论听到证据后,直接就将一个人认定为了卧底,那么这之后的信息也无法帮助你决策了。 这告诉我们的第一个经验就是不要过早的下论断, 下了论断你的预测也就无法进化了, 或者可以称之为信仰。
你如果想让你的认知进步,就要给各种假设留一点空间。
将这个洞见用在生活中,贝叶斯分析中的三要素(先验概率,条件概率,后验概率)在不同的问题中通常侧重点 , 很多时候我们都是在忽略先验概率的作用,比如描述一个人很书呆子气让你判断他是大学老师还是销售员的经典案例(要看先验大学老师还是销售员哪个多啊)。 但是有时候我们也不理解条件概率, 比如著名的辛普森案, 为了证明辛普森有杀妻之罪,检方说辛普森之前家暴,而辩护律师说,美国有400万女性被丈夫或男友打过,而其中只有1432人被杀,概率是2800分之一。 这其实就是勿用了后验概率, 这里的条件是被杀而且有家暴,而要推测的事件是凶手是男友(事实上概率高达90%),这才是贝叶斯分析的正当用法, 而辩护律师却把完全在混淆条件与要验证的假设。

贝叶斯分析可以还理解一些常用的现象, 如
幸存者偏差
,你发现一些没读过书的人很有钱,事实上是你发现就已经是幸存者了(对应上图中小红圈), 而死了的人(红圈外的大部分面积)你都没见到啊。还有
阴谋论
, 阴谋论的特点是条件很多很复杂, 但是条件一旦成立,结论几乎成立, 你一旦考虑了先验,这些条件成立本身即很困难, 阴谋论不攻自克。
贝叶斯分析的框架也在教我们如何处理特例与一般常识的规律。
如果你太注重特例(即完全不看先验概率) 很有可能会误把噪声看做信号, 而奋不顾身的跳下去。 而如果恪守先验概率, 就成为无视变化而墨守成规的人。其实只有贝叶斯流的人生存率会更高, 因为他们会重视特例, 但也不忘记书本的经验,根据贝叶斯公式小心调整信心,甚至会主动设计实验根据信号判断假设。
除了指导我们过好生活,上面描述的也还是贝叶斯决策的一部分。
贝叶斯决策主要包含四个部分: 数据(D), 假设(W),目标(O),决策(S)。 此处的数据即之前讲到的证据, 假设是我们要验证的事实, 目标是我们最终要取得优化的量, 决策时根据目标得到的最后行为。 与上一步贝叶斯分析增加的部分是目标和决策。假设在问题里如果是连续的往往以参数空间的形式表达。
然后我们可以按照如下步骤做:
第一, 理清因果链条, 哪个是假设, 哪个是证据
第二,给出所有可能假设 , 即假设空间
第三,给出先验概率
第四,根据贝叶斯概率公式求解后验概率, 得到假设空间的后验概率分布
第五,利用后验概率求解条件期望, 得到条件期望最大值对应的行为
贝叶斯决策如果一旦变成自动化的计算机算法, 它就是机器学习。 Ok, 此处应有掌声,我们就用贝叶斯决策诠释一个最简单的机器学习分类算法- 朴素贝叶斯
假设给你一个人的身高和体重资料, 你不知道他的男女性别, 你可以通过我上述给出的贝叶斯决策机制解决这个问题: 首先, 此处我们的证据是身高和体重, 假设是男或女。 先验概率是人口中的男女比例, 而我们需要掌握的条件概率是男性和女性的身高和体重分布, 这应该是很好掌握的信息。 然后我们可以根据贝叶斯公式求解后验概率, 而此处我们要做的决策时男女, 目标是分类错误率最低, 决策即性别分类。
此处我们用到一个基本假设就是证据是互相独立的, 使我们能够求得更简单的公式:
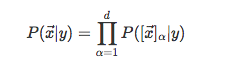
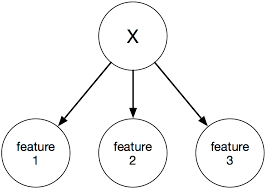
图: 朴素贝叶斯,核心在于假设证据互相独立。
用数学语言白表征这个问题, X特征向量,h把X映射成不同的分类, 我们要求得是P(y|x) 正确率最大的假设(y)。
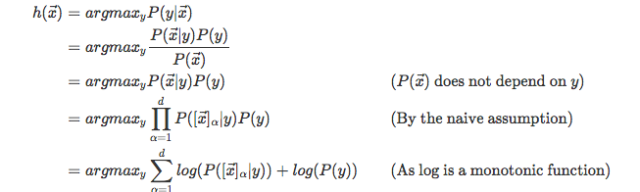

图:贝叶斯决策理论是构建有监督机器学习算法的重要基石, 比如上面的性别问题我们可以在训练部分根据已有数据求出不同性别身高和体重的概率分布,而在测试部分用朴素贝叶斯分类器进行决策。
事实上, 贝叶斯决策很少只涉及A和B, 而是内部包含非常关键的隐变量(参数),涉及我们对所研究事物的一些基本预设。比如下面这个特别简单的例子:
抛掷硬币,
一个硬币被投掷
10
次
9
次朝上,那么根据频率学派的观点,
得到第
11
次投掷的概率不变为0.5
,如果你回答了0.9, 你经常会被看成一个傻X。
其实不然, 天底下哪有一样的硬币呢? 那么问题来了,我设一个赌局, 一次正面向上你可以受益100, 反面惩罚150, 基于刚才的事实你要不要做这个局?
我们完全可以套用贝叶斯决策的理论来。
这里的一个重要的隐变量是每一次投掷硬币的概率,这个数字按照经典频率学派认定一定是
0.5
,
而按照贝叶斯学派的观点,
需要把这个变量看成是未知的,具有一定先验概率,之后严格按照贝叶斯公式计算新加入证据对先验概率的影响。此处的先验概率即你对硬币向上0.5这件事的信念, 你越相信这个事实, 这个分布越尖,反之越宽广。 我们用希腊字母theta来表征这个概率。整个决策表述如下:
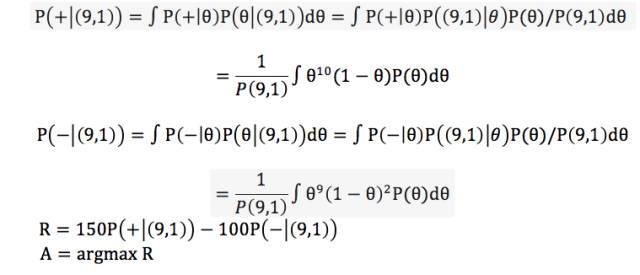
公式的含义是你要用求解已知9次朝上1次朝下的时候求解你下一次投掷硬币的期望收益, 并因此决策要不要赌。 中间要验证的假设空间即每一次投掷为正的概率,我们依然以每次事件独立和该概率不随时间变化为基准(如果不是问题将无限复杂), 那么证据将根据上述公式改变
假设空间的概率分布
, 而最终的期望可以根据这个分布求出。 决策即使得这个期望最大的解。
注意此处先验十分重要,因为它影响决策的结果, 而这又是一个很主观的东西,如果你对0.5有绝对的信心, 那么你的就会非常尖,这个时候你需要得到大量偏离0.5的证据才能逐步纠偏。 对于书呆子样的人, 估计会倾向给出一个比较尖锐的先验分布,相信书里说的0.5而不赌, 而一些更加倾向于相信特例的人则会给出很平坦的先验而更大的概率去赌。 最终后者发财和倾家荡产的几率都比较高,而前者比较容易旱涝保收。当然, 在数据量超大,比如说1000次有900次为正的情况下, 我们几乎不需要考虑先验(自己去看公式),此时几乎可以认定投掷的概率就是0.9.
图:证据对信念发生作用的贝叶斯过程
贝叶斯网络:
如果我们的贝叶斯决策中牵涉的证据更复杂呢? 如果这些证据之间不是简单独立而是互为因果呢? 这时候更为强大的工具-贝叶斯网络就应运而生。世界上的事无一不处于复杂的联系之中, 而贝叶斯网络正是刻画这种关联的数学表述
构建一个贝叶斯网络的关键方法是图模型 , 构建一个图模型我们需要把具有因果联系的各个事件用箭头连在一起。 下图的例子是这样一个事件, 我们看到草坪湿润了, 那么我想推测此时天气多云的概率 ,因为导致草坪湿润的原因有下雨或者洒水车在工作, 而这两者又都和多云有联系,那么我们可以画出如下图形,按照贝叶斯概率公式逐级推出每个事件的概率。
贝叶斯网络的特性是,当某点的一个证据出现, 整个网络中事件的概率都变化, 所谓看到镜中的一丝百发, 就改变你对人生中所有重大事件概率的推断。
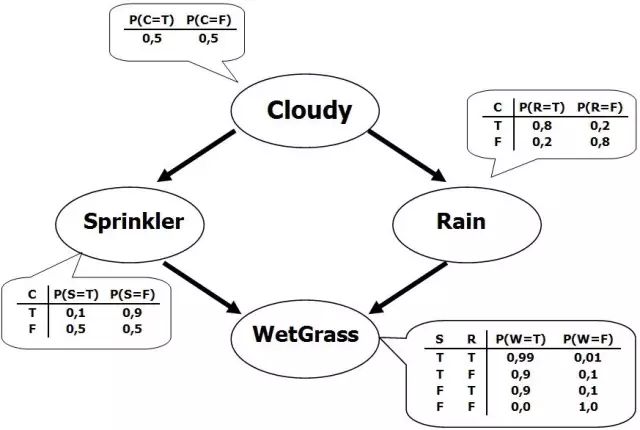
我们的大脑 : 有人说我们的大脑是一个贝叶斯网络, 这句话又对又不对 ,我们的大脑学习的原理,的确正是一个新的证据逐步和内部信念耦合的过程,本质即贝叶斯网络,但是我们大脑又是一个不完全的贝叶斯推断机, 每个人都有一个顶层以三观构建,底层逐步深入个个关于具体问题看法的贝叶斯网路, 但是我们却很少有能够通过一个证据更新整个网络的能力,或者是我们吸收新证据的速度也往往十分缓慢,这是为什么我们经常具有自相矛盾的信念体系,经常一方面喊着人性解放一方面又崇拜偶像。梧桐一叶又有几人知秋。
扩展阅读
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
贝叶斯理论在医学数据分析中的应用





