基础准备
前面我们详细介绍了二元Logistic回归分析的内容,从回归分析原理、哑变量设置、生活实例应用到模型拟合效果判断:
二元逻辑回归分析的因变量是二分类的数据,那么三分类、四分类这样的多分类数据作为因变量,如果何用逻辑回归分析来建立回归模型呢?在介绍多分类因变量的多元逻辑回归模型之前,草堂君在这里需要先强调一点,多分类数据根据数据是否存在大小顺序被分为有序多分类(定序数据)和无序多分类(定类数据),它们的逻辑回归原理是不同的。今天我们先来介绍有序多分类数据的逻辑回归。
有序多元逻辑回归
生活和工作中,经常会遇到因变量是有序多分类数据,例如,城市综合竞争力等级可以划分为低、中、高;收集APP的打开频率可粗略划分为天天看、经常看、偶尔看和从来不看;疾病的治疗效果分为痊愈、有效、好转、无效等。如果希望将这些定序型数据作为因变量进行逻辑回归分析,我们称为有序逻辑回归分析。
有序多元逻辑回归分析的原理是从二元逻辑回归分析上衍生出来的,它最终的拟合结果是因变量水平数减1个Logit回归模型,因此也称为累积Logit模型。例如,因变量是4个水平的定序数据,4个水平的取值分别定为1,2,3,4,它们发生的概率定为p1、p2、p3和p4,那么该有序多元逻辑回归模型可以写成下面的形式:
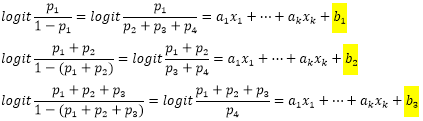
对于上面的式子,其实和二元逻辑回归的模型式子是一样的,只不过多元逻辑回归将因变量的多个类别拆分成几个模型式子来解读而已。同时,因为因变量是有序的定序数据,所以有序逻辑回归模型产生的几个模型的因变量概率是递增的,也就是有序结果的累积概率,因此有序逻辑回归模型也称为累积逻辑回归模型。
比较上面的三个式子,可以发现三个模型的自变量个数和回归系数都是相同的,唯一的区别在于常数项,也就是说所有自变量对因变量不同类型结果的影响趋势是相同的,只是截距不同而已。这也是有序逻辑回归模型的建立的基本假设前提。通过上述模型,就可以求出因变量中每种结果的概率值:
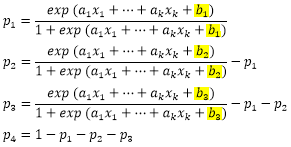
案例分析
某学校的管理学教授最近开展了一个课题,希望研究某三线城市人群对所从事的工作是否满意,根据前期的调研结论,课题组筛选出可能的影响因素有4个,分别是年龄、性别、年收入和文化程度。为了拉开区分度,因变量满意度被分为三个水平:不满意、中立和满意。通过问卷调查的方式,共回收了6400份有效问卷,将数据录入SPSS如下:
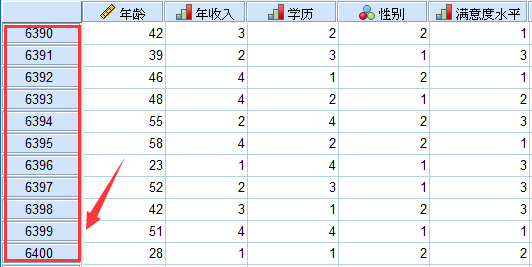
(例题数据文件已经上传到QQ群,群号请见文章底部温馨提示)
分析思路
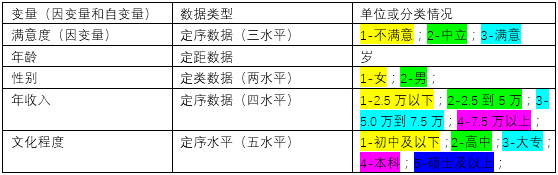
在做回归分析之前,对自变量的含义和类型需要有清楚的了解。我们可以将因变量和自变量的类型和分类情况列成情况表,这样就非常方便进行查询和回顾:
操作步骤
1、选择菜单【分析】-【回归】-【有序】;跳出有序回归对话框,将满意度水平选为因变量,将定序和定类变量选为因子,将定距变量选为协变量。选入因子框内的自变量将会自动产生哑变量进入模型。协变量的则直接进入模型。
大家会发现,有序逻辑回归中不涉及自变量的筛选,这是因为有序回归产生的多个模型需要满足平行假设,即自变量的个数和回归系数相等,所以这里没有设置自变量进入模型方法的选择下拉框。

2、点击输出,然后按照下图进行选择。其中在保存变量里,我们为了更好的判断模型的预测效果,将所有的四项都选中。这些结果都将以新变量的形式保存在原来的数据集中。平行线检验输出的是两个有序逻辑模型的自变量和自变量系数是否相等的检验结果。
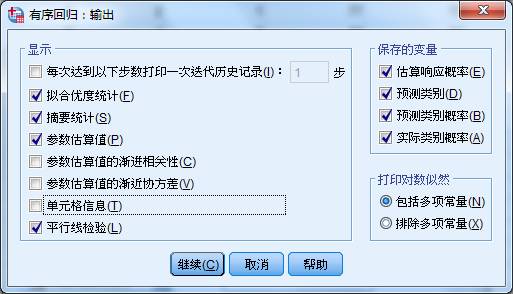
3、点击继续,然后点击确定,输出结果。
结果解释
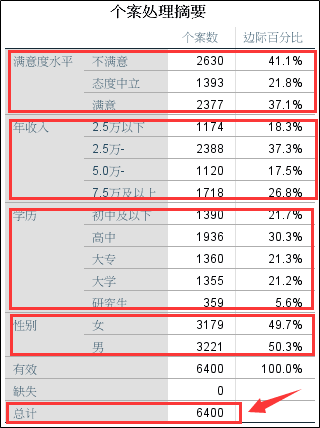
1、个案处理摘要;该表格显示的是选入因子框中的分类变量,以及每种类别的个案数和比例。可以看到该数据总共包括6400条有效数据。
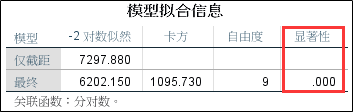
2、模型的似然比检验结果。可以发现显著性概率小于0.01,说明建立的有序逻辑回归模型中至少有一个自变量对因变量的影响是显著的,也就是说模型有效。
3、拟合优度和伪R方结果
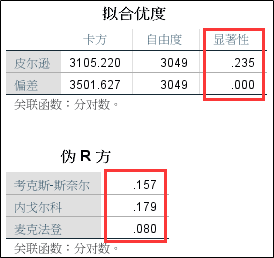
前面介绍逻辑回归基础的文章中提到过,因为模型拟合的方法是极大似然法,伪R方的值通常都是不高的,不能武断的根据伪R方的值认定模型效果不佳。此外,因为本案例中含有年龄这个连续型变量,很多交叉单元格内的个案数是0,而皮尔逊和偏差这两种拟合优度检验方法对此是非常敏感的,因此这两个数据不一致也不要太在意。
4、回归系数表;
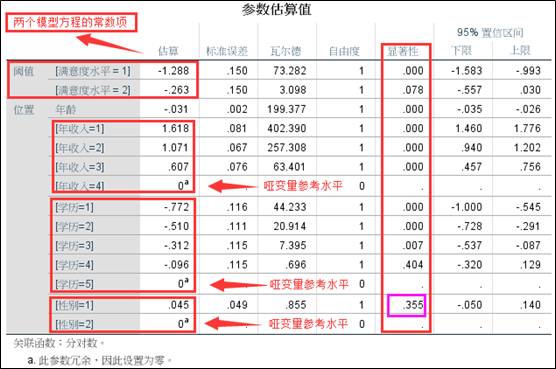
从结果可知,三个分类自变量都是以数值代码最高的类别作为参考水平来产生哑变量的。根据回归系数表可以建立该案例的两个逻辑回归方程。

从回归系数的瓦尔德检验结果可以知道,除了性别以外,其它自变量的检验结果都是显著的,大家可以删除性别变量再做一次分析,看看结果是否更好。
5、平行线检验结果
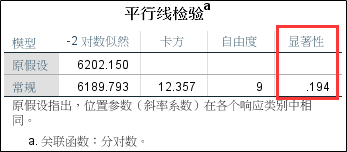
有序逻辑回归分析的前提是产生的n-1个模型,它们的自变量类型和自变量系数是相同的,区别只在于常数项不同。平行线检验的目的就是验证n-1个模型是否符合这个假设条件。如果不符合那就需要用无序逻辑回归模型来分析了(下一篇文章介绍)。从分析结果来看,本案例的两个模型是服从这个假设条件的,显著性大于0.05。
6、模型的预测结果;
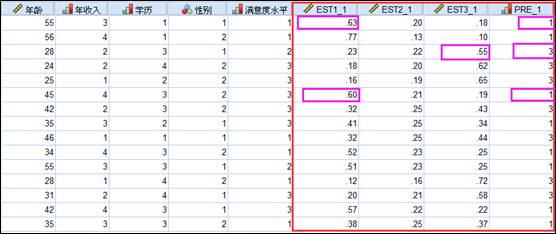
系统保存了四个新变量,EST1_1、EST1_2、EST1_3分别存储的是通过有序逻辑回归模型,每个数据个案发生因变量三种类型结果的概率,PRE_1存储的则是每个个案最终的判断结果,判断依据就是那种类型的发生概率最大,就选那种类型。大家可以用PRE_1的结果与满意度水平(因变量)的结果对比,看看模型的预测结论是否准确。
所有例题的数据文件都会上传到QQ群中,需要对照练习的朋友可以前往下载,QQ群号见下方温馨提示。
温馨提示:









