续前文:
4U8路服务器:将性能扩展到每一英寸
——8路互联架构作为目前开放架构下的最强体系,在x86的服务器和GPU领域都是顶尖的存在。CPU和GPU面对的是不同的工作负载,CPU面对的依然是通用计算,而8路CPU服务器更是直接面对高性能主机领域;而GPU则是随着AI热潮快速发展起来的大规模并行计算领域,通过海量算法模拟行为的计算。
有这么一个比喻:
CPU是数学教授,可以进行复杂的公式计算;GPU是小学生,加减计算都很熟练;
一名教授算1000道加法题,需要一道一道的算;1000名小学生算1000道加法题,一人一道,瞬间完成。
当需要更多公式计算的复杂数学问题时,小学生就比不上教授了,而教授也不能像1000名小学生那样刷海量的题库。
这样的比喻对CPU和GPU的特点一目了然。
CPU奠定计算基础
英特尔从2011年推出市场的XeonE7处理器平台开始,就引入了3条总线(QPI)架构,奠定了今天多路服务器的基础,目前市售的4路和8路的x86高性能服务器产品都属于此架构框架。这样的架构随着处理器一代代的发展,虽然计算性能一直在增长,但是并没有改变3条QPI的设计架构,直到最新的XeonSP(可扩展至强家族)诞生后,QPI(Quick Path Interconnect快速通道互联)变成了UPI(Ultra Path Interconnect,超级通道互连),但是3条总线的设计依然如故。
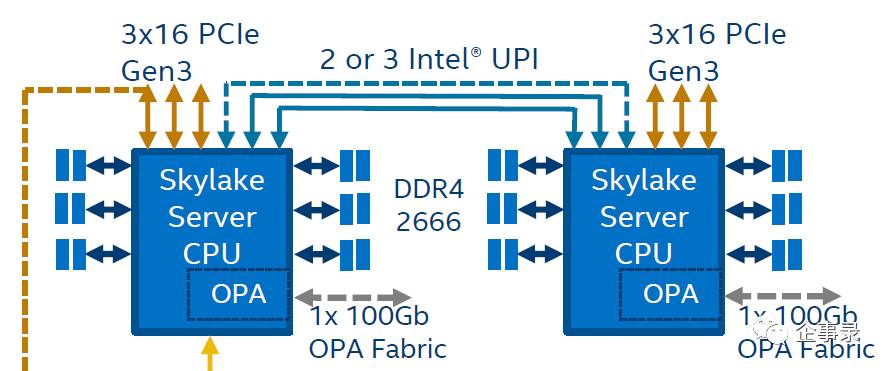
上图是Skylake处理器的典型架构。旗舰型号Xeon 8180 28核56线程,主频2.5GHz,TDP 205W
新一代的Xeon SP的4路和8路服务器脱胎于同一套架构。铂金版的Xeon SP处理器都有3条UPI通道(每条UPI 10.4GT/s,3条总带宽124.8GB/s总带宽),在4路架构上可以实现四颗处理器交叉互联,形成一个高效的MESH架构,在处理器性能和并行能力上达到了一个最优化的选择;
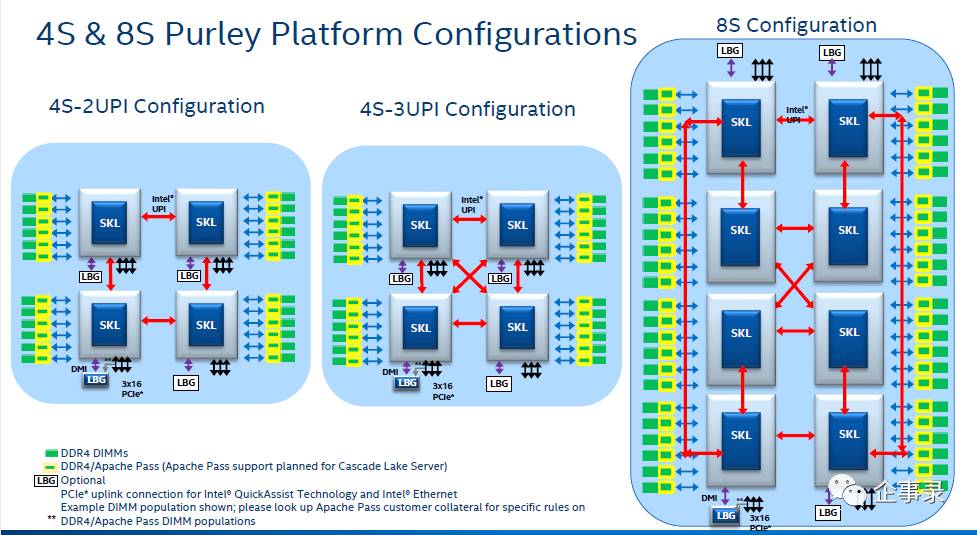
而8路服务器显然不能再用MESH架构了,毕竟一颗处理器上只有3根UPI通道,8颗处理器的优化连接方式如图所示,英特尔将这样的8路架构称为RING,即环形架构,每4颗处理器组成一个环型总线,两组环形总线间使用4条UPI通道交叉互联,这样能在8颗处理器时,提供最优化的交叉互联架构。
目前已经上市的8路Skylake处理器的典型产品是联想 SR950服务器。它同时具有4路MESH架构和8路RING架构两组配置。SR950最神奇的地方是无论4路OR 8路配置,外形都是一样的4U机架式外观,只是计算密度和扩展能力不同,用户可以根据业务类型选择最适合自己的SR950服务器。

注:
UPI带宽是双向的,也就是说10.4GT/s*(8byte/2)=41.6GB/s,那么两条就是83.2GB/s。三条就是124.8GB/s。而且UPI和PCIe不同,具有更低的延时,因此虽然16X的PCIe3.0能有15.8GB/s的带宽,但是延时和转换的效率显然不能与UPI相比。
这么珍贵的UPI总线,英特尔4路以上的服务器上都不够用,自然不会开放给第三方,其他的设备就只能在PCIe总线上想办法了,一颗处理器给你提供48条PCIe 3.0,怎么组合使用就看服务器厂商的设计了。
GPU另辟坦途
早期的GPU就是PCIe接口的显卡。一条16X的PCIe 3.0只有15.8GB/s的带宽,GPU间需要更高带宽来进行互联并行计算,如果只是基于PCIe总线,那么GPU的并行计算的带宽和延时上都会受到限制。
2011年时,nVidia引入了CUDA UVA(Unified Virtual Addressing)技术,允许多个GPU节点之间在一定程度上共享彼此的显存,同时允许GPU直接访问并利用系统内存(
题外话:实际上单节点本地内存不足的现象在大规模并行计算中相当常见,而且已经成了困扰并行化进程的一大瓶颈,亦即“存储墙”
)。
第一代的GPU并行计算是通过PCIe16X总线来实现的。当某个GPU节点在应用中出现本地显存容量不足时,可以通过PCIe总线使用其他GPU的显存。显而易见,GPU单一节点能够获得的有效带宽只能是PCIe 16X的带宽。
翻越存储墙并不是催生NVlink的全部理由,GPU走入高性能、通用计算、AI领域的诱人前景也是NVlink诞生的重要诱因。
NVlink是一个GPU间互联的高速通道,具有20GB/s的单向带宽,40GB/s的双向带宽——
敲黑板,注意了
——第一代NVlink架构的GPU上有4条NVlink总线,每颗GPU可以直接和另外4颗GPU链接,是互联效率较高的CUBEMesh架构。
最新一代GPU V100的NVlink(300GB/s,两倍于上一代)总线达到了6条,无限接近了8块GPU相互直接的状态,从连接跳数来看,与4条NVlink的CUBE MESH相似,但是两个交叉互联的4路GPU间的互联带宽增加了一倍,更适合GPU大规模并行计算应用。
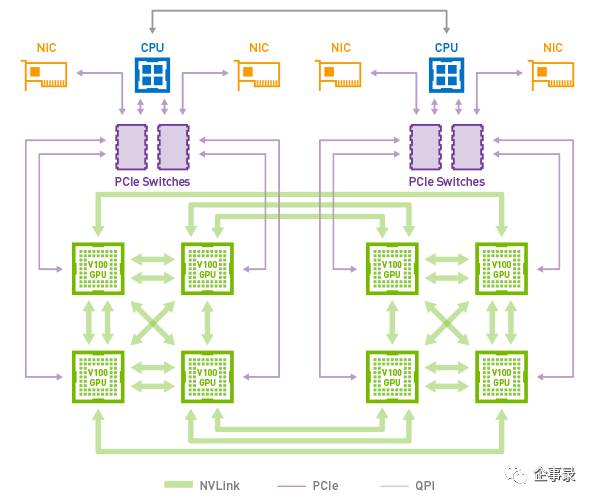

nVidia V100 GPU,NVlink版,640个Tensor内核,5120个CUDA内核,16GB内存,TDP 300W
x86家族的4路8路服务器




