
作者简介:

吕晓旭
去哪儿网 实时数据系统总监
主要负责 Qunar 的数据流基础设施建设和维护工作。曾供职于中国雅虎和淘宝网,主要工作是 Etao 网数据抓取和网页分析工作。
1、前言
去哪儿的在线实时数据平台棱镜(Prism)是一个非常不错的解决问题定位困难的好工具,其过坎式的开发过程,由问题触发新目标改进正是运维开发存在的初心,本文根据全球运维大会嘉宾演讲采编而作。
2、什么是棱镜(Prism)

我们建立棱镜(Prism)的宗旨是以数据可视化为出发点,以降低数据和数据分析软件获取成本为已任,构建实时数据的实时分析平台。其中图中红色标的点为我们的主要目标。
我们来看看棱镜(Prism)提供了哪些服务?首先是实时日志服务—ELK,用于数据的收集分析和图形化显示,提供基础的消息收集整理服务。其次是数据总线(Kafka)用于高吞吐量分布式的发布订阅平台消息用于消息的传递,这个总线不单单只有我们部门自己用,还有其他的相关部门用户使用。
除了刚刚的简单处理之后做一些展现的日志处理系统以外,其实我们还会做更深入的一些平台,如接下来的大数据实时分析系统(Spark Streaming/Storm/Flink)用于智能化分析。然后是数据存储(Elasticsearch as a Service)。
最后是 OLAP/试验平台(Zeppelin+Spark/Flink)用于开发部门的新应用的测试。算法工程师能将算法放在这个集群平台上,再加上 Spark 来测试他们的算法。测试 OK 以后会把结果反馈给做工程的工作人员,最后完成工程项目中需要的生产系统。
2.1 棱镜(Prism)的数据流通
先简单看一下整个 Prism 数据流系统架构。
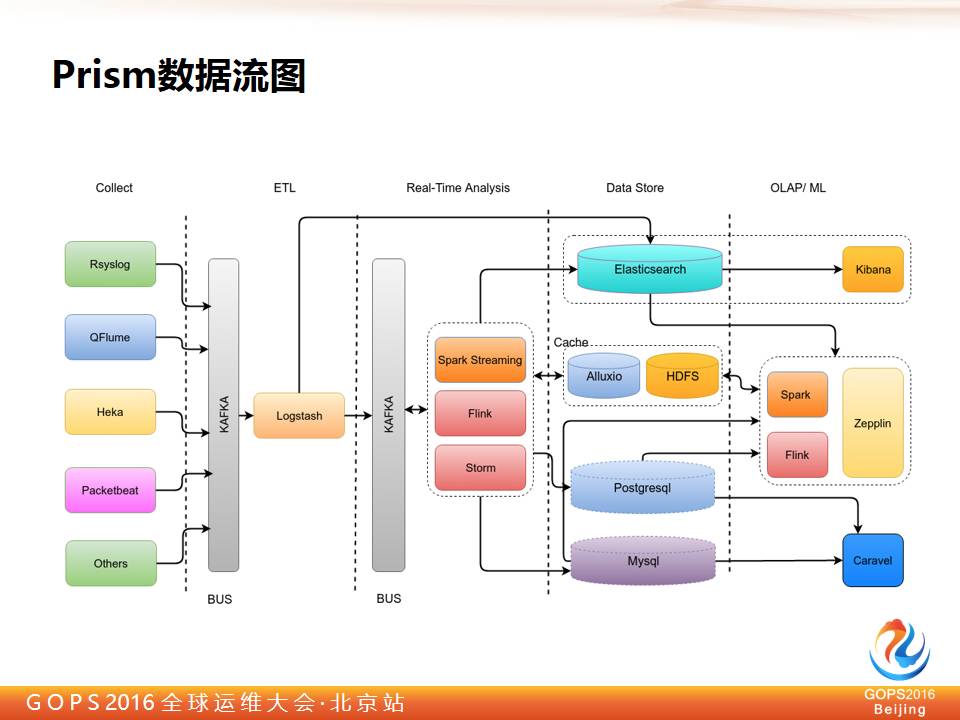
最左边是收集层, Rsyslog 收集系统日志,QFlume 每个实体机和虚拟机都会布置,是我们自己开发的,Heka 之前用于收集 Docker 的日志,Packetbeat 用于抓一些包,Other 就是其他业务线。
所有的数据都会汇总到 Kafka,进入到 ETL 这一层,经过 Logstash 的初步整理和收集后,把结构化数据转化打到 Elasticseach 上做测试。在此之前主要部分是日志,然后输出到 Kibana 上展现给用户,这里一共有两部分,一部分是提供给工程师查问题,另外一部分是提供给产品经理做一些实时业务监控分析。
还有一部分非可见数据,这些数据经过处理以后再打到 Kafka 总线上,后面会有更丰富的工具,或者说处理能力更强的工具在后面进行处理,我们选用的都是比较流行的框架,如 Spark Streaming/Flink/Stom 这样的大数据分析工具。其中有一部分数据还会打到 Elasticseach 上。
其他的数据则写入存储层或者数据库存储这一层。数据经过 Spark、Flink、Zepplin 加载之后,再通过他们各自的数据可视化工具进行历史数据的展现,比如像 Elasticsearch、Zeppelin 等。
整个我们的实时系统拓扑结构就是这样,但是可能最后有一层的工具是没有显示出来,因为这个随时会有变化。
2.2 为了解决我们的疼点,DEVOPS起步了
我们的起步就如这幅图片里一样,产品碰到 BUG 了,我们经常会开讨论会,而每次会议中的场景就像图片中看到的一样。

最开始我们定位 Developer 是问题的瓶颈,我们开始盘查问题并逐一分析问题原因,发现运维上在发布更新的过程中能及时的反馈和发现 BUG,最后大家都希望通过 DevOps 开发新的产品来面对这些问题,剩下一些人只能干看着。
在运维看来,问题原因其实很简单,因为只有 DevOps 知道你的日志怎么查,去哪儿查。其他人没有像 DevOps 这么了解,一般公司都是有 Ops 这个环节的,但是在我们公司没有,在我们公司只有开发,Dev 写的代码,谁开发的谁去运维,谁去改进,谁去改 Bug。
问题定位一直都是我们的疼,我们就带着这样的疼起步了。
2.3 解决问题的良方—ELK
所以为了解决这个问题瓶颈,我们要把数据收集到一起,降低查问题的成本,所以我们引入了 ELK 工具,这个工具应该大家都了解。
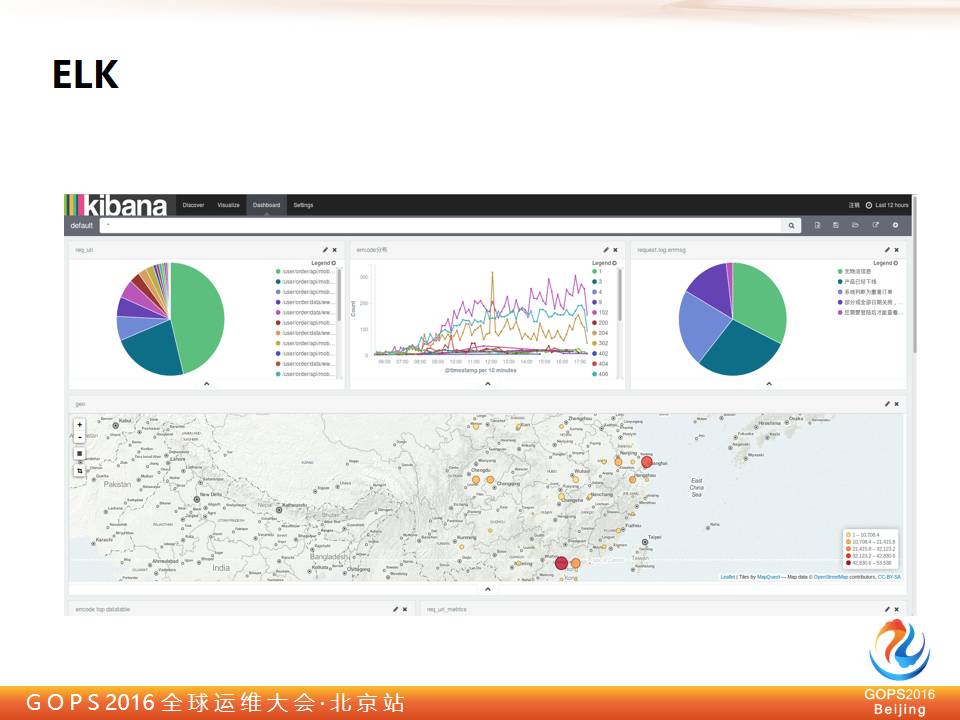
这是 Kibana 数据展示层的界面,大家可以很容易的看到数据的分布。非常简单易操作,而且数据分析挖掘能力非常强,很容易的可以通过条件在整体数据里检索,也很容易就交叉定位出故障的问题点。
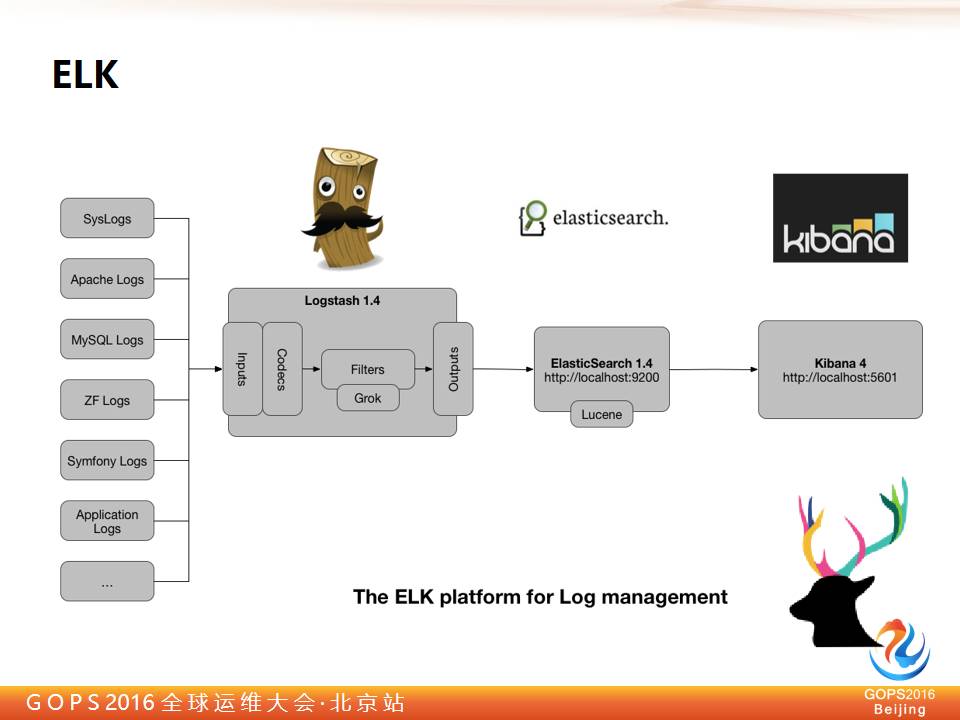
再简单看一下 ELK 是什么,棱镜(Prism)和 ELK 收集层差不多,基础的日志棱镜(Prism)都有,都是 ELK 演进过来的。它中间是个 Logstash 是做 ETL 用的。然后在到 Elasticsearch 做数据检索,最后 Kibana 显示出来,Kibana 在 BI 的能力上还是比较强的。
在做棱镜(Prism)这个系统的时候是从一个项目使用 ELK 开始的,之前我们有一个酒店的项目,它有几百台机器,然后根据城市来做的哈希,每次上线的时候要根据区域或者城市,来一部分一部分的做发布。
每次发布的时间大概要花费六七个小时,经常是从晚上十点开始发,一直发到凌晨四点钟那样的。发布了一个晚上第二天就没法工作了,在搭建了 ELK 之后时间大大的压缩了,起码凌晨一两点钟肯定能回家了。
这是因为分发的速度其实很快,有了 ELK 后,很快就能发现发布的结果是不是有问题,之前发布是要通过一台一台的去扫描日志,但是那个没有统一平台,效率非常低。
我们做完这个系统之后,ELK 系统很受欢迎,这种方式是大家非常接受的,能够极大的提升大家的效率,所以很多人来要求我们给他们做同样的工具,一开始我们部署方式是这样,我们部署方式是申请虚拟机账号,添加账号。
原本每次分发需要六七个小时的更新分发任务,在使用 ELK 之后分发速度节约近一半时间,原本晚上十点开始的更新任务,要更新到凌晨四点,更新的工作人员第二天都没精神工作。现在工作人员最多更新到凌晨一两点就能回家了,一般都能在12点前更新完成回家。
更新的时候,任务下发,速度是很快的,导致慢的原因往往是在更新中卡住了,而我们并不知道问题在哪,哪里未完成。ELK 能帮我们快速的定位问题在哪里,我们可以快速响应处理。这与原先使用工具来扫描校验结果正确性的方式相比,实时性准确性以及全局性都大大提高了,问题定位更加精确。
3、架构演进路上的新大陆
初期的架构成功给我们带来了新的发展,我们引入了新的需求,如繁琐的部署和实时业务调整,在新的需求下现有的构架时效性就显得非常差了,并且无法满足新的需求功能,我们很难应对快速构建业务,快速增减容量等业务目标,怎么办?
后来我们因为一次机缘巧合的机会,在一个会议上听到讲 Docker 的时候,图片中的 LOGO 就是我们发现的新大陆,我们在后期的整体架构中引入了以上的方案。

通过这三个方案的配合,我们解决了新应用的快速增减容量,新工具快速支持,提高硬件资源利用率以及降低数据软件使用成本等问题。
举个例子,在未部署之前我们公司部分业务团队需要做实时计算,一般会走流程申请。实时资源是非常稀缺和固定的,但是需求却是弹性的,我们往往遇到实时资源不足无法分配,或者是资源过多申请需求不足的矛盾性问题。
在棱镜(Prism)项目构建完成之后,就很好的解决了这个问题,因为我们基于 Docker、Marathon、Mesos 完成了底层的虚拟化,把所有的业务机群资源权都收回来了,然后做统一分配,使得原本固定的资源变成了弹性可控的。
新系统上线之后,开发们不用再自己去发布软件了,我们都能替他们处理,我们帮他们启动集群,他们也不用关心运维的事情。
4、更高难度的数据分析
在 ELK 分析系统成功之后,发现有更多的实时数据需求就来了,在建立起虚拟层之后,我们把所有的资源做了统一,建立起了中心式的实时数据资源管理。其他的应用系统也向我们这边靠拢了,比如实时推荐,我们将数据分析后直接就推送到了前端。还有多数据源实时 JOIN 等新需求。
我们最先是引入的 Spark scheduler,我们把它跑到 Mesos 上,使用的是一个开源版的叫做 Spark on Mesos,这个软件是 Mesos 一个公司开发的,在应用了这个软件之后,我们发现它的集群工作方式是粗力度的,在这种工作方式下只能跑一个节点。
剧透:
之后我们改了一些东西,改成了集群版,后来还被 Spark 官方接受了。
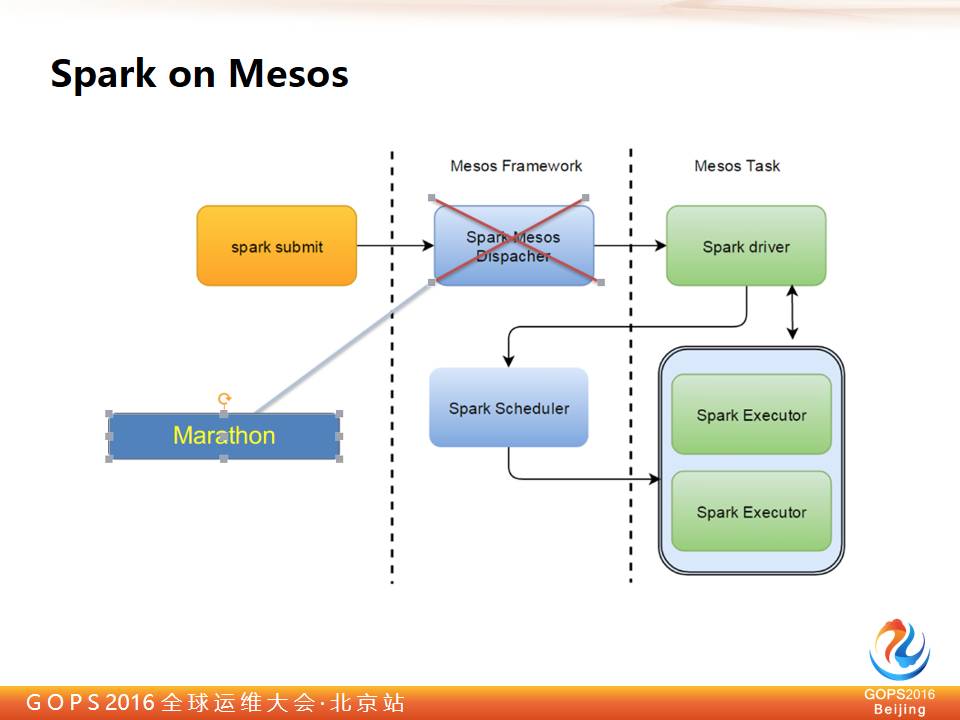
那我们是怎么做的呢?一般在集群外有一个 Framework,然后起一个 Spark drive,它再找 Mesos 申请,再去发真正的 Spark executor。
一台是这样的工作虽然可以做,但是也有缺陷,因为这个方式用的是 Mesos 自己的。另一台他做得也不够完善,不是工业级产品,它调某些测试时,可以看 spark 集群的一部分是单独启动,另一部分是通过发 Mesos 发到集群。
所以有时候也有让人头晕的地方,后来我们就全部改到了 Marathon 上,我们就把 Drive 做成0,不让它等,或者让它起不来这样的作用,我们直接用 Marathon 启动就可以了。
这样的好处是直接用 Docker 分发就可以了,我们后面还会在做一些改进,因为现在相当于每个任务就是一个集群,而且量不是太大,只要机器部署过一次就不会再去拉镜像了。
其他方式也类似,本身这些软件也都是无状态的,我们看到这些全是无状态的,带状态的全都没有跑到 Mesos 上。
所以实现之后我们做了一个梳理,只有 Marathon 了,虽然也有 spark Mesos,但我们基本上不做接口,只用一个接口发布。
5、总结
我们总结一下我们做的事情,我们做了一个实时系统,这个实时系统能即时的发现故障问题,应用工具集合分析问题,解决问题。
其实换个角度看说我们做了一个平台更加合适一些。因为这已经超过实时系统的外延和内涵了,我们做的最大的贡献就是降低了数据软件部署的门槛,业务人员不需求要再去搞集群部署了,而且我们降低了 Mesos 环境下的部署门槛。
但我们存在的需要改进的问题依然有,比如负载不均衡的问题,数据异常定位速度慢的问题,这些还需要跟多的经验积累来慢慢解决,我们日后会再去丰富,因为这个占我们很大的时间和工作量。
最后我们希望在未来解决我们现在已经存在的问题,接入新软件,还有就是1.0平台之后,GPU 建立起来了,我们神经网络用机器资源越来越多,它们各自为政,我们需要把这些资源管起来。
近日好文:
《DevOps前世今生之DevOps编年史》
《一次 DNS 缓存引发的惨案》
《Hadoop 3中的磁盘管理大招解密》





