
英伟达最新季度财报公布后,不仅AMD沉默英特尔流泪,做过长时间心理建设的分析师也没想到真实情况如此超预期。
更可怕的是,英伟达同比暴涨854%的收入,很大程度上是因为“只能卖这么多”,而不是“卖出去了这么多”。一大堆“初创公司拿H100抵押贷款”的小作文背后,反应的是H100 GPU供应紧张的事实。
如果缺货继续延续到今年年底,英伟达的业绩恐怕会更加震撼。
H100的短缺不禁让人想起几年前,GPU因为加密货币暴涨导致缺货,英伟达被游戏玩家骂得狗血淋头。不过当年的显卡缺货很大程度上是因为不合理的溢价,H100的缺货却是产能实在有限,加价也买不到。
换句话说,英伟达还是赚少了。
在财报发布当天的电话会议上,“产能”理所当然地成为了最高频词汇。对此,英伟达措辞严谨,不该背的锅坚决不背:
“市场份额方面,不是仅靠我们就可以获得的,这需要跨越许多不同的供应商。”
实际上,英伟达所说的“许多不同的供应商”,算来算去也就两家:
SK海力士
和
台积电
。
HBM
:韩国人的游戏
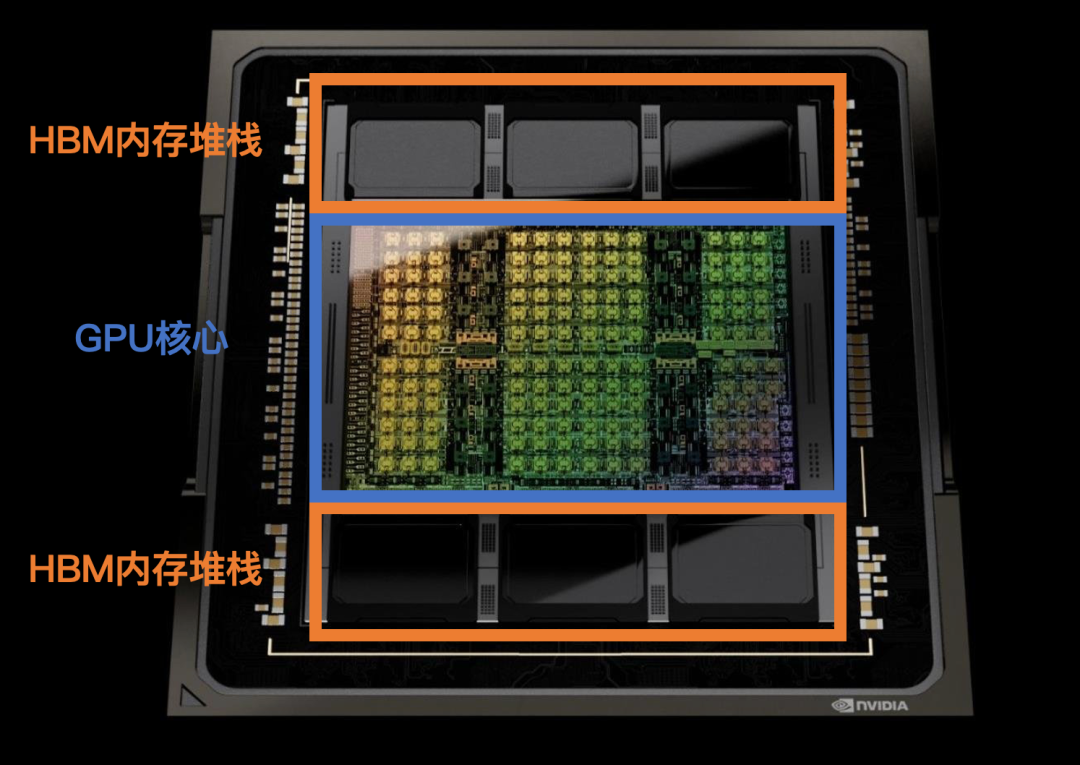
如果只看面积占比,一颗H100芯片,属于英伟达的部分只有50%左右。
在芯片剖面图中,H100裸片占据核心位置,两边各有三个HBM堆栈,加起面积与H100裸片相当。
这六颗平平无奇的
内存芯片
,就是H100供应短缺的罪魁祸首之一。
HBM(High Bandwidth Memory)
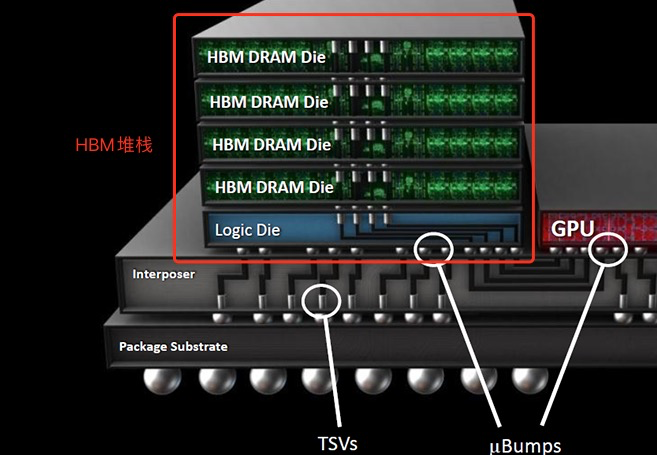
直译过来叫高宽带内存,在GPU中承担一部分存储器之职。
和传统的DDR内存不同,HBM本质上是将多个DRAM内存在垂直方向堆叠,这样既增加了内存容量,又能很好的控制内存的功耗和芯片面积,减少在封装内部占用的空间。
“堆叠式内存”原本瞄准的是对芯片面积和发热非常敏感的智能手机市场,但问题是,由于生产成本太高,智能手机最终选择了性价比更高的LPDDR路线,导致堆叠式内存空有技术储备,却找不到落地场景。
直到2015年,市场份额节节败退的AMD希望借助4K游戏的普及,抄一波英伟达的后路。
在当年发布的AMD Fiji系列GPU中,AMD采用了与SK海力士联合研发的堆叠式内存,并将其命名为HBM(High Bandwidth Memory)。
AMD的设想是,4K游戏需要更大的数据吞吐效率,HBM内存高带宽的优势就能体现出来。
当时AMD的Radeon R9 Fury X显卡,也的确在纸面性能上压了英伟达Kepler架构新品一头。
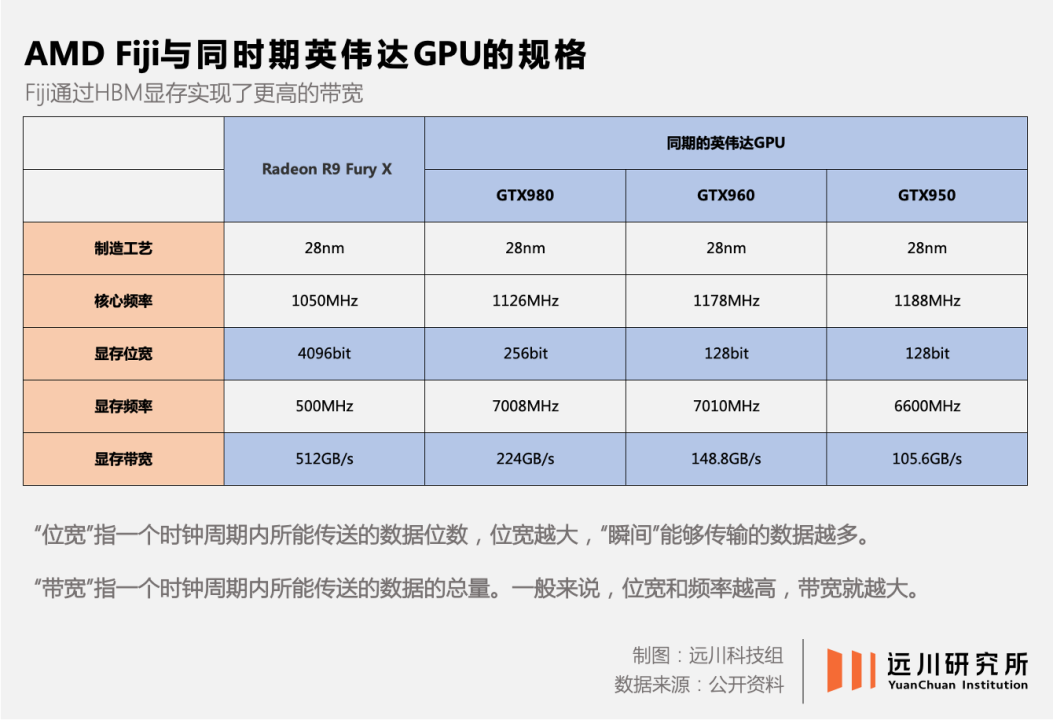
但问题是,HBM带来的带宽提升,显然难以抵消其本身的高成本,因此也未得到普及。
直到2016年,AlphaGo横扫冠军棋手李世石,深度学习横空出世,让HBM内存一下有了用武之地。
深度学习的核心在于通过海量数据训练模型,确定函数中的参数,在决策中带入实际数据得到最终的解。
理论上来说,数据量越大得到的函数参数越可靠,这就让AI训练对数据吞吐量及数据传输的延迟性有了一种近乎病态的追求,而这恰恰是HBM内存解决的问题。
2017年,AlphaGo再战柯洁,芯片换成了Google自家研发的TPU。在芯片设计上,从第二代开始的每一代TPU,都采用了HBM的设计。英伟达针对数据中心和深度学习的新款GPU Tesla P100,搭载了第二代HBM内存(HBM2)。
随着高性能计算市场的GPU芯片几乎都配备了HBM内存,存储巨头们围绕HBM的竞争也迅速展开。
目前,全球能够量产HBM的仅有存储器三大巨头:
SK海力士、三星电子、美光。
SK海力士是HBM发明者之一,是目前唯一量产HBM3E(第三代HBM)的厂商;三星电子以HBM2(第二代HBM)入局,是英伟达首款采用HBM的GPU的供应商;美光最落后,2018年才从HMC转向HBM路线,2020年年中才开始量产HBM2。
其中
,
SK海力士独占HBM 50%市场份额,而其独家供应给英伟达的HBM3E,更是牢牢卡住了H100的出货量:
H100 PCIe和SXM版本均用了5个HBM堆栈,H100S SXM版本可达到6个,英伟达力推的H100 NVL版本更是达到了12个。按照研究机构的拆解,单颗16GB的HBM堆栈,成本就高达240美元。那么H100 NVL单单内存芯片的成本,就将近3000美元。
成本还是小问题,考虑到与H100直接竞争的谷歌TPU v5和AMD MI300即将量产,后两者同样将采用HBM3E,陈能更加捉襟见肘。
面对激增的需求,据说SK海力士已定下产能翻番的小目标,着手扩建产线,三星和美光也对HBM3E摩拳擦掌,但在半导体产业,扩建产线从来不是一蹴而就的。
按照9-12个月的周期乐观预计,HBM3E产能至少也得到明年第二季度才能得到补充。
另外,就算解决了
HBM
的产能,H100能供应多少,还得看台积电的脸色。
CoWoS:台积电的宝刀
分析师Robert Castellano不久前做了一个测算,H100采用了台积电4N工艺(5nm)生产,一片4N工艺的12寸晶圆价格为13400美元,理论上可以切割86颗H100芯片。
如果不考虑生产良率,那么每生产一颗H100,台积电就能获得155美元的收入[6]。
但实际上,每颗H100给台积电带来的收入很可能超过1000美元,原因就在于H100采用了台积电的CoWoS封装技术,通过封装带来的收入高达723美元[6]。
每一颗H100从台积电十八厂的N4/N5产线上下来,都会运往同在园区内的台积电先进封测二厂,完成H100制造中最为特别、也至关重要的一步——
CoWoS
。
要理解CoWoS封装的重要性,依然要从H100的芯片设计讲起。
在消费级GPU产品中,内存芯片一般都封装在GPU核心的外围,通过PCB板之间的电路传递信号。
比如下图中同属英伟达出品的RTX4090芯片,GPU核心和GDDR内存都是分开封装再拼到一块PCB板上,彼此独立。

GPU和CPU都遵循着冯·诺依曼架构,其核心在于“存算分离”——即芯片处理数据时,需要从外部的内存中调取数据,计算完成后再传输到内存中,一来一回,都会造成计算的延迟。同时,数据传输的“数量”也会因此受限制。
可以将GPU和内存的关系比作上海的浦东和浦西,两地间的物资(数据)运输需要依赖南浦大桥,南浦大桥的运载量决定了物资运输的效率,这个运载量就是内存带宽,它决定了数据传输的速度,也间接影响着GPU的计算速度。
1980年到2000年,GPU和内存的“速度失配”以每年50%的速率增加。也就是说,就算修了龙耀路隧道和上中路隧道,也无法满足浦东浦西两地物资运输的增长,这就导致高性能计算场景下,带宽成为了越来越明显的瓶颈。





