
作者:伏草惟存
来源:http://www.cnblogs.com/baiboy/p/nltk2.html
1 Python 的几个自然语言处理工具
-
NLTK:NLTK 在用 Python 处理自然语言的工具中处于领先的地位。它提供了 WordNet 这种方便处理词汇资源的借口,还有分类、分词、除茎、标注、语法分析、语义推理等类库。
-
Pattern:Pattern 的自然语言处理工具有词性标注工具(Part-Of-Speech Tagger),N元搜索(n-gram search),情感分析(sentiment analysis),WordNet。支持机器学习的向量空间模型,聚类,向量机。
-
TextBlob:TextBlob 是一个处理文本数据的 Python 库。提供了一些简单的api解决一些自然语言处理的任务,例如词性标注、名词短语抽取、情感分析、分类、翻译等等。
-
Gensim:Gensim 提供了对大型语料库的主题建模、文件索引、相似度检索的功能。它可以处理大于RAM内存的数据。作者说它是“实现无干预从纯文本语义建模的最强大、最高效、最无障碍的软件。
-
PyNLPI:它的全称是:Python自然语言处理库(Python Natural Language Processing Library,音发作: pineapple) 这是一个各种自然语言处理任务的集合,PyNLPI可以用来处理N元搜索,计算频率表和分布,建立语言模型。他还可以处理向优先队列这种更加复杂的数据结构,或者像 Beam 搜索这种更加复杂的算法。
-
spaCy:这是一个商业的开源软件。结合Python和Cython,它的自然语言处理能力达到了工业强度。是速度最快,领域内最先进的自然语言处理工具。
-
Polyglot:Polyglot 支持对海量文本和多语言的处理。它支持对165种语言的分词,对196中语言的辨识,40种语言的专有名词识别,16种语言的词性标注,136种语言的情感分析,137种语言的嵌入,135种语言的形态分析,以及69中语言的翻译。
-
MontyLingua:MontyLingua 是一个自由的、训练有素的、端到端的英文处理工具。输入原始英文文本到 MontyLingua ,就会得到这段文本的语义解释。适合用来进行信息检索和提取,问题处理,回答问题等任务。从英文文本中,它能提取出主动宾元组,形容词、名词和动词短语,人名、地名、事件,日期和时间,等语义信息。
-
BLLIP Parser:BLLIP Parser(也叫做Charniak-Johnson parser)是一个集成了产生成分分析和最大熵排序的统计自然语言工具。包括 命令行
和
python接口
。
-
Quepy:Quepy是一个Python框架,提供将自然语言转换成为数据库查询语言。可以轻松地实现不同类型的自然语言和数据库查询语言的转化。所以,通过Quepy,仅仅修改几行代码,就可以实现你自己的自然语言查询数据库系统。GitHub:https://github.com/machinalis/quepy
-
HanNLP:
HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。不仅仅是分词,而是提供词法分析、句法分析、语义理解等完备的功能。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。文档使用操作说明:
Python调用自然语言处理包HanLP 和 菜鸟如何调用HanNLP
OpenNLP是Apach下的
Java
自然语言处理API,功能齐全。如下
给大家介绍一下使用OpenNLP进行中文语料命名实体识别的过程。
首先是预处理工作,分词去听用词等等的就不啰嗦了,其实将分词的结果中间加上空格隔开就可以了,OpenNLP可以将这样形式的的语料照处理英文的方式处理,有些关于字符处理的注意点在后面会提到。
其次我们要准备各个命名实体类别所对应的词库,词库被存在文本文档中,文档名即是命名实体类别的TypeName,下面两个function分别是载入某类命名实体词库中的词和载入命名实体的类别。
因为OpenNLP要求的训练语料是这样子的:
|
1
|
XXXXXX
????
XXXXXXXXX
????
XXXXXXX
|
被标注的命名实体被放在
范围中,并标出了实体的类别。
接下来是对命名实体识别模型的训练,先上代码:
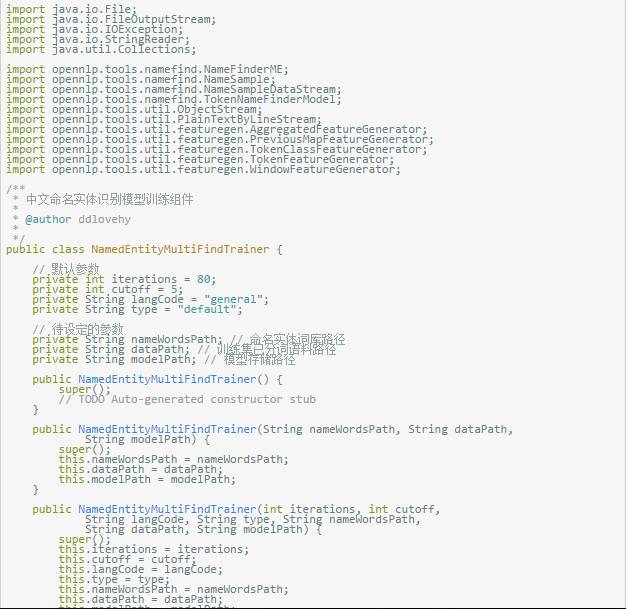

注:
-
参数:iterations是训练算法迭代的次数,太少了起不到训练的效果,太大了会造成过拟合,所以各位可以自己试试效果;
-
cutoff:语言模型扫描窗口的大小,一般设成5就可以了,当然越大效果越好,时间可能会受不了;
-
langCode:语种代码和type实体类别,因为没有专门针对中文的代码,设成“普通”的即可,实体的类别因为我们想训练成能识别多种实体的模型,于是设置为“默认”。
说明:
-
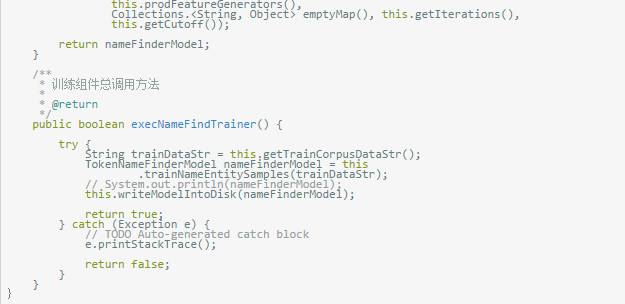
prodFeatureGenerators()方法用于生成个人订制的特征生成器,其意义在于选择什么样的n-gram语义模型,代码当中显示的是选择窗口大小为5,待测命名实体词前后各扫描两个词的范围计算特征(加上自己就是5个),或许有更深更准确的意义,请大家指正;
-
trainNameEntitySamples()方法,训练模型的核心,首先是将如上标注的训练语料字符串传入生成字符流,再通过NameFinderME的train()方法传入上面设定的各个参数,订制特征生成器等等,关于源实体映射对,就按默认传入空Map就好了。
源代码开源在:https://github.com/Ailab403/ailab-mltk4j,test包里面对应有完整的调用demo,以及file文件夹里面的测试语料和已经训练好的模型。

Stanford NLP Group
是斯坦福大学自然语言处理的团队,开发了多个NLP工具。其开发的工具包括以下内容:
简单的示例程序:Stanford POS Tagger
: 采用Java编写的面向英文、中文、法语、阿拉伯语、德语的命名实体识别工具。
最后附上关于中文分词器性能比较的一篇文章:http://www.cnblogs.com/wgp13x/p/3748764.html
1、
分词介绍
斯坦福大学的分词器,该系统需要JDK 1.8+,从上面链接中下载stanford-segmenter-2014-10-26,解压之后,如下图所示
进入data目录,其中有两个gz压缩文件,分别是ctb.gz和pku.gz,其中
CTB:宾州大学的中国树库训练资料 ,
PKU:中国北京大学提供的训练资料。当然了,你也可以自己训练,一个训练的例子可以在这里面看到
http://nlp.stanford.edu/software/trainSegmenter-20080521.tar.gz
斯坦福NER是采用Java实现,可以识别出(PERSON,ORGANIZATION,LOCATION),使用本软件发表的研究成果需引用下述论文:
下载地址在:http://nlp.sta
nford.edu/~manning/papers/gibbscrf3.pdf
在NER页面可以下载到两个压缩文件,分别是stanford-ner-2014-10-26和stanford-ner-2012-11-11-chinese
将两个文件解压可看到
默认NER可以用来处理英文,如果需要处理中文要另外处理。
3、分词和NER使用
在Eclipse中新建一个Java Project,将data目录拷贝到项目根路径下,
再把stanford-ner-2012-11-11-chinese解压的内容全部拷贝到
classifiers文件夹下
,
将stanford-segmenter-3.5.0加入到classpath之中,
将
classifiers
文件夹拷贝到项目根目录,将stanford-ner-3.5.0.jar和stanford-ner.jar加入到classpath中。最后,去
http://nlp.stanford.edu/software/corenlp.shtml下载stanford-corenlp-full-2014-10-31,将解压之后的stanford-corenlp-3.5.0也加入到classpath之中。最后的Eclipse中结构如下:
Chinese NER:这段说明,很清晰,需要将中文分词的结果作为NER的输入,然后才能识别出NER来。
同时便于测试,本Demo使用junit-4.10.jar,下面开始上代码
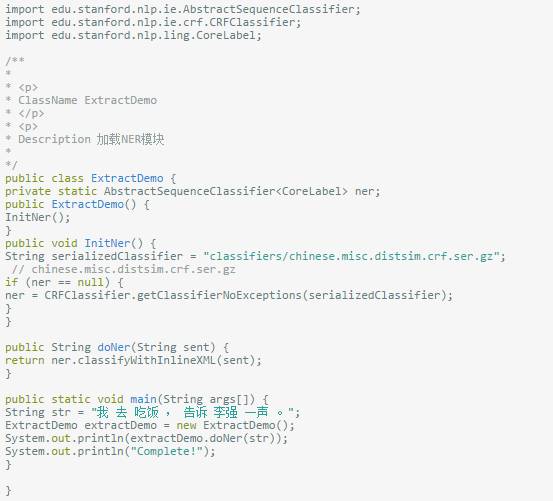
 注意一定是JDK 1.8+的环境,最后输出结果如下:
注意一定是JDK 1.8+的环境,最后输出结果如下:

IK Analyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包。IK支持细粒度和智能分词两种切分模式,支持英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符。可以支持用户自定义的词典,通过配置IKAnalyzer.cfg.xml文件来实现,可以配置自定义的扩展词典和停用词典。词典需要采用UTF-8无BOM格式编码,并且每个词语占一行。配置文件如下所示:
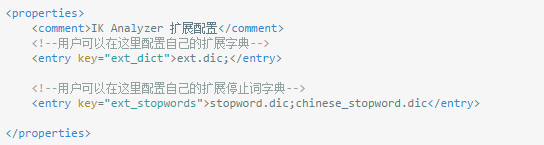
只需要把IKAnalyzer2012_u6.jar部署于项目的lib中,同时将IKAnalyzer.cfg.xml文件以及词典文件置于src中,即可通过API的方式开发调用。IK简单、易于扩展,分词结果较好并且采用Java编写,因为我平时的项目以Java居多,所以是我平时处理分词的首选工具。示例代码:

5 中科院ICTCLAS
ICTCLAS是由中科院计算所历经数年开发的分词工具,采用C++编写。最新版本命名为ICTCLAS2013,又名为NLPIR汉语分词系统。主要功能包括中文分词、词性标注、命名实体识别、用户词典功能,同时支持GBK编码、UTF8编码、BIG5编码,新增微博分词、新词发现与关键词提取。可以可视化界面操作和API方式调用。
6
FudanNLP
FudanNLP主要是为中文自然语言处理而开发的工具包,也包含为实现这些任务的机器学习算法和数据集。FudanNLP及其包含数据集使用LGPL3.0许可证。主要功能包括:
工具采用Java编写,提供了API的访问调用方式。下载安装包后解压后,内容如下图所示:
在使用时将fudannlp.jar以及lib中的jar部署于项目中的lib里面。models文件夹中存放的模型文件,主要用于分词、词性标注和命名实体识别以及分词所需的词典;文件夹example中主要是使用的示例代码,可以帮助快速入门和使用;java-docs是API帮助文档;src中存放着源码;PDF文档中有着比较详细的介绍和自然语言处理基础知识的讲解。初始运行程序时初始化时间有点长,并且加载模型时占用内存较大。在进行语法分析时感觉分析的结果不是很准确。






