主要观点总结
本文主要介绍了作者在KITTI数据集上基于PyTorch实现PointPillars模型进行3D物体检测的学习心得。文章涵盖了数据准备、网络结构、预测与可视化、评估等方面的内容。
关键观点总结
关键观点1: 数据集介绍
文章介绍了KITTI数据集的信息,包括数据集下载、ground truth label信息、坐标系的变换以及数据增强等。
关键观点2: 网络结构与训练
文章阐述了网络结构中的GT值生成、损失函数和训练过程,包括优化器和学习率的调整等。
关键观点3: 预测和可视化
文章描述了基于Head的预测值和anchors进行单帧预测和可视化的过程,包括如何得到候选框以及使用Open3d实现Lidar和Image里的3d bboxes的可视化。
关键观点4: 模型评估
文章介绍了模型评估的指标和方法,包括AP的计算以及不同难度级别的bbox的评估。
关键观点5: 总结
文章对点云检测任务进行了总结,并指出相比于其他任务的不同之处和复杂性。
正文
来源丨https://zhuanlan.zhihu.com/p/521277176

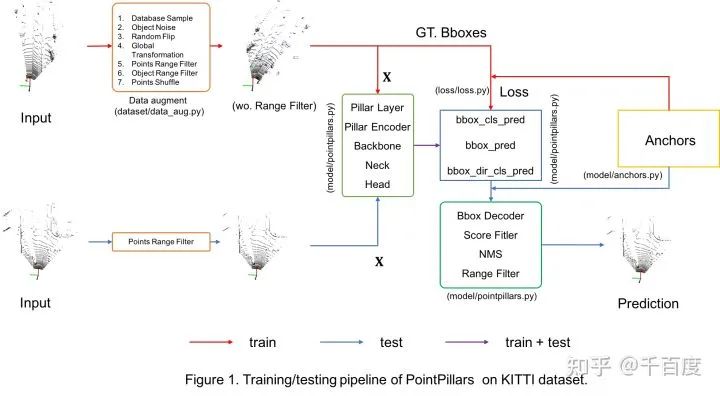
基于Lidar的object检测模型包括Point-based [PointRCNN(CVPR19), IA-SSD(CVPR22)等], Voxel-based [PointPillars(CVPR19), CenterPoint(CVPR21)等],Point-Voxel-based [PV-RCNN(CVPR20), HVPR(CVPR21)等]和Multi-view-based[PIXOR(CVPR18)等]等。本博客主要记录,作为菜鸟的我,在KITTI数据集上(3类)基于PyTorch实现PointPillars的一些学习心得, 训练和测试的pipeline如Figure 1所示。这里按照深度学习算法的流程进行展开: 数据 + 网络结构 + 预测/可视化 + 评估,和实现的代码结构是一一对应的,完整代码已更新于github:https://github.com/zhulf0804/PointPillars
[说明 - 代码的实现是通过阅读mmdet3dv0.18.1源码, 加上自己的理解完成的。因为不会写cuda, 所以cuda代码和少量代码是从mmdet3dv0.18.1复制过来的。]
一、KITTI 3D检测数据集
1.1 数据集信息:
·
KITTI数据集论文: Are we ready for autonomous driving? the kitti vision benchmark suite [CVPR 2012] 和 Vision meets robotics: The kitti dataset [IJRR 2013]
·
KITTI数据集下载(下载前需要登录): point cloud(velodyne, 29GB), images(image_2, 12 GB), calibration files(calib, 16 MB)和labels(label_2, 5 MB)。数据velodyne, calib 和 label_2的读取详见
utils/io.py
。
1.2 ground truth label信息 [
file
]
对每一帧点云数据, label是 n个15维的向量, 组成了8个维度的信息。
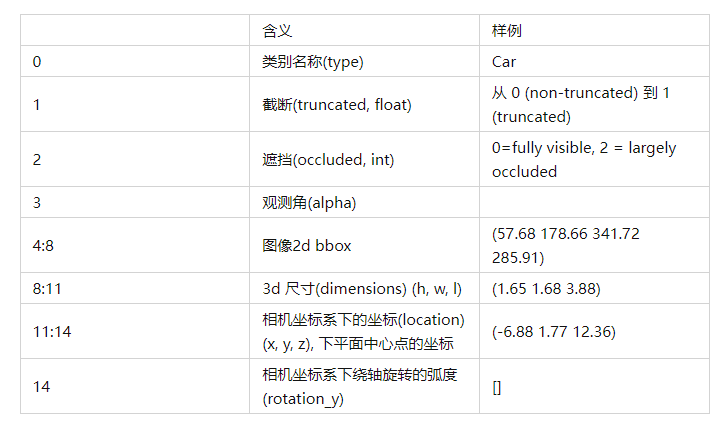
1)训练时主要用到的是类别信息(type) 和3d bbox 信息 (location, dimension, rotation_y).
2)观测角(alpha)和旋转角(rotation_y)的区别和联系可以参考博客blog.csdn.net/qq_161375。
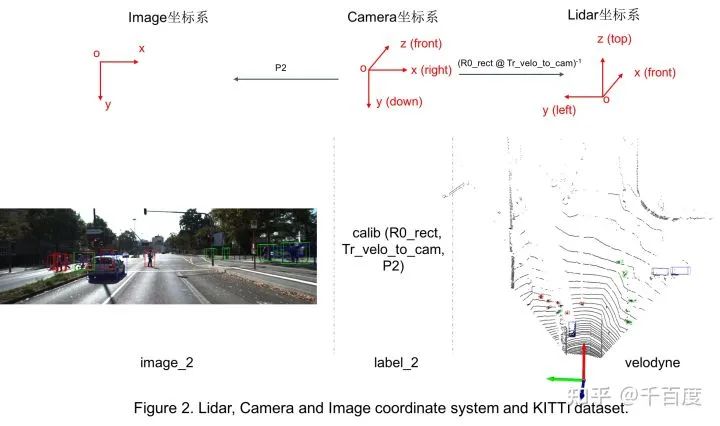
1.3 坐标系的变换
因为gt label中提供的bbox信息是Camera坐标系的,因此在训练时需要使用外参等将其转换到Lidar坐标系; 有时想要把3d bbox映射到图像中的2d bbox方便可视化,此时需要内参。具体转换关系如Figure 2。坐标系转换的代码见
utils/process.py
。
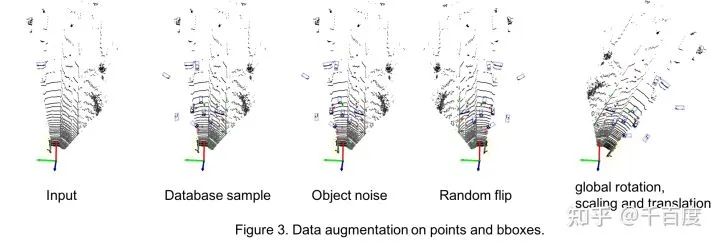
1.4 数据增强
数据增强应该是Lidar检测中很重要的一环。发现其与2D检测中的增强差别较大,比如3D中会做database sampling(我理解的是把gt bbox进行cut-paste), 会做碰撞检测等。在本库中主要使用了采用了5种数据增强, 相关代码在
dataset/data_aug.py
。
-
-
从Car, Pedestrian, Cyclist的database数据集中随机采集一定数量的bbox及inside points, 使每类bboxes的数量分别达到15, 10, 10.
-
将这些采样的bboxes进行碰撞检测, 通过碰撞检测的bboxes和对应labels加到gt_bboxes_3d, gt_labels
-
把位于这些采样bboxes内点删除掉, 替换成bboxes内部的点.
-
-
以某个bbox为例, 随机产生num_try个平移向量t和旋转角度r, 旋转角度可以转成旋转矩阵(mat).
-
对bbox进行旋转和平移, 找到num_try中第一个通过碰撞测试的平移向量t和旋转角度r(mat).
-
-
-
-
-
对points进行shuffle: 打乱点云数据中points的顺序。
Figure3是对上述前4种数据增强的可视化结果。
二、网络结构与训练


2.2 GT值生成
Head的3个分支基于anchor分别预测了类别, bbox框(相对于anchor的偏移量和尺寸比)和旋转角度的类别, 那么在训练时, 如何得到每一个anchor对应的GT值呢 ? 相关代码见
model/anchors.py


2.3 损失函数和训练
现在知道了类别分类head, bbox回归head和朝向分类head的预测值和GT值, 接下来介绍损失函数。相关代码见
loss/loss.py
。

总loss = 1.0*类别分类loss + 2.0*回归loss + 2.0*朝向分类loss。
模型训练: 优化器
torch.optim.AdamW()
, 学习率的调整
torch.optim.lr_scheduler.OneCycleLR()
; 模型共训练160epoches。
三、单帧预测和可视化
基于Head的预测值和anchors, 如何得到最后的候选框呢 ? 相关代码见
model/pointpillars.py
。一般经过以下几个步骤:
基于预测的类别分数的scores, 选出nms_pre (100) 个anchors
: 每一个anchor具有3个scores, 分别对应属于每一类的概率, 这里选择这3个scores中最大值作为该anchor的score; 根据每个anchor的score降序排序, 选择anchors。

-
过滤掉类别score 小于 score_thr (0.1) 的bboxes
-
基于nms_thr (0.01), nms过滤掉重叠框:

另外, 基于Open3d实现了在Lidar和Image里3d bboxes的可视化, 相关代码见
test.py
和
utils/vis_o3d.py
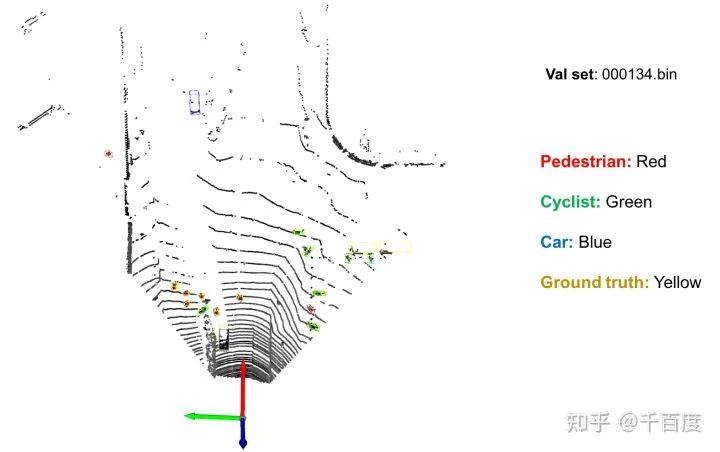
。下图是对验证集中
id=000134
的数据进行可视化的结果。

四、模型评估
评估指标同2D检测类似, 也是采用AP, 即Precison-Recall曲线下的面积。不同的是, 在3D中可以计算3D bbox, BEV bbox 和 (2D bbox, AOS)的AP。
先说明一下AOS指标和Difficulty的定义。










