京东物流极速的购物体验背后隐藏着怎样的秘诀?仓储和配送时效是其中最为关键的一环。京东物流超强仓配体系,特别是在电商行业中独有的仓储系统,在其中起到了决定性的作用。
当前京东的库房已经遍布全国,京东仓储管理系统(简称WMS系统)是最核心的生产系统,涵盖了从入库,复核,打包,出库、库存和报表等等环节。
而作为系统最后端的数据库,不仅仅承担着存储数据的任务,还是系统可用性的最后一道防线,如何保证仓储系统数据库的高性能和高可用,直接决定了库房生产是否能顺畅进行。
在本篇我们将会详细介绍京东物流仓储系统的数据库架构,以及如何通过运维自动化平台、性能优化、故障自愈和数据结转等步骤进行数据库运维架构的演进。
仓储系统的数据库架构,主要分为两种模式,一种是本地模式,一种是集中模式:
1.1 本地模式
本地模式是指当前WMS系统的应用和数据库服务器都部署在本地库房,目的是减少网络延迟,提高作业效率。缺点是机房的电力和网络环境略差,运维难度较高。部署架构图如下:

1.2 集中模式
集中模式是指在IDC机房部署一套WMS系统,多个区域的园区或库房都通过网络专线访问,优点是减少资源部署,架构更为合理,便于运维管理,缺点是部分区域网络延迟较高,一旦IDC发生故障影响范围较广。部署架构图如下:
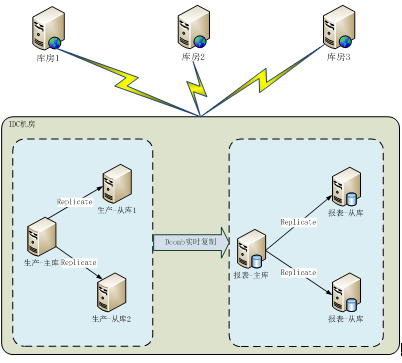
以上是京东仓储系统数据库的两种主要部署模式,目前主要是园区部署模式,也就是一个或多个库房园区共用一个集群(属于本地模式的一种)。
但是随着业务规模的增长,全国各地库房建设日益增多,数据量也与日倍增,而对系统的高性能和高可用的要求却越来越高,如何在现有架构模式下,还能保障系统的高效稳定运行,故障及时恢复,都对仓储系统的运维带来极大的挑战。
以下章节就详细阐述一下我们是如何应对这些挑战的。
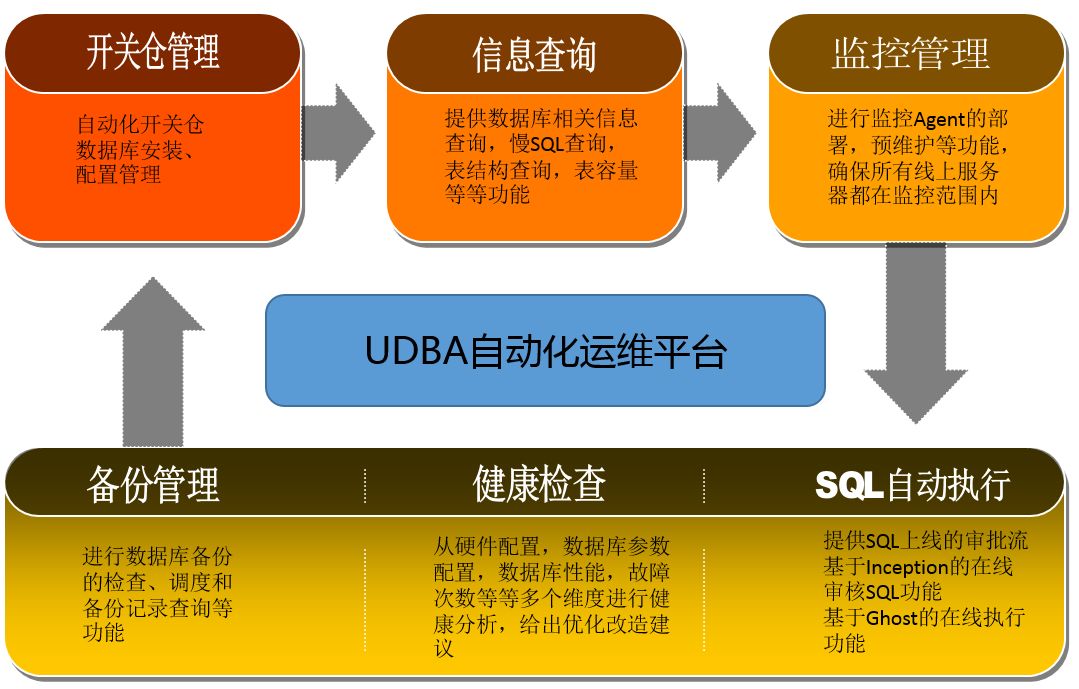
工欲善其事必先利其器,想要做好大规模系统的运维管理,一定需要有自动化的运维平台作为支持,同时也为了提高工作效率,减少和研发的沟通成本,库房运维DBA开发了UDBA数据库自动化运维平台。该平台除了是DBA日常自动化运维的操作平台,还为WMS研发、运营人员提供了日常所需的技术支持和信息查询。
UDBA数据库自动化运维平台的主要功能模块如下所示:
由于仓储业务逻辑复杂,并且系统是从早期的SQLServer迁移到MySQL的,对数据库是强依赖的关系。很多业务场景尤其WMS5的报表业务会涉及很多超大表(单表数据量超过1千万行)的关联,且查询条件根据现场工作人员需求进行组合修改,再加上部分表设计不合理以及查询SQL语法不规范等问题,给数据库优化带来极大挑战。
我们主要通过以下方式来保证数据高性能:
-
实时监控数据库性能,针对突发性数据库出现性能问题及时进行故障排查和故障恢复,保证业务生产正常进行。
-
每天对MySQL慢日志进行分析汇总后邮件抄送给相关研发同事,配合研发同事一起进行数据库优化。
-
周期性对数据库进行巡检,检查数据库运行状态,对压力较大的数据库进行重点分析优化。
-
定期对研发同事尤其新入职同事进行SQL培训,主要针对MySQL语法规范、MySQL表设计、MySQL查询优化等方面,提升研发同事的数据库设计能力和SQL编写能力,在开发过程中提前规避常见的性能问题。
-
将优化过程中遇到的问题归纳分析整理,帮助研发同事认识性能问题后的本质原因,避免重复出现相同故障。
-
积极与研发同事沟通学习,深入了解业务以便更好地从业务角度对数据库进行优化。
在一次服务器巡检中,我们使用SHOW ENGINE INNODB STATUS查看MySQL服务器运行状态时,发现该数据库存在死锁问题,通过多次排查,发现死锁发生频率较高,由于死锁告警信息中的事务信息不全,我们第一时间联系相关业务人员,了解相关业务实现逻辑,该业务通过程序来保证数据唯一性,采用“先尝试更新,后尝试插入”的事务顺序来操作,在详细了解业务逻辑后,通过模拟测试帮助研发同事认识到该死锁的核心原因,并在此基础上提供改进建议,最后将该问题优化方案整理成文档抄送给更多研发同事。
仓储数据库故障自愈系统主要解决两个问题,一个是故障的自动切换,一个是组件的自动恢复。系统功能图如下所示:
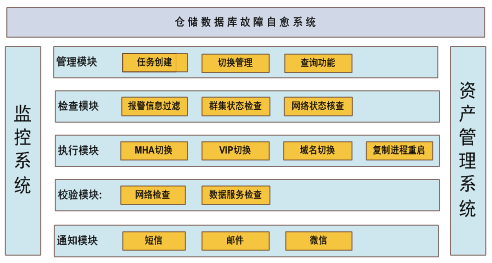
首先硬件作为应用系统的底层基础设施,一旦出现故障将大大降低系统的可用性,仓储业务的数据库集群分散在全国各地几百个库房,数据库服务如何在遇到硬件等异常时快速的故障转移,如何能降低各地网络等外界环境对数据库的性能影响?
其次系统在日常运行中,因为Bug或者其他原因,可能会导致数据库宕机,从库复制进程中断,复制延迟过大等等问题,如何快速解决这些问题,也成为服务质量优良的关键衡量标准。
基于以上这些考虑和实际需求,我们结合基础信息系统,监控系统,以及业界成熟的MHA高可用方案,实现了故障的自动切换,当数据库主库或者从库遇到异常,能够顺利得进行自动切换,保障数据库服务的持续性,当服务器有维护需求时,提供手动切换管理,更方便的进行硬件维护。
同时基于UDBA数据库自动运维平台,对全部MySQL群集复制情况进行自动探测,自动识别高延迟实例,并通过修改innodb_flush_log_at_trx_commit和sync_binlog的刷盘策略参数进行快速恢复,一旦复制正常,参数将自动调整为标准值,同时复制的IO线程或SQL线程异常停止,也可进行自动启动。
上面的处理结果都将以短信、微信和邮件等方式,通知值班同事,处理过程在UDBA自动运维平台上同样可以查询,方便对故障切换的进一步分析和统计。
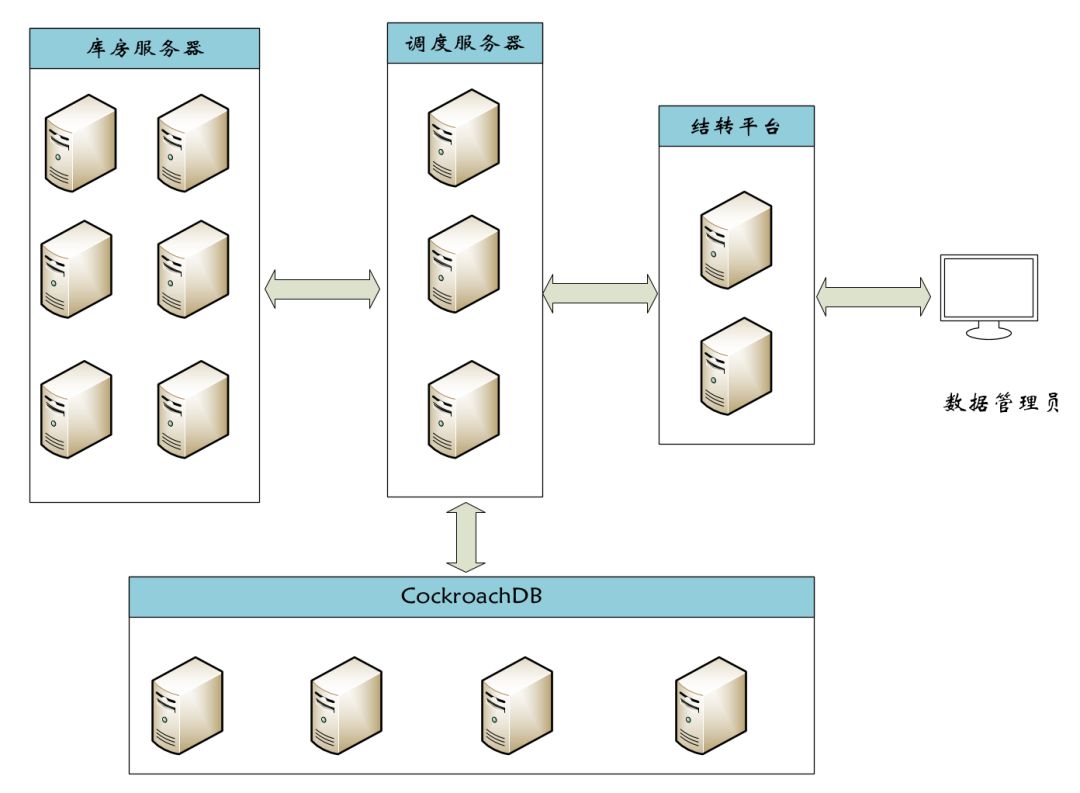
库房数据有时效性强和生命周期短的特点,对于数据量较大且操作频繁的业务表,如果不进行历史数据归档,会存在严重性能问题和磁盘存储瓶颈,因此我们采用生产库保留三月+报表库保留一年的归档策略,对生产库上超过三月”历史数据”进行删除,对报表库上超过一年的“历史数据”结转到IDC机房进行存放。
在未引入自动化结转平台前,需要DBA手动在每套服务器上部署结转程序,当结转条件发生变化时需要通过命令行共计批量更新每套服务器上的配置信息,DBA无法准确掌握每套服务器的结转情况,导致运维难度高且存在较高的误操作风险。
针对库房数据结转的各项痛点,在对结转流程的抽象分析基础上开发了自动化结转平台,其架构为: