人工智能和微服务是当下最火的两个技术趋势,在由七牛云和极客邦联合主办的 QCon2017 北京站“深度学习最新进展与实践”专场中,深知科技 CEO 陈辉老师分享了团队从实践中积累的机器学习微服务化经验,并通过一些具体的案例展示了如何使用微服务搭建机器学习平台,以及微服务在图像识别和文本分析上的具体应用。

陈辉,深知科技 CEO
陈辉,AI 领域创业者。机器学习领域专家,曾任职阿里巴巴和 Google,负责广告精准定向业务和分布式系统开发。热衷开源软件,github 主页 http://github.com/huichen。微服务倡导者。
今天的演讲内容会比较偏实操性。首先会给大家展示一个图像识别的 Demo,并且将代码进行开放;然后会讲一下 Kubernetes 微服务的实践;第三部分就是 Go + Docker 实现部署的 Tensorflow 深度学习模型。
希望大家从这次分享中能够得到:
代码: Go 微服务程序、模型转换脚本、深度学习训练代码
手把手教你在笔记本上跑一个深度学习服务
TensorFlow 深度学习模型微服务化的各种坑大揭秘
1. 图像识别 Demo 演示

图1
解释一下这个 Demo 。大家应该知道这是 Google 的一个项目,简单来说就是提供一张图,用一段非常直白的英文来描述这个图中的内容。在图 1 的四个例子中,左边能识别出来这张图是一个在海滩上的男人在放风筝,右边是一个黑白火车的一个图,火车在铁轨上。
这个模型其实很简单,就是 CNN 的模型,Inception V3 + LSTM + word embedding ,最终的输出是带有概率的一个状况。如图 2 所示。
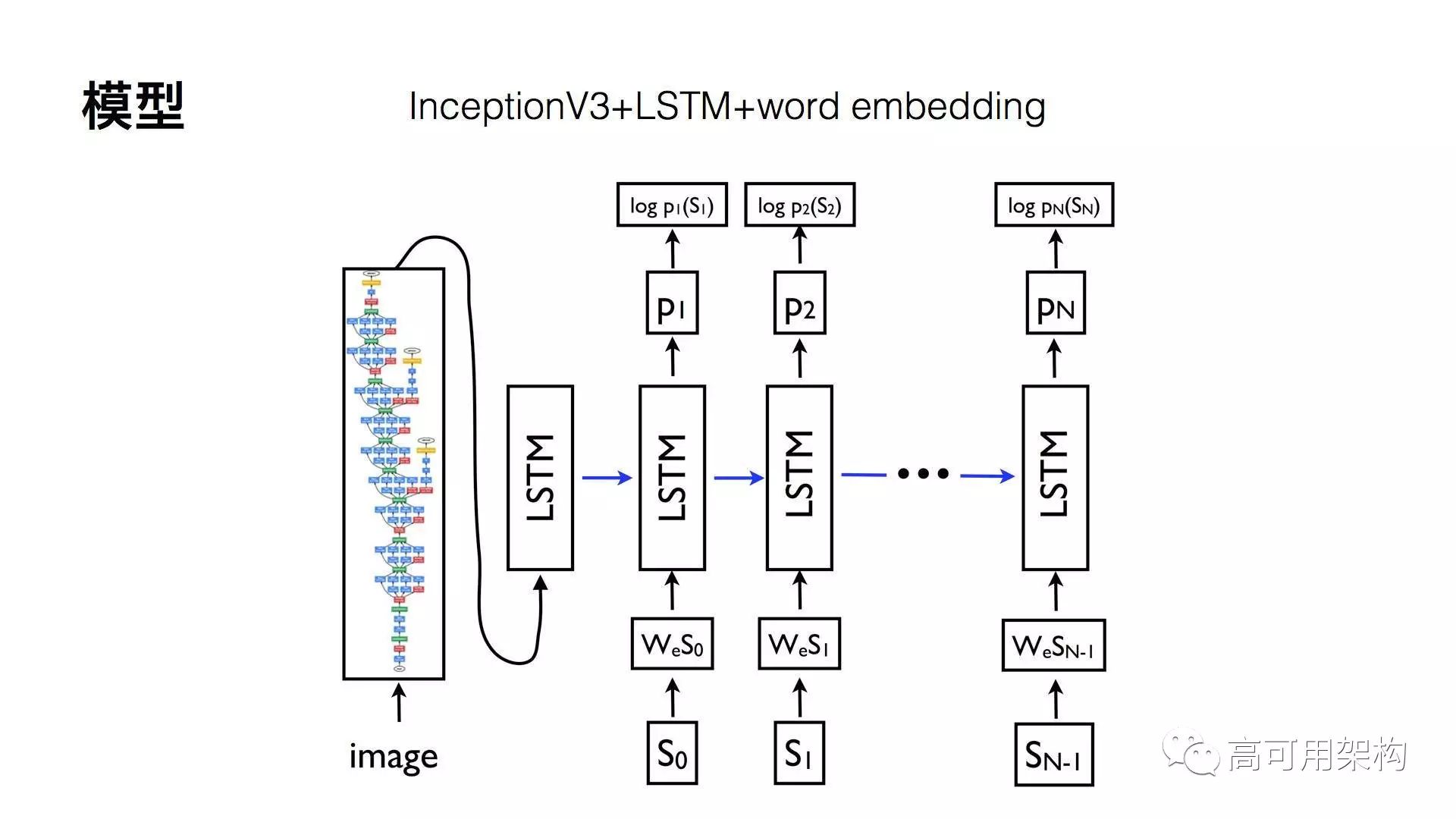
图2
2. 微服务之于深度学习
为什么要有微服务?
如图 3 所示,这张图的意思横轴指的是时间,或者指的是项目的复杂程度,纵轴是这个团队的生产效益,其中有两条线分别是描述了两种不同的开发模式,团队效率和时间复杂度的一个关系,这条蓝色的线是微服务,绿色的线指的是微服务以外单体架构的一个情况。
 图3
图3
最开始当团队比较小,或项目比较简单的时候,微服务的优势没有那么明显。原因在于,最开始的时候为了完成微服务的架构要做很多前期准备工作,要做各种脚本和自动化,所以单体架构其实更能满足比较简单的业务需求。
但是随着复杂度越来越高,单体架构的缺陷会越来越明显。大家如果用过单体架构会知道,当一个团队 70 人同时提交代码的时候,要做很多的测试包括一些集成的工作,才能保证上线的代码没有问题。
微服务部分解决了这个问题,原因在于它能够比较独立的把各个部门封装成不同 API 的服务,各个团队只需要维护自己 API 的内容。

图4
当团队比较大,或者服务很复杂的时候,应该尽可能的将服务拆分。我们团队拆分大概花了三个月的时间,大概拆分了 60 多个微服务,每一个服务是由唯一的一个工程师来负责开发和运维的。
大家可以想到这张图(图 4)一共有多少人,60 多个微服务是多少人做的吗?实际上只有三个工程师。平均每个工程师大概维护 20 到 30 个服务。
我们用的 KOS 整套体系,其中绿色的方块指的是一个部署,蓝色的方块指一个 SVN 的接入点,中间圆的部分用来做异步通讯。
这张图不是手画出来的,是通过脚本自动生成,因为要求所有的代码和配置一定要版本化,所有的调用关系都可以在代码里面反映出来,所以我们用脚本自动的处理所有的配置文件,最终就可以生成这样的一张图。
如果你的团队号称是微服务,但你画不出来这样一张图,说明你的微服务自动化上可能存在一定的问题。
微服务三个特点
对于微服务我总结三个特点:
1)调用关系即架构
怎么去处理这种调用关系,意味着你的架构是什么样子的。在我们的架构里面,图里面一定是单向的,不允许出现循环的依赖的关系。因为如果那样的话,你的项目会出现一个很大的灾难,当其中一个点出了问题之后,你会回馈到达一个节点本身,整个服务就会出现这种情况。
2)工程师独立推动架构演化
因为我们微服务不仅按照项目来切分的,而且是按照人来切分的,所有每一位工程师独立负责不同的微服务,这样意味着所有的架构是由我们的工程师——实际上只有三位工程师——独立推进的。
3)开发即运维
我们没有运维只有开发的同学,但是我们给开发的同学提供了非常好的运维的工具。从代码开始,根据配置文件生成新的版本提交到KPS上去,部署上线之后,我们会有一些监控的脚本去核实这个 API 是不是可用,如果没有问题就可以直接部署上去。
中间也会出现问题,但是对于一个比较小的团队来说,快速出现问题永远比不出现问题要好。
微服务技术选型
团队的技术选型如图 5 所示。

图5
3. 机器学习系统框架演进
深度学习模型的存储量主要在 CPU,非常适合用微服务解决。
如果是用 CPU 来做 Kubernetes 的话,深度学习模型的存储量主要是在 CPU 上,所以使用带有弹性扩容的微服务架构是比较适合的。图 6 所示用的是 Concurrency,平均的的 Time per second 是将近 600 毫秒,基于 Kubernetes 实现了这样一套比较简单的框架。

图6
传统做法、改进做法和最优做法
图 7 所示是传统的做法,需要三个不同的部门,因为这个模型是一个 CNN 模型,而且不是一次得到的结果,要反复做多轮。就是平均来说,一个 VGG 模型在 CNN 上大概需要 40 毫秒左右,所以如果你要去 Serve 一个跟图象相关的模型,在 CPU 上超过 100 毫秒是非常正常的事情。
以上是常见团队的划分。比如需要一些月薪 50K 以上的算法工程师,他们做的事情就是要搜集清理他们的数据,要训练模型,要用 Python。然后牛逼的模型就出现了,交给牛逼的系统工程师。
系统工程师发现这个模型不能直接用,要写一些代码,就是要把脚本粘合在一起,而且有一些逻辑,比如用 Python 来实现 Bm Sersev 需要一秒的时间,才能生成一句话,这个在线上是无法忍受的。同时发现效率也很差,需要做调优,有一些调优可能涉及到模型的东西,所以要反复跟算法工程师沟通,所以用 Java 或者 C++ 把这个东西搞定之后再交给运维工程师。
运维工程师再去运维,运维工程师也很头疼,本身它的资源耗用率很高,怎么能够动态的扩容是很大的挑战。
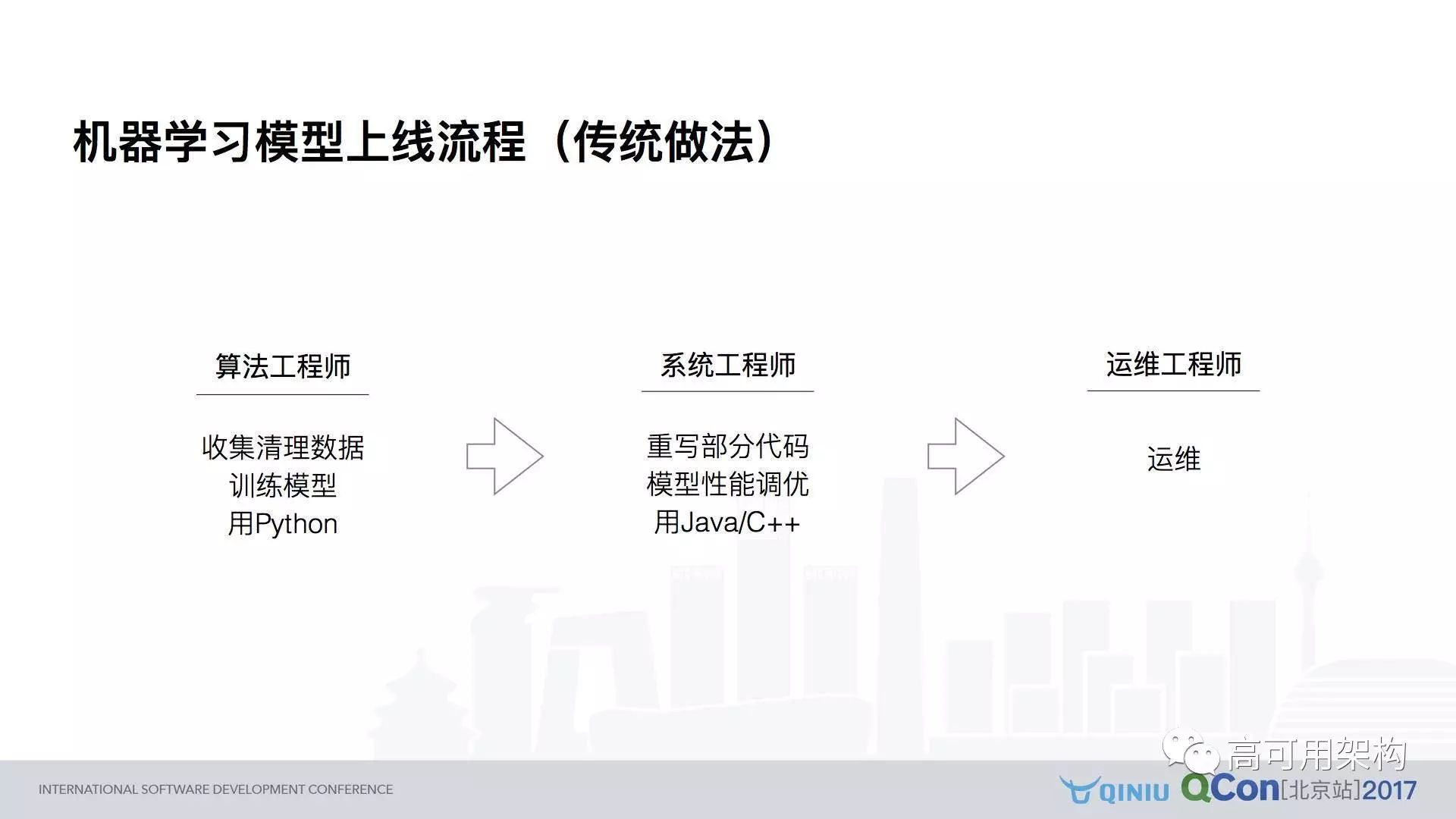
图 7
图 8 是 2.0 做法,大家也可以把 Tensorflow 这个词换成其他的框架。50K 的算法工程师做同样的事情不变,系统工程师如果做的好的话,可以直接部署这个模型,可以自己运维,可以用 Go 或者 C++,但是这里面还是有很多坑,从算法工程师训练出来的模型到系统工程师直接使用的模型之间有很多的问题。

图 8
图 9 则是我们的流程,我们多加了一些钱,花 60K 请能力更强一点的算法工程师,不给他配人,他自己搞定全栈。
算法工程师需要自己清理数据、在 GPU 的环境下训练这个模型,以及用 Go 去载入这个模型部署。需要自己开发及部署,自己运维,而且端到端。
这看起来要求有点高,但是对于创业公司来说很正常,或者对于大公司创业团队是一定要这样做的,这样可以降低内部沟通带来的一些问题,所幸的是我们团队成员都做到了这一点。

图9
4. 从训练模型到模型部署的坑
现在各种各样深度学习的讲座,大家对怎么部署模型基本上都是很简单就概括了,只会说内部有一个很牛逼的平台,但是在实际做的时候,就会发现从 Python 训练出来的模型到最终部署的 C++ 或者 Go 的代码中间,要有很多工作要做。那些工作其实是非常讨厌的。
问题描述:训练模型无法直接使用,inference 要有单独模型
解决方案:Inference 模型提取
1)尽可能将数据预处理逻辑用 Tensorflow 原生的 operation 来实现,简化外部代码逻辑;
2)需要单独写一段 inference 代码,载入 training 模型,去除 training 中特有的逻辑(比如 batch ),然后将 inference 模型写入到新的 checkpoint 中。
代码见:https://github.com/huichen/im2txt
问题描述:模型之外有其他计算代码(如 beam search),Python 实现效率很差。
解决方案:
Python 其实并不适合写 inference 服务,虽然算法工程师倾向于这样做。这里推荐用 Incepticon V3 + LSTM + beam search,用 Go 实现了模型整合。最开始 Go 语言实现了500毫秒左右,中间做了一些很好的工具,一步一步降低到了 350 毫秒。
代码见:https://github.com/huichen/gotalk
问题描述:模型最好静态化为常量参数,而且要转化成为单一模型文件,方便加载。
解决方案:
这里能提供一个工具,将解决方案一生成的 interence checkpoint model 静态转化为一个单一模型文件,方便加载。简单来说,就是导入一个在训练阶段得到的一个模型,然后对这个模型做一些操作,把其中的一些参数转为常量,最终写入到指定的一个文件里面去。这个好处就是用过 Tensorflow 的同学都知道它里面有很多的图片的,包括图的定义,包括原参数的定义等等。这个工具可以载入文件夹,最终生成的是单一的文件,在文件夹里面只需要调入这个单一文件就可以了。
代码见:https://github.com/huichen/freeze_tf_model
问题描述:如何将 Tensorflow 的运行环境无痛地打包到容器里?
解决方案:
首先需要编译 libtensorflow.so 动态链接库:
bazel build -c opt --copt=-march=native//tensorflow:libtensorflow.so
这里面有一个小坑,就是不要用 1.0 的版本,因为 1.0 的版本很奇怪的,他不支持超过 32M 的模型载入,如果模型超过 32M 的话,它限定死了,这个文件不能超过 32M,所以用 git HEAD 版本是可以的;
然后直接用 ADD 命令将 libtensorflow.so 复制到容器的 /user/lib 下即可。
这里已经打了一份 Docker 镜像,如果大家服务器上已经装了 Docker,只要一行命令就可以启动这样一个服务:
docker run -d -p 8080:80 unmerged/gotalk
具体见:https://hub.docker.com/r/unmerged/gotalk/
现场提问集锦
Q1:你们有 60 个微服务,是不是每一个微服务都是独立部署的?每个微服务规模代码大概有多少?
陈辉:一个微服务基本上是一个基本模块,比如说 VE、ID 的服务,或者一种类型 API 的巨头,比如说在交易模块里面可能有交易模块,搜索模块等等,所有这些拆分成小服务;规模如果你指的是代码量,语言大概是一两千行代码。
Q2:部署的时候,像这种微服务,你们觉得会不会太细了?
陈辉:本质上来讲,一个模块是由一个工程师开发的,所以它独立去开发,我觉得问题应该不大。
Q3:服务机的调用有多少?
陈辉:有一些模块,比如说唯一 ID 服务,你可以看一下刚才那个图,比如说最右边这个负责人,他可能有 20 多个服务会调用它,但是有一些服务依赖关系比较少,根据你服务的情况不一样。所以对于一些 KPI 比较高的服务,可以增大它的部署 Docker 的数目。
Q4:刚才提到了有一套基本的环境,就是整套微服务代码存储的一些服务,我想问一下工程师是作为一个产品,这种服务化的产品还是其他的一些产品?
陈辉:我们是面向企业服务的,所以有一些平台性的东西,我们会部署在自己这边,有一些需要跟客户定制的话,我们会部署在客户那边,我刚才开放那个是我手工挑选出来的三个项目发给大家,开源是不需要购买的,但是闭源是需要交月费的。
Q5:比如说企业有一些服务是比较大的,你们怎么来做?
陈辉:微服务并不是说我们给企业做的方案,而是我们内部的一些平台性的产品,企业方面,不一定所有企业都有 Kubernetes ,它相对来说比较简单,它的模块是内部的,所以这个只是局限在我们内部,因为这个需要一整套的服务。
活动预告:
七牛架构师实践日-新时代下的高效运维之道将于 5 月13日在北京举行,届时七牛云高级运维总监高磊、OneAPM 研发总监高海强、唱吧高级运维总监李玉峰、中国站长第一人高春辉将就运维主题带来精彩分享,感兴趣的小伙伴可点击底部“阅读原文”报名哟~
推荐阅读
本文作者陈辉,转载请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号










