Facebook又爆出了大新闻:他们基于卷积神经网络(CNN)开发出的语言翻译模型比现有基于循环神经网络(RNN)的方法快出9倍!而且能以更接近人类的方式进行精准翻译。
人工智能技术在近年来的飞速发展无疑为人们展现了一幅前所未有的未来图景,人们在欢呼雀跃的同时,也开始担心被科技加持的主流文化会逐渐拉大与其他人类文化的差距。“科技霸权”不单存在于经济领域,也在逐渐向诸如语言、艺术创作等人文领域渗透。而一旦脱离主流技术发展体系,这些小众人类文化所面临的结局很可能是逐渐消亡。
以 AI 为代表的新兴技术会将重建人类文明的“巴别塔”,还是加速其崩塌?

图丨《圣经》中的巴别塔
人类目前使用大约6900种不同的语言。但使用汉语、英语、北印度语、西班牙语和俄语这5种语言的人占了全球人口的一半以上。事实上,95%的人只使用100多种语言进行交流。
另外一个不为人知的事实是,根据语言学家估计,世界上约有三分之一的语言仅由不到1000人使用,而且在未来一个世纪这些语言面临失传的危险。这些小众语言所体现的独特的文化遗产,像传统故事、短语、笑话、传统草药,甚至独特的情感也会随着语言的失传而消失。
 图丨世界语言树
图丨世界语言树
在这个处处连接的互联网世界里,人与人之间的沟通和交流变得无比的方便快捷。但现在的问题是,语言的差异仍然像是一道深不可测的鸿沟摆在拥有不同文化背景的人们面前。
作为全球最大的社交巨头,Facebook自诞生起就在血脉深处蕴藏着开放和连接的基因,他们的使命就是打破藩篱、重构起互通互联的“巴别塔”,使每个人都可以以最准确、最快速的方式接触到全球范围内的信息。

而要实现这一目标,第一步就是解决不同语言之间的转换问题。人工翻译已经远远不可能满足当今世界所产生的海量信息流,那么,是否能有一种快速而准确的技术决绝方案,能替代人类去完成不同语言间的转换?
就在今天,Facebook人工智能研究中心(FAIR)发布了使用全新的卷积神经网络(CNN)进行语言翻译的研究结果。据悉,这种新方法能够以现有的循环神经网络系统9倍的速度进行翻译,而且翻译的准确性还会得到大幅的提高。
卷积神经网络(CNN)最早是由深度学习领域的权威人物Yann LeCun在几十年前所发明的,在以图像处理为代表的的机器学习应用中表现的非常成功。但在语言翻译方面,由于对准确性的追求,往往会将循环神经网络(RNN)作为首选的技术。
 图丨Facebook人工智能研究院院长、纽约大学终身教授Yann LeCun
图丨Facebook人工智能研究院院长、纽约大学终身教授Yann LeCun
但尽管如此,RNN在设计上所固有的局限性还是制约了它在语言翻译和文本处理上的进一步应用。
举例来讲,计算机在进行文本翻译的时候,通常是根据一种语言的句子来判断在另一种语言里同义单词的排列顺序。但循环神经网络只能以从左到右(或从右到左)的顺序逐字进行翻译,这就和深度学习中多GPU并行的计算模式十分不契合,必须要等到上一个词翻译完之后,下一个词才可以继续,实际上也就相当于造成了神经网络计算能力的浪费。
与之对比,CNN就表现出很大的优势,它可以充分利用多GPU并行计算的能力,同时处理多个语言片段,显然效率会得到大大提升。除此以外,CNN的另一个优势就是其所具备的信息分层处理能力,这对于海量信息中的复杂关系归纳汇总十分有利。
 图丨CNN与RNN区别简明图示
图丨CNN与RNN区别简明图示
在以往的研究中,CNN在翻译上的应用并没有引起Facebook的重视。不过,FAIR团队意识到了这一技术的潜力,他们通过搭建翻译模型验证了CNN极佳的翻译表现,如果在未来这一能力可以得到释放的话,那么精准、高效翻译全球6900余种语言将不再是梦想,人类文化的“巴别塔”将在技术的基石之上重建。
Facebook的全新翻译系统到底表现如何?
在由机器翻译大会(WMT)提供的公开标准数据包上的测试表现来看,Facebook全新的翻译系统的性能要远超RNNs2。尤其是在CNN模式下的WMT 2014 英语-法语测试中,要比之前的最佳纪录提高了1.5个BLEU值。BLEU(Bilingual Evaluation Understudy)是运用最广泛的机器翻译准确度评判标准,系统认为,机器翻译结果越接近人工翻译,那么翻译质量就越高。

图丨机器翻译评判标准之一的BLEU
此外,Facebook全新的翻译系统在WMT 2014 英语-德语测试中,将此前的纪录提高了0.5个BLEU值,在WMT 英语-罗马尼亚语测试中,也将最好成绩提高了1.8个BLEU值。
神经网络在机器翻译这种实际应用中表现的衡量标准还包括,系统接收到一个句子后,会花多长时间翻译出来。Facebook全新的CNN模型拥有非常高效的计算能力,比已经很强大的RNN系统还要快9倍。Facebook的研究团队主要将精力放在了通过量化权重和蒸馏等方法来加速神经网络,这些方法其实潜力极大,在未来还将进一步大幅提高CNN模型的速度。
Facebook全新架构中的一个显著特征在于multi-hop注意力机制。这种机制类似于人类在从事翻译工作时,会将句子进行分解,而不是一次将句子看完,然后头也不回的直接进行翻译。这个神经网络也会在翻译过程中不断的回头看句子,并选择接下来要翻译的词语。
这一点与人类在翻译过程中会经常回顾句中的关键词的行为非常类似,比如,首次回顾关注的是动词,那么第二次回顾时就会关注相关的助动词。
 图丨One-Hop与Multi-Hop对比
图丨One-Hop与Multi-Hop对比
该系统的另一个重点是“门控”(Gating),它控制神经网络中的信息的具体流向,给它们指定最佳的处理单元,从而得到最好的翻译结果。打个比方,如果说神经网络会要做的是搜集所有已经完成的翻译结果,那么门控要做的就是进行精确地筛选,使它最适合当前的语境。
但是,也开始有越来越多的人担忧,经常使用机器去翻译某些常用的特定语言,会使得那些不常使用的语言被进一步边缘化。这就是为什么机器翻译其实有可能会加速濒危语言、甚至文化的消亡。
语言学家们举了一个通俗的例子,比如卫星电视服务,那些经常被电视台使用的语言会逐渐变得更流行更受欢迎,而不经常出现的语言则会渐渐被人们遗忘。
技术的进步是否会进一步加速小众语言、甚至文化的消亡?
Google、Facebook等科技巨头们正在研发的机器学习技术将极大加快不同主流语种间的转换效率,这个已经没有疑问了,但它是否能成为保护小众语言的利器?
 图丨语言学家Sebastian Drude 在研究巴西的印第安语言Awetí
图丨语言学家Sebastian Drude 在研究巴西的印第安语言Awetí
这是一个很有远见的设想,但问题是机器翻译依赖于大量被标记的数据。这些数据集是由人工翻译的各种语言的大量书籍、文章和网站组成。机器学习算法就像罗塞达石碑(石碑上用希腊文字、古埃及文字和当时的通俗体文字刻了同样的内容)一样,数据集越大,学习效果越好。
然而对于大多数语言来说,这种庞大的数据集根本不存在。这就是为什么目前机器翻译只能够翻译最常见的几种语言。例如,Google翻译只能处理90种语言。
 图丨谷歌翻译
图丨谷歌翻译
因此语言学家面临的一个重要挑战就是需要找到一种方法,可以自动分析那些小众语言,以便让计算机更好地理解它们。
最近,德国慕尼黑大学的Ehsaneddin Asgari和Hinrich Schutze表示他们已经在这方面取得了关键性突破。他们展示的新方法揭示了几乎适用于任何语言的重要元素,这些元素可以很好地帮助机器翻译。
这个新技术是基于一个已被翻译成至少2000种不同的语言的单一文本:《圣经》,语言学家早已认识到它的重要性。

因此,他们创建了一个名为“平行《圣经》语料库”的数据库,这其中包含了用1169种语言翻译的《新约》。然而这个数据集还不足以用于Google和其他商用机器翻译系统。所以,Asgari和Schutze提出了另一种方法:分析不同语言中,各种时态的表达方式。
大多数语言都会使用特定的单词或字母组合来表示时态。所以这个新方法的小技巧是利用人工去识别一些语言中时态出现的信号,然后采用数据挖掘来搜索其他语言,找到扮演相同角色的单词或字符串。
例如,在英文中,进行时是用“is”来表示,将来时态用“will”,而过去时用“was”。当然这些词也有其他含义。
Asgari和Schutze的想法是在《圣经》的英文翻译中找到所有这些词,以及其他语言中相对应的例子。然后查找在其他语言中扮演相同角色的单词或字母串。例如,字母“-ed”在英语中也表示过去时态。
值得注意的是,Asgari和Schutze不是以英语作为一开始的基准。因为英语是一种比较古老的语言,有许多例外的情况,这会使得机器很难学习。
 图丨古英语写成的文章
图丨古英语写成的文章
相反,他们从根据其他语言混合发展而成的克里奥尔语系(Creole Language)开始。因为这种语言出现得较晚,它还没有足够长的时间来发展出丰富的语言特质。这意味着它们通常包含更明显的语言特征标记,譬如时态。
两位德国学者表示:“我们的依据是,克里奥尔语比其他语言更为规范,因为这个语系很年轻,并没有积累那些容易让计算分析更复杂的‘历史包袱’。”
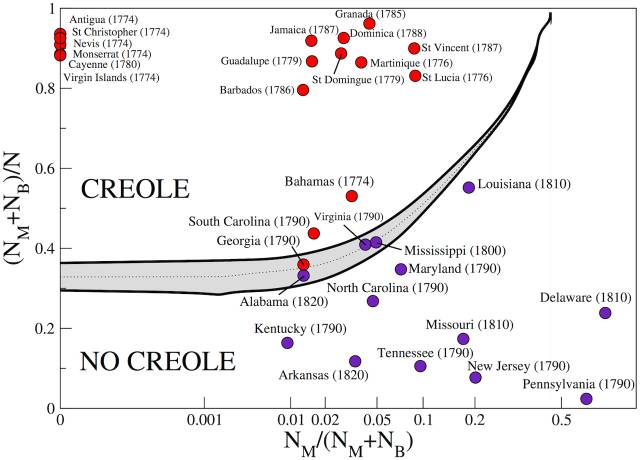
图丨克里奥尔语于17-18世纪出现于北美和加勒比海地区,用于欧洲殖民者与奴隶的交流
这其中之一是塞舌尔(Seychelles)克里奥尔语,它使用“ti”这个词来表示过去时。例如,“mon travay”是指“I work”,而“mon ti travay”意味着“I worked”,“mon ti pe travay”意思是“I was working”。所以对于判断过去时来说,“ti”是一个很好的指示符列表。
Asgari和Schutze编译了10种其他语言的过去时态指示符列表,然后在“平行《圣经》语料库”中,把用于执行相同功能的其他语言的单词和字符串挖掘出来。对于现在进行时和一般将来时他们也采用了相同的方法。
实验的结果非常有趣,这项技术揭示了与一般常用语言有关的语言学结构,并创建一张关联图,显示使用相似时态结构的语言是如何联系的(如下图)。
 图丨上图显示了100种语言的过去时态指示符是如何聚类在一起的
图丨上图显示了100种语言的过去时态指示符是如何聚类在一起的
Asgari和Schutze开发的机器学习算法可用来分析人们在超过1000种语言中使用过去、现在和未来时态的方式。这是迄今为止最大的跨语言计算研究,所涉及的语言数量比其他类型的研究甚至大一个数量级。
这项工作有很重要的应用价值。语言时态关联图允许研究人员快速找出不同语言之间的关系以及它们是如何联系的,这可以用来更好地理解语言的进化与演变。Asgari和Schutze表示:“我们所需的只是几千种语言的语言特征,而不是要求这几千种语言被完全标记。”
机器学习在语言学领域的应用,对我们理解语言本身、世界变化的方式,以及“机器如何理解语言”将产生深远的影响。这个新兴的学科使得许多语言能够直接以文字和语音的形式翻译成其他语言。
事实上,这个新兴学科的目的就是通过人工智能技术,来实现机器的即时翻译,最终胜过人类的同声传译,甚至更进一步帮助全球各种语言使用者们实现无障碍交流。










