聊天机器人见得多了,聊天机器医生你听过吗?

智东西 文 | Lina
随着人工智能技术的发展,AI也开始逐步在各行各业中落地应用,发挥自己的价值,其中医疗由于涉及国计民生,并且行业较为传统,有不错的发展空间,自然也就成了一块被众人看好的AI应用领域。2017年里,“AI+医疗”已经成了一个逐渐火热的话题,智东西此前也在医疗影像识别、辅助问诊、医疗单据数据化等领域做过相应采访。
今天,智东西来到了另外一家AI医疗创业公司康夫子,与创始人兼CEO张超聊了聊。据张超介绍,康夫子专注于为B端客户提供基于医疗数据的AI服务,核心技术包括知识图谱、NLP(自然语言处理)等,曾推出医疗预问诊系统“全科医生”、病历数据结构化服务等产品。
一、五年百度NLP经验


初见张超,瘦瘦高高的,戴着眼镜,笑容很灿烂。
据张超介绍,康夫子成立于2015年,至今已经经过了种子轮和天使轮两轮融资,目前A轮数千万元融资即将结束:其中天使轮融资将近一千万,由晨兴创投投资。
张超本人此前曾在百度搜索有5年的NLP部门资深研发工程师经历,同时也是文本知识挖掘方向负责人,并负责有关知识图谱和实体建模(这几项技术后文将会进一步解释)。而公司的另外两位合伙人也都是百度出身:分别是负责整体架构的前百度高级研发工程师张冲、以及技术合伙人/前百度NLP高级研发工程师栗晓华。目前康夫子的团队大约有30人,其中大部分都是百度NLP部门出身,约20人属于技术研发。
张超说,其实一开始有创业想法的时候,最早找的是张冲。“我是周三约的他,我们周五见的面,约的是新中关下面的星巴克,那时候他已经(从百度)离职了。”两人几乎是一拍即合,迅速敲定了发展方向。
栗晓华则是张超“六顾茅庐”请出来的人物。此前栗晓华跟张超在百度里是关系非常好的朋友,曾经几次三番因为“好朋友不要在一起创业”而拒绝了张超的邀约。

(从左到右:张超、栗晓华、张冲)
二、深耕知识图谱,团队经验丰富
作为同时出现在昨日国务院印发的《新一代人工智能发展规划》中的重点人工智能技术,NLP(自然语言处理)我们已经很熟悉了,比较很好理解;可“知识图谱”是个什么?
2012年5月,谷歌在其官方博客上发表了一篇名为《Introducing the Knowledge Graph: things, not strings》的文章,介绍了谷歌借助知识图谱,将搜索技术从关键词到实体的飞跃,也就是让机器学会理解关键词所代表的实际含义。
至此,知识图谱概念开始慢慢兴起。
张超介绍道,知识图谱就是实体和实体关系的总和,我们可以理解成一张由实体(entity)相互连接而成的语义网络。
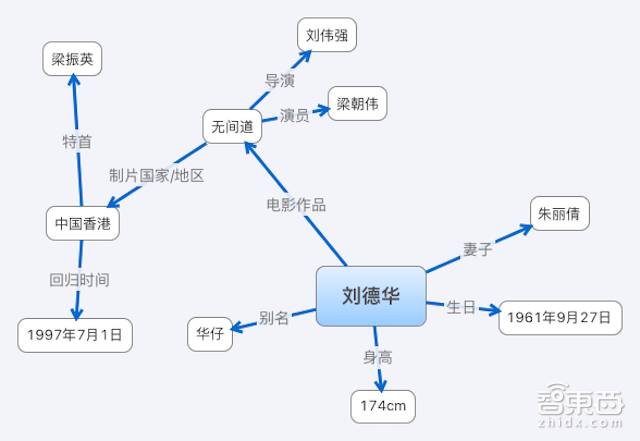
(图源:网友高天蒲《什么是知识图谱》)
在图中可以看到,通过实体的属性可以将不同的实体建立关联关系,例如:
1)刘德华 (实体)– 妻子(属性) -> 朱丽倩(另一个实体)
2)刘德华 — 电影作品 -> 无间道
3)无间道 — 制片国家/地区 -> 中国香港
最终得到的知识图谱就是一张实体和实体关系总和的图片。
以搜索引擎为例,随着数字信息的指数式增长,“关键词搜索”已经不能满足用户的精准需求了,搜索引擎需要识别出内容中出现的实体以及实体关系,准确理解用户的搜索意图,并给出精准的回答。而知识图谱中技术所面临的挑战又包括实体识别、消歧(重名,别名)、实体关系挖掘等,归根到底又是NLP自然语言处理的技术了。
张超说,知识图谱的构建需要通过信息抽取技术(Information Extraction, IE)来实现,而信息抽取技术现阶段并没有太好的解决方案。所以整体上来讲信息抽取是一门“熟练工种”的技术,“熟”才“能生巧”。由于康夫子的团队普遍具有多年的实战经验积累,曾基于百度大量语料库做过信息抽取,能够总结出适于实战的方法论,知道如何对数据进行快速结构化。
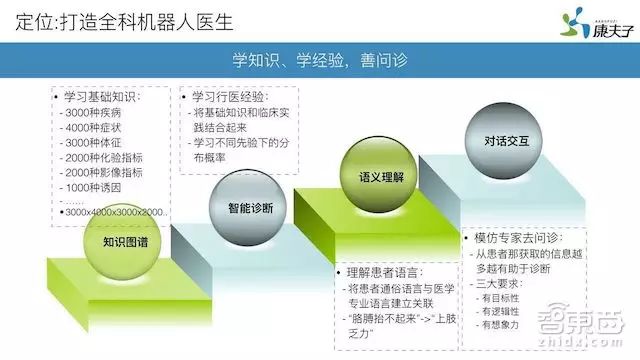
知识图谱的方法是清晰的:实体提取,关系提取,图谱存储和检索。但由于这仍是一门非常年轻的学科,单从论文、教科书上进行理论知识研究并不足够,需要在实践中将众多的“坑”一个个踩遍,才能真正落地到产业中去,得到成效。
“我们的优势是经验多,做得快,别人做一个维度需要一个月,我们只需不到一周。医疗有100多个维度,我们已经做到7、80维了。”张超带着点小自豪地对智东西说着。
三、基于知识图谱,打造三项医疗法宝
目前,康夫子的主要合作伙伴是为医院提供软件平台(比如HIS医院管理和医疗活动信息化系统)的企业,核心产品有以下几类:
1)“机器人全科医生”(医疗chatbot)
“机器人全科医生”其实是一个设立在医院挂号处的机器,内置了康夫子的预问诊系统,类似一个医疗类的聊天机器人(Chatbot)。在输入/点选了姓名、性别、年龄后,用户可以输入相应症状,比如“肚子疼得厉害”,系统将会模仿一个全科医生一样,一步步询问病患的病情,比如“腹痛最在是在什么时候出现的?”、“属于以下哪一种疼痛?”等等。

(图为康夫子全科医生的iOS SDK)
问到最后,系统将会告诉用户,根据以上症状,你有73%的可能是肠炎,需要去消化内科问诊。与此同时系统还会生成一个用专业医学术语描述的病历,并将这份病历发给消化内科的医生,提高了医患沟通效率,节省了时间成本。目前这套系统已经在张家港第一人民医院中进行线上测试了。
除了提高挂号效率外,未来这套预问诊系统还可以应用在急诊救护车上,在救护车运送患者途中,可以由救护人员预先采集患者信息,提前预备相应医生。
2)病历结构化
这么多年来,医院存贮的患者病历通常都是一段病情描述——这属于无结构化数据,非常不利于信息的检索与分类。而且医疗数据的维度普遍很高,光是高血压一项,就有“曾经诊断出、现在诊断出、未来可能诊断出”等不同结果。
再比如,“一名病患住院第一天没有咳嗽,第二天使用了某种药物时出现咳嗽,并在24小时内出现高烧”,在这个案例中,药物、住院历史、患者病情属于不同的关联文档,并且需要按照时间线排序分析,再加上各个查房护士对同一症状的描述方式可能不同,造成医疗数据异常纷繁复杂。
康夫子的做的就是将这众多数据进行结构化处理,最后得出一个可供医生点选搜索的病历平台。比如“患者性别=男”+“疾病名称=感冒”+“疾病史!=糖尿病”等等,最终得出2007年3月某日的某个用户病历。
3)临床辅助系统
跟前两项一样,康复子的临床辅助系统也是一套基于康夫子NLP(自然语言处理)技术的产品。这项技术将会植入到医生填写病历、开具药品、检查单的系统里,在根据医生填写的病历理解分析了患者病情后,系统会给出推荐的治疗方案。
不过,这个系统并不会改变医生的工作流程,医生填写病历、点选药物、开检查单等动作都与之前一模一样,唯一不同的是在填写完毕后系统会出现一个小弹窗:系统在分析完医生填写的病历后,会给予查漏补缺式的提醒(比如某两款药物也许存在冲突),医生可以选择听从它,又或者是直接忽略。
目前这款产品正在打磨阶段,张超表示,康夫子正在和一家三甲做医疗调研,预计年底将会上线。
四、从2C到2B,康夫子的转型之路
其实,2015年成立之初的康夫子最早定下的方向为:从孕妇群体切入,做饮食营养的知识图谱。基于基于孕妇人群对营养尤为看重这一基础,以孕妇的饮食分析为切入口,推出了孕食App;孕妇在App中记录饮食情况后,“饮食记录分析”功能,能根据内化的营养学知识图谱输出分析报告以及饮食建议。
然而,医疗类App首先面临着作为C端产品难以变现的问题,而这也是2014-2015年那一波兴起的互联网+医疗App所面临着的一个共性问题;其次,营养知识问题虽说是孕妇刚需,但它并不具备一个严格的标准,常常东家西家各执一词(比如究竟应该饭前吃水谷还是饭后吃水果……),很难让人信服。
2015年底到2016年初,团队开始思考转型之策。由于团队本身的强项仍旧是多年的知识图谱、文本分析技术积累,而医疗健康仍旧是康夫子看好的领域。几经考虑之下,2016年4月,团队最终决定转型B端,并且选择医学这类有严格界限,更加适合使用机器进行理解分析的领域。
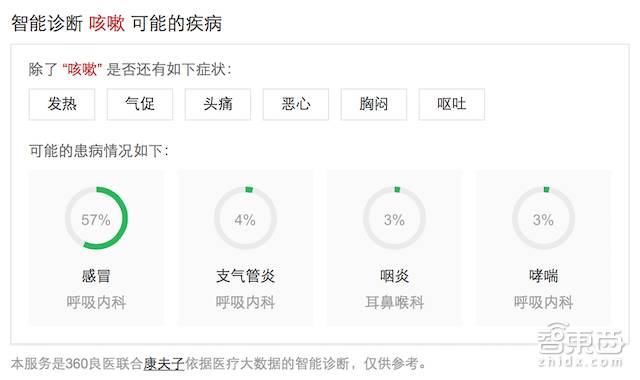
张超表示,目前康夫子的合作伙伴已经覆盖了全国前十大的HIS医疗信息化公司中将近一半的企业,其问诊交互服务也应在搜狗名医、360良医网站上线,当用户在这些网站搜索“咳嗽”或者“肚子疼”时,系统将会给出可能的疾病类型,比如“可能57%是感冒,4%是支气管炎,3%是咽炎……”
结语:从营养到医疗,初见成效的B端之路
在和张超交流的过程中会发现,在他身上有着和无数技术出身的创业者所类似的特质,逻辑思维清晰、执着、谈起技术来非常兴奋、并且对自己及团队的能力有着足够的信心与自豪。在经历过从C端到B端,从营养到医疗的转型后,康夫子的业务推进路线已经逐步成效初显,在优化问诊流程、医疗数据结构化方面有了不错的进展。
在这个医疗数据纷多繁杂的时代里,医疗信息的数据化、结构化、以及信息检索的重要性也日益凸显。在这样的背景下,有创业团队选择做医疗信息数据化的单据识别(比如智东西此前采访过的医拍智能),而康夫子选择的路线则是在数据化的基础上对数据进行结构化、图谱化处理,并且凭借公司创始人及团队在百度多年的经验与技术积累,打入医疗信息化企业,取得了不错的成果。

延伸阅读
点击下方图片直接阅读

往期回顾






