

《正文》
当你看这篇文章的时候,先参看一下《IV和GMM相关估计步骤,内生性、异方差性等检验方法》,里面有圈友提议详细做一期动态面板命令方面的,所以咱们就敲定了这篇工具类型文章。当然这篇文章不仅仅讲解了xtabond2,还有xtabond,xtdpdsys,xtdpd和xtdpdml这些动态面板Stata命令。只不过xtabond2可以涵盖其他类型命令,所以我们就着重解析了xtabond2。
xtabond2总体而言,在设计思路上可以取代xtabond(difference GMM)和xtdpdsys(System GMM),因为他的语法更加灵活和复杂一些,可以通过设置参数来做前面这两个动态面板回归的操作。这些动态面板回归都尤其适用于那些N比较大,T比较小的数据中。不过他们这三个的具体执行步骤是不同的。
A problem with the original Arellano-Bond estimator is that lagged levels are poor instruments for first differences if the variables are close to a random walk(xtabond使用的工具变量有时候表现很不好). Arellano and Bover (1995) describe how, if the original equation in levels is added to the system, additional instruments can be brought to bear to increase efficiency. In this equation, variables in levels are instrumented with suitable lags of their own first differences(然后xtdpdsys就改进了工具变量的选择方式,不仅包括levels还有differences).The assumption needed is that these differences are uncorrelated with the unobserved country effects(要求假定这些differenced过后的工具变量与不可见的个体效应不相关). Blundell and Bond show that this assumption in turn depends on a more precise one about initial conditions.

xtabond2的语法格式:
xtabond2 depvar(因变量) varlist(系列解释变量:前置变量、严格外生变量、内生变量) [条件筛选] [回归区间][, level(置信区间) twostep(表明计算two step估计量而不是one step估计量) robust(如果前面选择了twostep,那么就必须选择这个robust) cluster(用来重新命名Panel变量,就是说改变之前的id) noconstant(在level equations中不要常数项) small(用t统计量和F统计量,而不是用z统计量和Wald统计量来评估回归显著性) noleveleq(如果有这个命令,那工具变量中就只有difference equations,没有了level equations,因此就等同于做了difference GMM) orthogonal gmmopt [gmmopt ...] ivopt [ivopt ...] pca components(主成分部分) artests(自相关检验的最大阶数) arlevels(标明自相关检验用于level equations) h(这个选项一般不影响大局) ]
上面的gmmopt指的是, gmmstyle(varlist [, laglimits(对于transformed或者level equations,这个选项规定了工具变量选择的前后日期) collapse(只为每个变量和滞后距离创造一个工具变量,而不是每一个时间段都创造一个工具变量,减少了工具变量个数) orthogonal(这是用向后orthogonal deviations方法来创造工具变量,主要是与difference GMM连着用,比传统的AR(1)difference GMM更加稳定无偏) equation({diff | level | both}) passthru split(仅仅用于system GMM和没有规定equation(),主要是把工具变量分成2组来做difference-in-Sargan/Hansen testing)])
上面ivopt指的是,ivstyle(varlist [, equation({diff | level | both}(表示哪个equation用前面的那个工具变量)) passthru (这个命令在equation(diff)和nolevelleq用了之后使用)mz(工具变量中Missing值就换成0)])#注意的是,如果x变量是个前置变量,那作为level equation的工具变量是可以的,但是现在就不能用ivstyle选项,而是后面这个iv(x, eq(level))。
On balanced panels, GMM estimators based on the two transforms return numerically identical coefficient estimates, holding the instrument set fixed (Arellano and Bover 1995). But orthogonal deviations has the virtue of preserving sample size in panels with gaps. If some e_it is missing, for example, neither D.e_it nor D.e_i,t+1 can be computed(xtabond2在MATA程序中是用forward orthogonal deviations方法来消除固定个体效应,即一个第t期的变量减去t期之后所有日期的平均数值,这与我们时常用的first difference不太一样,因为这种方式保证不了所有日期都能够获得数值)。
Autocorrelation indicates that lags of the dependent variable (and any other variables used as instruments that are not strictly exogenous), are in fact endogenous, thus bad instruments(xtabond2会报告自相关检验情况,如果有自相关情况,那表明这些工具变量并不好). For example, if there is AR(s), then y_i,t-s would be correlated with e_i,t-s, which would be correlated with D.e_i,t-s, which would be correlated with D.e_i,t.
So for one-step, robust estimation (and for all two-step estimation), xtabond2 also reports the Hansen J statistic, which is the minimized value of the two-step GMM criterion function, and is robust. xtabond2 still reports the Sargan statistic in these cases because the J test has its own problem: it can be greatly weakened by instrument proliferation (xtabond2会报告Hansen J统计指标和Sargan指标来检验过度识别问题)。
To compensate, xtabond2 makes available a finite-sample correction to the two-step covariance matrix derived by Windmeijer (2005). This can make two-step robust estimations more efficient than one-step robust, especially for system GMM (xtabond2反正用了一些方式让他的回归更加有效率和稳健)。

Xtabond2操作示例:
GMM估计包括一步(One-Step)和两步(Two-Step)的GMM。两步估计的权重矩阵依赖于估计参数且标准差存在向下偏倚,并没有带来多大的效率改善且估计量不可靠,一步估计量尽管效率有所下降但它是一致的,因而在经验应用中人们通常使用一步GMM估计。理论上,一步系统广义矩估计(One-StepSystemGMM)利用了比一步差分广义矩估计(One-stepDifference-GMM)更多的信息,前者可以解决后者不能解决的内生性和弱工具变量问题,因而前者比后者的估计结果更有效。Blundell and Bond利用蒙特卡罗模拟实验也证实,在有限样本下,系统GMM比差分GMM估计的偏差更小、效率也有所改进。
>use http://www.stata-press.com/data/r7/abdata.dta
>xtabond2 n l.n l(0/1).(w k) yr1980-yr1984, gmm(l.n w k) iv(yr1980-yr1984, passthru) noleveleq small
是检验扰动项的差分是否存在一阶与二阶自相关,以保证GMM的一致估计,一般而言扰动项的差分会存在一阶自相关,因为是动态面板数据,但若不存在二阶自相关或更高阶的自相关,则接受原假设“扰动项无自相关”。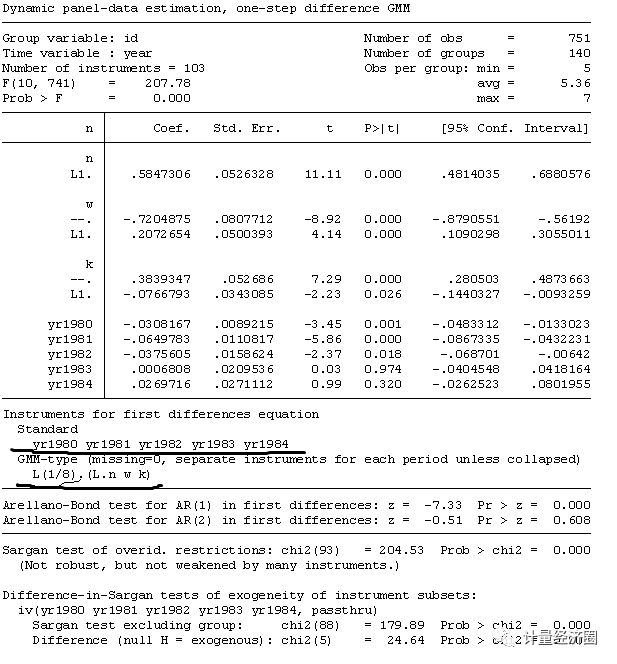
Arrellano-Bond test for AR(1/2) in first differences,是检验扰动项的差分是否存在一阶与二阶自相关,以保证GMM的一致估计,一般而言扰动项的差分会存在一阶自相关,因为是动态面板数据,但若不存在二阶自相关或更高阶的自相关,则接受原假设“扰动项无自相关”。
对于最下面的这些Sargan test of overid. restrictions和Difference-in-Sargan tests of exogeneity of instrument subsets,原假设是这些instruments valid, 因此p不显著,不reject原假设就是好的具体见这篇文章Roodman 2008 revised Note on too many instruments.pdf.pdf
两步GMM会严重低估回归系数的标准误差;当标准误差很小的时候,回归系数的显著性检验当然是拒绝的(例如p<0.05)。所以当两步GMM没有纠正这个偏差的时候,通常得到的回归系数都是非常显著的(例如p<0.01或者p<0.001)。
但是这个结果是有很大的误差的,所以两步GMM必须通过加vce(robust)纠正这个误差。以下那个论文专门讨论了这个问题。因此,两步GMM必须纠正这个误差,在目前已经算是一个共识了。
> xtabond2 n l.n l(0/1).(w k) yr1980-yr1984, gmm(l.n w k) iv(yr1980-yr1984, mz) robust twostep small h(2)
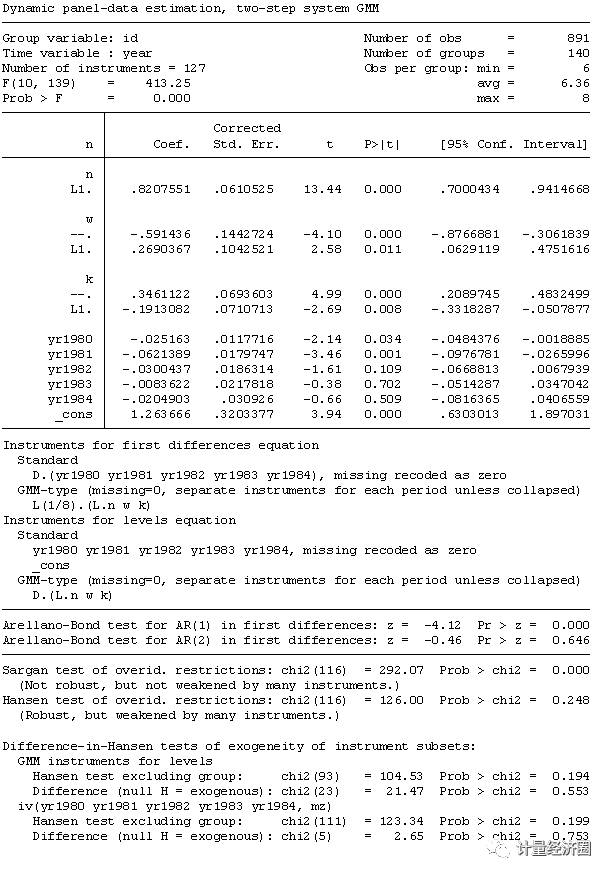
以上的Sargan检验拒绝了overidentification restrictions,但是Hansen检验失败拒绝overidentification restrictions,可能是因为Hansen检验比Sargan检验更稳健。例如,在异方差情况下,Sargan检验不具有卡方分布,但是Hansen检验却具有卡方分布,因此如果这个问题出现了,那Sargan可能错误地拒绝原假设。不过,像这种有很多工具变量的估计,其他的问题也完全可能出现,从而导致上面的结果出现。
关于工具变量的选择问题,可以看看下方的合并图,一个是以differenced equations作为工具变量,另一个是以level equations作为工具变量。

> xtabond2 n L.n L(0/1).(w k) yr1978-yr1984, gmm(L.(w k n), collapse) iv(yr1978-yr1984, eq(level)) h(2) robust twostep ##通过collapse选项,我们减少了工具变量的数目,这样有利于做诸如overidentification 检验。


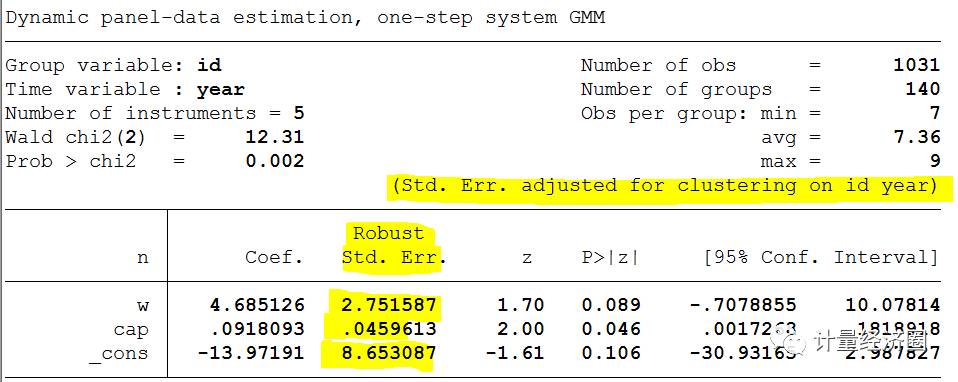
> xtabond2 n w cap [pw=_n], iv(cap k ys, eq(level)) iv(rec, eq(level)) cluster(id year) h(1) # Cluster主要考虑组内(比如以id为组,year为组)相关问题。
1. with cluster
2. without cluster
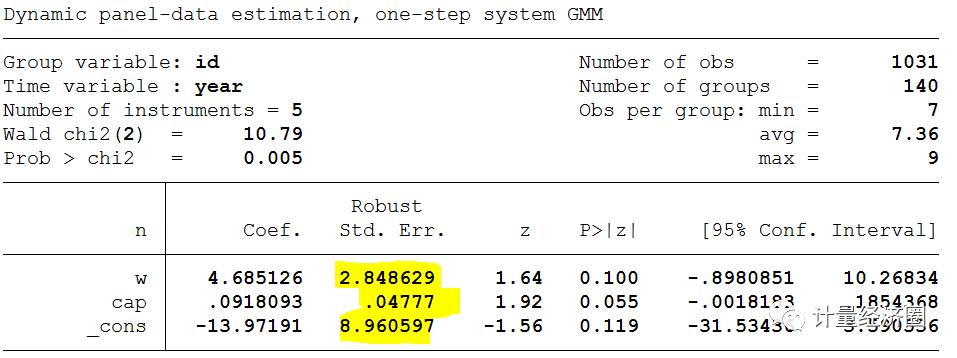
xtabond2是默认把ivstyle里面的变量都取滞后项同时作为差分、水平方程的工具变量;xtdpdsys默认只用于差分方程,并且,xtdpdsys将没有设定为内生或先决变量的都自动作为外生变量,将其滞后项用作工具变量估计差分方程;
xtabond2中可以有一部分在前面的回归变量中列出,但既不列入gmmstyle,也不列入ivstyle,这样就不参与差分和水平方程的估计了(主要是一些滞后项)。
xtdpd的灵活性基本跟xtabond2一样,但更加简洁,就是可以直接、分别地设定差分估计和水平估计中采用gmm形式(一个多列矩阵)和iv形式(一个包含自身滞后的列向量)的变量。
>webuse abdata, clear
>xtabond2 n L.n, gmm(n, laglimits(2 .)) small h(2)
用xtabond2做了一个与xtdpd相同的回归,不过xtabond2报告的检验更多,而xtdpd需要通过下一步estab来做检验。
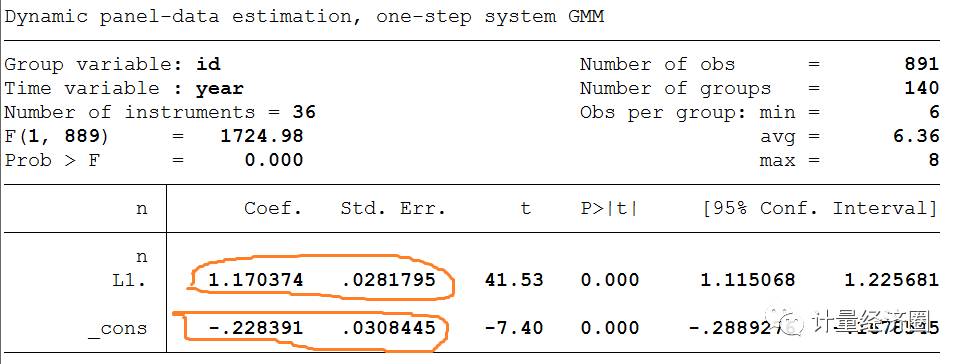

下面我们用xtdpd也可以得到一样的回归结果,请看划线部分与上图对比。
> xtdpd n L.n, dgmm(n, lagrange(2 .)) lgmm(n, lag(1)) vce(r)
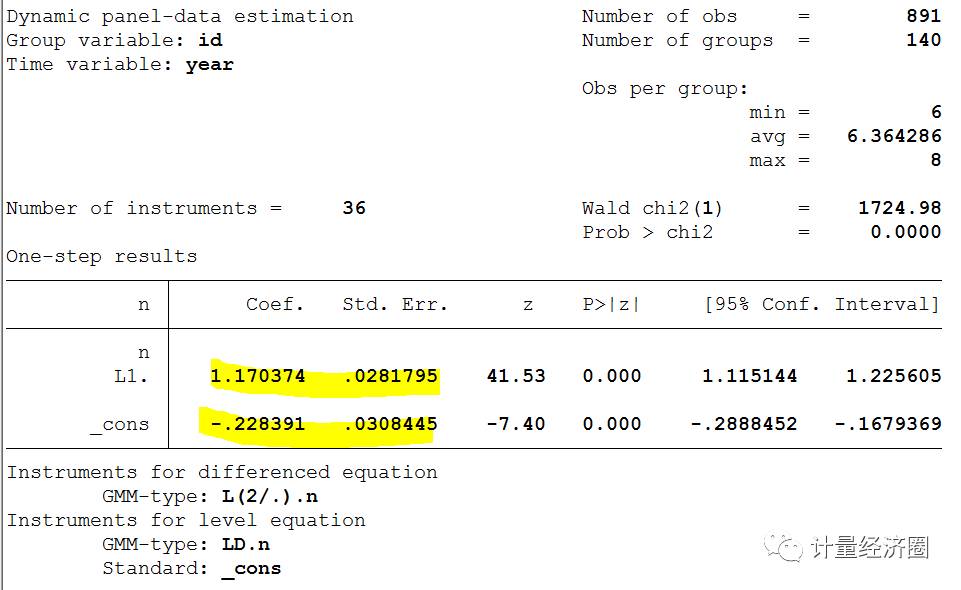

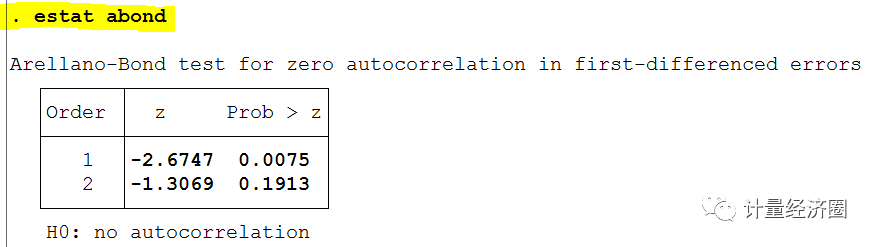

还想要介绍一个类似的动态面板回归命令xtdpdml(似然法估计的)
Paul Allison, Enrique Moral-Benito, and Richard Williams are currently working on a project entitled "Dynamic Panel Data Modeling using Maximum Likelihood." Panel data have many advantages when trying to make causal inferences but can also be difficult to work with. We show that ML provides an alternative to widely used GMM methods such as Arellano-Bond and is superior in many cases. We have prepared a Stata command called xtdpdml that greatly simplifies the process of estimating our models.

《END》
写在后面:各位圈友,一个等待数日的好消息,是计量经济圈应圈友提议,09月04日创建了“计量经济圈的圈子”知识分享社群,如果你对计量感兴趣,并且考虑加入咱们这个计量圈子来受益彼此,那看看这篇介绍文章和操作步骤哦(戳这里)。加入社群之后一定要看“群公告”,不然接收不了群信息。












