|
|
专栏名称: EasyCharts
| EasyCharts,易图表,我们将定期推送各种数据可视化与分析教程,包括Excel(Power BI)、Origin、Sigmaplot、GraphPad、R、Python、Matlab、Tableau、D3.js等。 |
目录
相关文章推荐

|
前端大全 · B站员工向代码投毒“封杀”用户账号,并放话: ... · 2 天前 |

|
前端早读课 · 【早阅】Chrome 133+ 全新 ... · 昨天 |
|
|
新疆司法行政 · 法润天山·微动漫丨土地承包经营权是否属于遗产范围? · 2 天前 |
|
|
新疆司法行政 · 法润天山·微动漫丨土地承包经营权是否属于遗产范围? · 2 天前 |
|
|
青海政务 · 2025,聚焦青海两会 · 2 天前 |
|
|
青海政务 · 2025,聚焦青海两会 · 2 天前 |
|
|
大庆晚报 · 电气火灾预防措施你了解吗?|萌萌油油话安全 · 2 天前 |
|
|
大庆晚报 · 电气火灾预防措施你了解吗?|萌萌油油话安全 · 2 天前 |

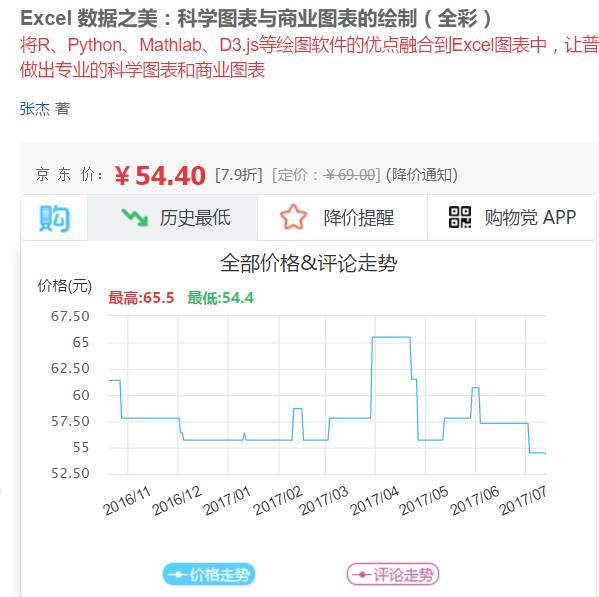
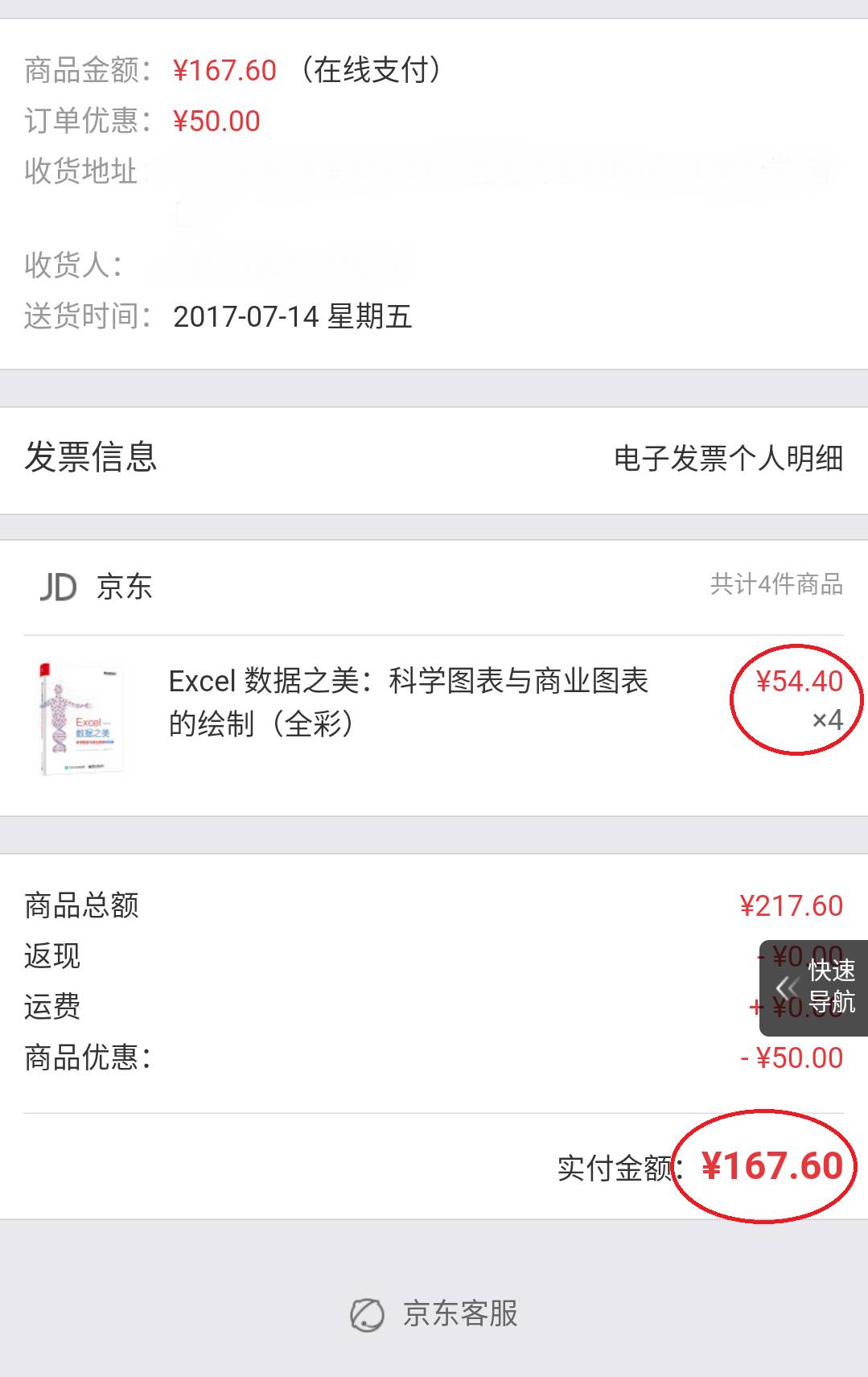









推荐文章
|
|
前端大全 · B站员工向代码投毒“封杀”用户账号,并放话:“拿着一天几千的工资整你”!现已被开除 2 天前 |
|
|
前端早读课 · 【早阅】Chrome 133+ 全新 DOM 操作方法:moveBefore 昨天 |
|
|
新疆司法行政 · 法润天山·微动漫丨土地承包经营权是否属于遗产范围? 2 天前 |
|
|
新疆司法行政 · 法润天山·微动漫丨土地承包经营权是否属于遗产范围? 2 天前 |
|
|
青海政务 · 2025,聚焦青海两会 2 天前 |
|
|
青海政务 · 2025,聚焦青海两会 2 天前 |
|
|
大庆晚报 · 电气火灾预防措施你了解吗?|萌萌油油话安全 2 天前 |
|
|
大庆晚报 · 电气火灾预防措施你了解吗?|萌萌油油话安全 2 天前 |

|
GS乐点 · 这里,是现在看同志剧的最后阵地 7 年前 |

|
百思不得姐 · 鱼戈手机私藏(今天最爆笑的5张图) 7 年前 |

|
灼见 · 北大教授万字长文:这次知识革命,淘汰的不是工具,是人! 7 年前 |

|
中国网 · 夜读 | 最厉害的人是能自控的人 7 年前 |

|
Linux爱好者 · 面向对象:没时间了,合适的就来撩吧 7 年前 |