正文

AI 研习社按,Kaggle 上有各式各样的数据挖掘类比赛,很多参赛者也乐于分享自己的经验,从他人的经验中进行总结归纳,对自己的实践也非常重要。
本文将以 Kaggle 上 6 个不同的比赛为例,介绍常见的三类数据(结构化数据,NLP 数据,图像数据)分析经验,以助力大家提升数据分析能力。此文为上篇,主要介绍结构化数据和 NLP 数据,包含 Titanic 比赛,房价预测比赛,恶意评论分类,恐怖小说家身份识别。
正文如下,AI 研习社编译整理:
建立准确模型的关键是全面了解正在使用的数据,但数据通常是混乱的。在我自学机器学习的前几个月,对如何理解数据并没有很多的想法。我假设数据来自一个自底向上组织完好的包,或者至少有一组明确的步骤可以遵循。
查看别人的代码之后,我发现大家理解、可视化和分析相同数据集的方式是不同的,对此我很震惊。我决定通读几种不同的数据分析方式,找出其中的异同点,并提炼出一套理解数据集的最佳实践或策略,以便更好地利用它们进行数据分析。
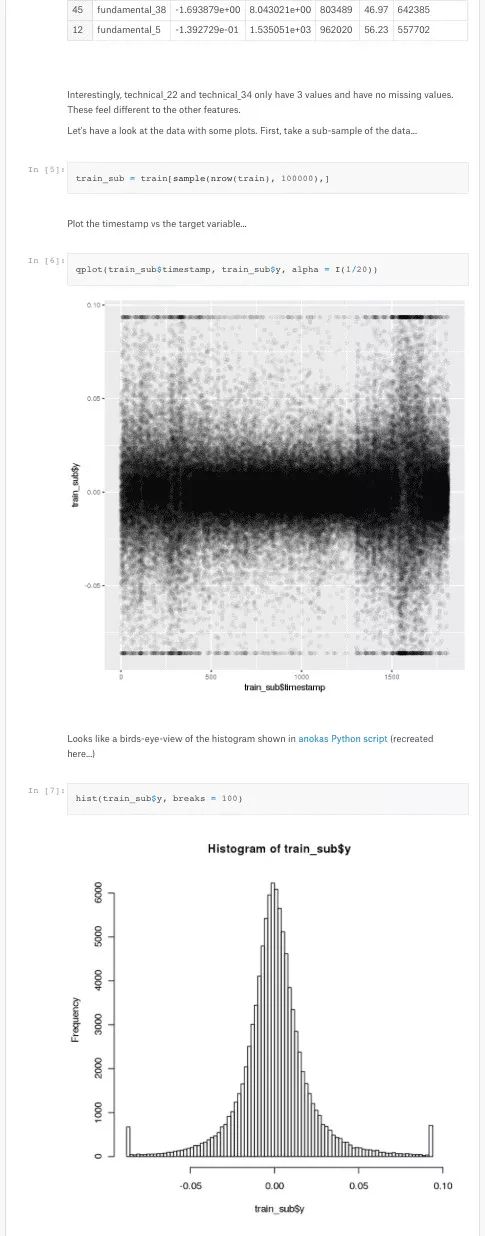
数据科学家会花大量时间在数据预处理上,而不是模型优化问题上。
——
lorinc
本文中,我选择了一些在
Kaggle
上公开的
探索性数据分析
(EDA)。这些分析将交互式代码片段与文章结合在一起,有助于提供数据的鸟瞰图或梳理数据中的模式。
我同时研究了
特征工程
,这是一种获取现有数据并用一些方法将其转化,赋予数据其他含义的技术(例如,获取时间戳并提取 DAY_OF_WEEK 列,这些列可用于预测商店中的销售情况)。
我想看看各种不同的数据集,所以我选择了:
结构化数据
结构化数据集是包含训练和测试数据的电子表格。电子表格可能包含分类变量(颜色,如绿色、红色和蓝色),连续变量(年龄,如 4、15 和 67)和序数变量(教育程度,如小学、高中、大学)。
训练数据表中包括一个尝试解决的目标列,这些列不会出现在测试数据中。我所研究的大部分 EDA 都侧重于梳理出目标变量与其他列之间的潜在关联性。
我们的主要目的是寻找不同变量之间的关联性,有很多切分数据的方法。可视化的选择更多。
特征工程可以让你充分发挥想象力,不同参赛选手在合成特征或将分类特征合并为新特征时,都有不同的方法。
让我们更深入地看看
Titanic competition
和
House Prices competition
这两项比赛。
Titanic

图片来自 Viaggio Routard
Titanic 比赛非常受初学者欢迎,很多 Kaggle 用户都不断参与这个比赛。因此,这个比赛的 EDA 往往写得很好,并且有详细记录,是我看到的最清晰的。
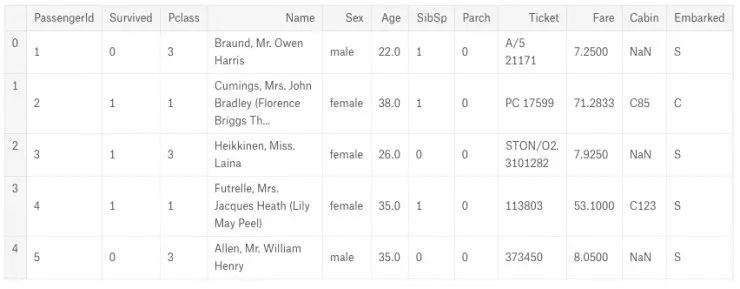
数据集包括一个训练集电子表格,其中包含一列「Survived」,表示乘客是否幸存,以及其他补充数据,如年龄、性别、票价等等。
我选择用于分析的 EDA 是由 I,Coder 提供的
EDA to Prediction Dietanic
,déjà vu 提供的
Titanic Survival for Beginners EDA to ML
,katerina Kokatjuhha 提供的
In Depth Visualisations Simple Methods
。
所有这三种 EDA 都以原始指标开始。
I,Coder 描述的数据集
数据预处理过程中对空值或缺失值进行处理是关键一步。本文选取的三个 EDA,一个在前期处理了这一问题,另外两个在特征工程阶段进行处理。
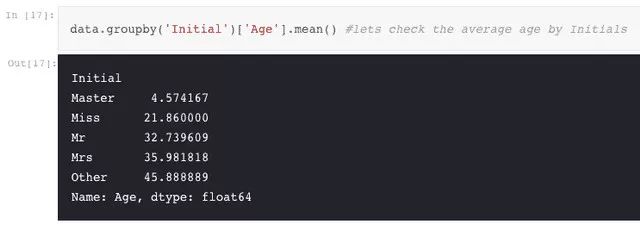
I,Coder 反对指定一个随机数来填补缺失的年龄:
正如我们前面看到的,Age 特征有 177 个空值。要替换这些 NaN 值,我们可以为它们指定数据集的平均年龄。但问题是,有许多不同年龄段的人,我们不能把 4 岁小孩的平均年龄分配到 29 岁。有什么方法可以找出乘客的年龄段?我们可以检查名称特征。在这个特征中,我们可以看到像先生或夫人的称呼,我们可以将先生和夫人的平均值分配给各个年龄组。
I, Coder 输入的年龄
I,Coder 将特征工程作为纯数据分析的一部分,然而其他两位作者认为它是一个独立的步骤。
这三位 kernel 作者在深入了解数据、找出数据间潜在相关性时,都非常依赖图表和可视化。他们使用的图表包括因子图、交叉表、条形图、饼图和小提琴图(结合箱线图和密度图特征的一种图)等等。
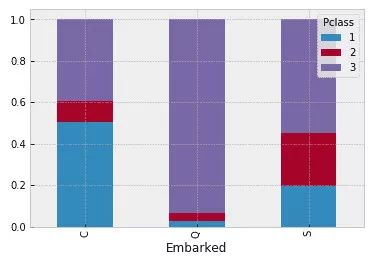
deja vu 关于幸存者性别的图表
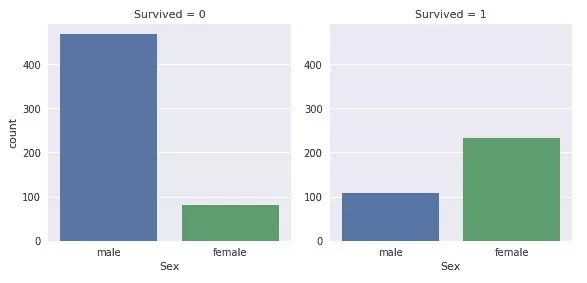
你可能对泰坦尼克号中的「女性与儿童优先」这句话很熟悉。在最初的数据分析中,对每位作者来说,年龄和性别这两个特征很重要。也可以对收入背景(如票价所示)进行一些详细的检测。
船上的男性比女性多很多。尽管如此,幸存的女性几乎是幸存男性的两倍。女性在船上的幸存率约为75%,而男性约为18-19%。
——I,Coder
Jekaterina 和 I,Coder 都是基于对图表和数据的视觉检测得出结论,如 Jekaterina 所写:
Jekaterina 绘制的反映船舱等级和救生船的图表
Deja Vu 的 EDA 在分析的每一步都记录了一个准确的数字,就每个特征对最终预测的重要性提供了一个很好的反馈。
特征工程
三位 kernel 作者的特征工程存在很多可变性。
每位作者选择不同数量的 bucket 作为连续变量,如年龄和票价。与此同时,他们都以不同的方式处理家庭关系,I,Coder 建立了一个 SibSip(血亲关系)——是独自一人还是与家人(配偶或兄弟姐妹)一起(family_size 和 alone),Jekaterina 则列出了一个客舱bin,并提出以 child(儿童)或 adult(成人)作为特征。
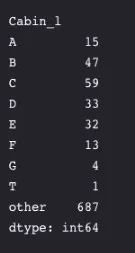
Jekaterina 列出的客舱等级字母
I,Coder 在剔除不相关的列时特别激进:
名称 —>我们不需要名称特征,因为它不能转换为任何分类值。
年龄 —>我们有 Age_band 特征,所以不需要这个。
船票 —>它是不能被分类的随机字符串。
票价 —>我们有 Fare_cat 特征,所以不需要。
客舱 —>有许多缺失值,也有许多乘客有多个舱位。所以这是一个无用特征。
票价范围 —>我们有 Fare_cat 特征。
乘客身份 —>无法分类。
对于填补步骤,Jekaterina 写道:
她确保新的填充数据不会破坏平均值,进行了总结了:
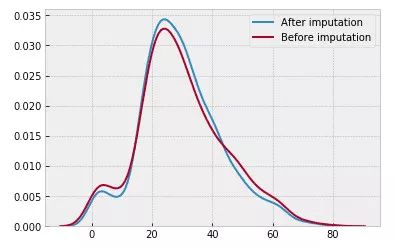
Jekaterina 检测新输入值是否破坏均值
点评
三位作者都有检查数据并描述整体形状。
I,Coder 考虑了整体的缺失值,而 Jekaterina 在接近尾声时才开始考虑。
每个人都着眼于幸存者的分类,然后按性别分类幸存者。交叉列表、因子图和小提琴图都是常用的图表。Jekaterina 还绘制了一些非常有趣的图表。
当涉及到特征工程时,作者们有些分歧。作者在构建新特征的问题上存在差异,一些人将其视为一个独立的步骤,另一些人则在初步数据分析时对其进行处理。围绕分箱的选择各不相同,随着年龄、产权和票价的不同,所收到的 bucket 数量都不同,并且只有 Jekaterina 构建了一个离散的 child/adult(儿童/成人)特征。
对于缺失值的填充方法也不同。I,Coder 建议查看现有数据以预测估算值,而 Jekaterina 确保她的估算数据不影响均值。
他们在思考和处理数据上有一些明显的相似之处,主要是在可视化和特征工程上有些差异。
房价

该图由美国顾问团提供
房价预测是另一种结构化数据比赛。它比上面的 Titanic 比赛有更多的变量,包括分类、顺序和一些连续特征。
我所选择的用来分析的 EDA 是 Pedro Marcelino 的
Comprehensive Data Exploration with Python
,Angela的
Detailed Data Exploration in Python
,以及Sangeon Park的
Fun Python EDA Step by Step
。
虽然这些数据在类型上类似 Titanic,但实际上复杂得多。
在爱荷华州埃姆斯住宅问题中,有 79 个解释变量用来描述这些房子的方方面面。该竞赛要求你预测每间房的价格。
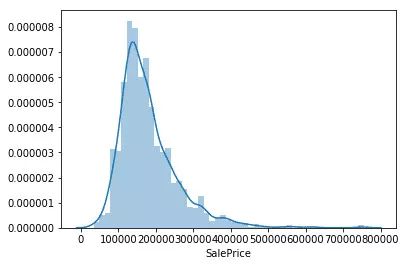
Pedro 描绘了售价
Angela 和 Pedro 花了一些时间来研究与 Titanic 比赛中类似的原始数据。Angela 在直方图上画出了售价,并绘制了关于这些特征的热图。而 Pedro 也描绘了售价,并得出了以下结论:
之后,Pedro 将自己置于买家的角度,猜测哪些特性对他来说很重要,从而来看他的选择和售价之间的关系。之后,他建立了一个热图,让自己对特征有更加客观的观察。
与售价相关的特征图
相比之下,Angela 以一种更加客观的方式来描述,她通过相关关系列出了数字特征,也描绘了与售价相关的特征图,从数据中寻找模型。
Sang-eon 果断剔除了缺失值和离群值(并使用线性回归估算了临界线附近的异常值),之后才开始描绘与售价相关的多方面特征。
Pedro 一直在寻找数据之间的相关性,以检查数据丢失问题。他提出:
-
丢失数据有多普遍?
-
丢失数据是随机的还是有模式的?
这些问题的答案对于实践很重要,缺少数据可能意味着样本容量的减少。这会阻止我们进一步的分析。从真实性的角度来看,我们需要确保数据丢失不会导致偏颇。
为解决这些问题,Pedro 绘制了缺失单元的总数以及百分比,并选择删除了 15% 或是更多包含缺失数据的单元格所在的列。他再次依赖主观选择来决定移除哪些特征:
……我们会错过这些数据吗?我不这么想。这些变量似乎都不是很重要,因为它们中的大多数都不是我们在购买房子时所要考虑的方面。此外,通过仔细观察变量,比如「PoolQC」、「MiscFeature」和「fireplacery」等变量很有可能导致异常值出现,因此我们很乐意删除它们。
Pedro 对缺失数据的处理方法是,要么删除整个列(如果它们包含有大量缺失值),要么删除只有少数缺失值的行。他还建立了一个启发式的解决异常值的方法:
最主要是设定一个阈值来定义观测值是否为异常值。为此,我们将数据标准化。在这种情况下,数据标准化意味着将数据值转换为平均值为 0,标准差为 1 的数据。
他的结论是,从静态的角度来看,没什么可担心的。但在重新审查了数据之后,他删除了一些觉得可疑的数据点。
特征工程
Sangeon 检查了数据的偏态和峰度,并做了一个 wilxocc -rank 测试。他用一个非常好看的 3D 图进行总结:
Sang-eon 的 3D 特征图
与此同时,Pedro 讨论了这些数据的正态性、同方差性、线性度和无相关误差,他将数据归一化,并发现其他三个问题也得到了很好的解决。
点评
这三个 kernel 的作者都没有做过多的特征工程分析,可能是因为数据集中已经有很多的特性了。
有很多策略来决定如何处理这些数据,有些作者采用了主观策略,有些则直接采用更加客观的测量。对于何时以及如何剔除缺失数据或异常值,他们没有达成明确的共识。
与之前 Titanic 竞赛相比,这里更多的关注于统计方法和完整性。可能是因为有更多的特征需要处理,也有可能是无效的统计结果会对整体产生更大的影响。
自然语言处理
自然语言或 NLP 数据集包含单词或句子。虽然核心数据类型与结构化数据竞赛中的相同,但用于自然语言分析的工具——文本是特定的,这会导致不同的分析策略。
在其原始形式中,语言不易被机器学习模型识别。为了将其转换为适合神经网络的格式,需要对其进行变形。一种流行的技术是
Bag of Words
(词袋),其中句子被有效地转换为 0 或 1 的集合,即特定单词是否出现。(不出现为 0,出现为 1)
由于需要转换数据,大多数 Notebook 的前几个步骤倾向于将文本转换为机器可读的内容,并且这一步骤都趋于相似。之后,大家的方法会出现很大差异,并对特征工程应用各种不同的可视化和技术。
恶意评论分类
我看到的第一个 NLP 比赛是
Toxic Comment Classifcation Competition
(恶意评论分类),包括一个数据集,其中大量数据来自维基百科讨论页面的评论,通过评论在等级上的得分,来区分是侮辱、淫秽,还是恶意评论等。参与者面临的挑战是预测给定评论的恶意标签。
我选择用于分析的 EDA 是 Jagan 的
Stop the S@#$ - Toxic Comments EDA
,Rhodium Beng 的
Classifying Multi-label Comments
和 Francisco Mendez 的
Don't Mess With My Mothjer
。
三位作者都从描述数据集开始,随机抽取了一些评论。虽然没有缺失值,但评论中有很多噪音,并且不清楚这种噪音在最终的数据分析中是否有用。
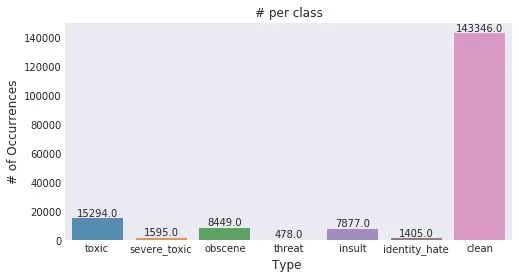
Jagan 绘制的恶意分类分布图
恶意程度在各个类别之中不是均匀分布的。因此,我们可能会遇到分类失衡问题。—— Jagan
Francisco 剔除掉无实际意义的词(例如「and」或「the」)。他用双标图绘制出一个特定单词最适合的类别。
双标图中,大多数单词都是正常排列的,也有一些例外,肥胖与厌恶有相关性,这很令人惊讶,因为它是图表底部唯一的非种族词语,图表中有一些通用的冒犯性词语,像die(死亡)这样的词语只与威胁有关。
Francisco 之后提出错别字和恶意之间是否存在关联。
显然是有的,而且令人惊讶的是,当 mother 这个单词拼写错误的时候从来都不会跟厌恶或威胁扯上关系,但当它拼写正确时,就会有一些关于厌恶和威胁的评论。是不是人们倾向于在威胁某人或表达厌恶的时候下笔更谨慎一些呢?
随着 Francisco 进一步的挖掘,他发现在很多情况下,恶意评论中包括一遍又一遍复制粘贴的短语。在删除重复的单词,重新分析后,他发现了一组新的相关性。
普通的恶意评论中一般使用温和的词,如母亲、地狱、枪、愚蠢、白痴和闭嘴等,一些恶意的淫秽评论中会使用 f-word。从双标图中也可以知道恶意和侮辱是相似的,至少是有攻击性的,而更严重就是厌恶和威胁。
这三位作者都利用数据可视化取得了很好的效果。
Rhodium 创建一个字符长度直方图和分类类别之间的热图,并发现了一些标签之间高度相关,例如,侮辱评论有 74% 的可能也是淫秽的。
Jagan 绘制了一些词云、热图和交叉表,观察到:
非常恶意的评论可以被归纳为恶意标签
除了少数例外情况,其他分类似乎是恶意评论的一个子集
特征工程
Rhodium 将文本变成小写,手动将句法结构变成事物,并手动清除标点符号。
Jagan 绘制了各种与恶意相关的特征来寻找相关性。他发现,垃圾邮件经常存在恶意。

对于单个单词和单词对,Jagan 和 Rhodium 都使用 TF-IDF 绘制顶部单词。
点评
他们似乎都遵循了所关注领域内的几个最佳实践步骤,包括小写文本、处理结构和清理标点符号。然而,也有认为这些可能是潜在的特征方向,而不仅仅是噪音(例如,Francesco 发现错字和恶意之间的相关性)。
恐怖小说家身份识别
Spooky Author Identification
(恐怖小说家身份识别)竞赛提供了三个恐怖主题作家 Edgar Allan Poe, HP Lovecraft 和 Mary Wollstonecraft Shelley 写的一些文本片段,要求参赛者构建一个能够将作家和特定文本进行匹配的预测模型。
我选择用于分析的 EDA 是 Anisotropic 的
Spooky NLP and Topic Modelling Tutorial
,Bukun 的
Tutorial Detailed Spooky Fun EDA and Modelling
和 Heads or Tails 的
Treemap House of Horror Spooky EDA LDA Features
。
这个数据集的有趣之处在于它的简单性,除了作家之外,文本中几乎没有其他非结构化的数据。因此,所有的 EDA 都只关注用不同的方法来解析和分析语言。
大家首先检查数据集,然后挑出几行来绘制每位作家的故事数目。Bukun 还研究了每位作家文章中的单词长度,而 Anisotropic 绘制了一张整体单词数目的条形图。

Anisotropic 表示,这些词都是常见的词,不仅仅出现在三位作家的恐怖故事和小说里,还有报纸、儿童读物、宗教文本——几乎所有其他的英语文本里都可以找到。因此,我们必须找到一种方法来对数据集进行预处理。首先去掉通常不会带来太多信息的单词 。
他们都构建了词云图来显示出现最频繁的单词:

Heads or Tails 根据 50 个最常见词构建的词云










