transformer
在自然语言处理中的重要地位可见一斑,其优秀的性能和并行性让它在许多场景发光发热。本文将用图文的方式对提出transformer的论文《attention is all your need》的细节进行讲解。
文章图表来自于 http://jalammar.github.io/illustrated-transformer/
文章来源于 https://zhuanlan .zhihu.com/p/81668418
论文发表于NIPS 2017文章主要贡献:文章提出了一种不使用RNN,CNN的新的端到端神经网络模型Transformer,该模型仅使用Attention机制,该模型的优点如下:
1. 相比于RNN,Transformer有更好的并发性,因此训练更快。(得益于self-attention机制的并发性)
2. 相比于CNN,Transformer的句子全局理解能力更好(得益于self-attention的全局性)。
3. Transformer保留了句子每个单词的位置信息。(得益于Positional Encoding)
最后作者用transformer模型在翻译任务中进行实验,获得了SOTA的效果。
2. 文章细节整理:
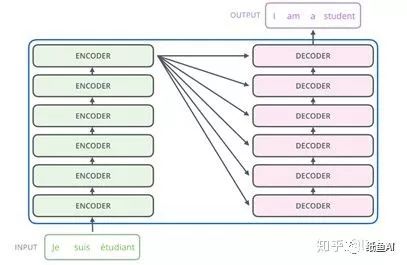
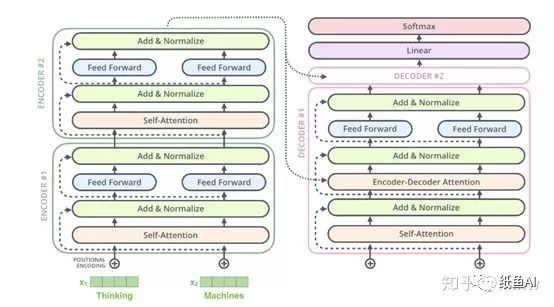
以翻译任务为例,transformer整体结构如下图所示,包括编码部分和解码部分,每一个部分由很多小单元组成。
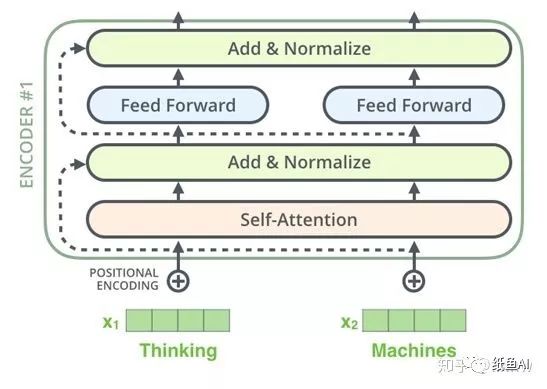
其中编码部分的每一个小单元的主要结构如下图所示,包括了一个self-attention层和一个前向神经网络,一个残差网络,一个layer-normalization以及一个位置编码。
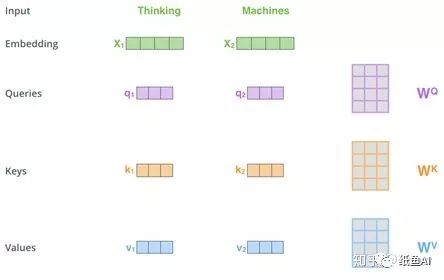
其中Self-Attention部分详细步骤如下:对于每一个输入的词向量,都有三个对应的Q,K,V矩阵,用词向量分别与之做乘法后,每一个单词都可以得到三个对应的向量Queries,Keys和Values。
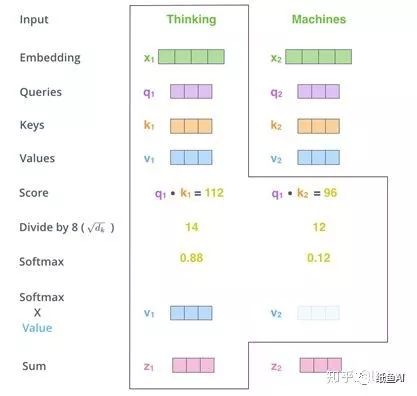
得到三个向量后,对于每一个词向量,都用其对应的Queries向量乘以所有单词的k
向量,从而得到n个Score(n为输入的单词个数)。然后将n个Score分别除以√dk(其中dk为keys向量的维度)得到缩小后的Score。对于n个缩小后的Score,计算它们的softmax,并与该单词的Values向量相乘后,最后对n个上述结果求和就得到了self-attention的输出结果。
当使用矩阵的方式描述上述过程时,如下图所示:
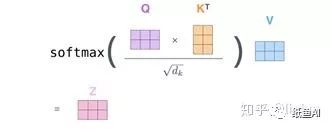
在文章中,对于self-attention,文章提出了multi-head机制,通过多个并行的self-attention更好地捕获句子的信息。8个head的情况如下图所示,对8个得到的z矩阵进行concat后,通过一个Wo矩阵得到最终的z矩阵输出。

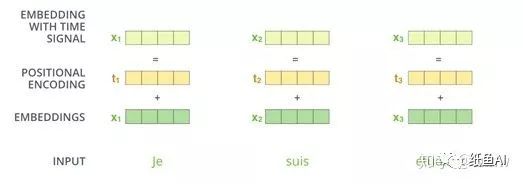
位置编码用于给句子中的单词提供位置信息。文章对每一个词都生成一个位置向量,并用该向量与原词向量相加作为transformer的输入。位置向量的计算公式如下。
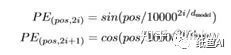
残差网络以及layer-normalize,残差网络的作用在于避免深度带来的梯度消失,layer-normalize的作用是为了防止梯度弥散。
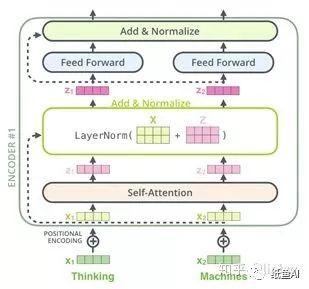
前向神经网络,前馈神经网络的计算公式如下:
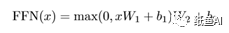
解码器部分,解码器的结构如下图右方所示。其中残差网络,layer-normalize和FFN网络和上文编码器端一致。
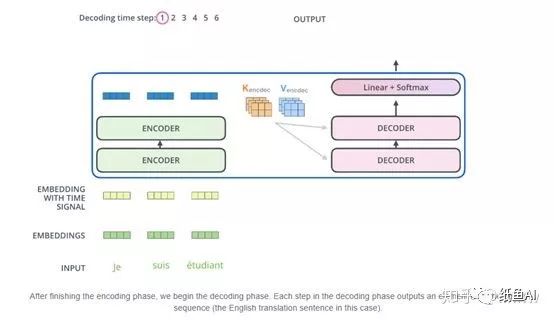
Encoder-Decoder Attention是编码器端与解码器做的Attention,具体计算方式仍与前文一致,区别仅在于对于Encoder不需要向后预测了,所以其不需要queries向量。解码器的第一预测值用一个开始标记进行输入得到输出。
之后的解码过程与上述一致,不过decoder端的self-attention经过masked,对于还未预测出来的单词,不参与self-Attention。
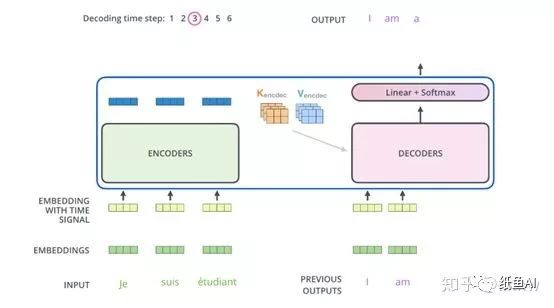
文中使用翻译任务作为示例,所以在decoder的输出端连接了一个全连接层,全连接层的输出维度为词表的大小,接着通过一层softmax得到每个词的概率,损失函数使用的是交叉熵。
本文转载在公众号:纸鱼AI,作者:linhw
推荐阅读
BERT源码分析PART I










