在 神经网络的术语里,一次 epoch = 一个向前传递(得到输出的值)和一个所有训练示例的向后传递(更新权重)。
还记得 tf.Session.run() 方法吗?让我们仔细看看它:
tf.Session.run(fetches, feed_dict=None, options=None, run_metadata=None)
在这篇文章开始的数据流图里,你用到了和操作,但是我们也可以传递一个事情的列表用于运行。在这个神经网络运行中将传递两个事情:损耗计算和优化步骤。
feed_dict 参数是我们为每步运行所输入的数据。为了传递这个数据,我们需要定义tf.placeholders(提供给 feed_dict)
正如 TensorFlow 文档中说的:
“
占位符的存在只作为输入的目标,它不需要初始化,也不包含数据。
” — Source
因此将要像这样定义占位符:

还将要批量分离你的训练数据:
“如果为了能够 输入而使用占位符,可通过使用 tf.placeholder(…, shape=[None, …]) 创建占位符来指定变量批量维度。shape 的 None 元素对应于大小可变的维度。”
— Source
在测试模型时,我们将用更大的批处理来提供字典,这就是为什么需要定义一个可变的批处理维度。
get_batches() 函数为我们提供了批处理大小的文本数。现在我们可以运行模型:
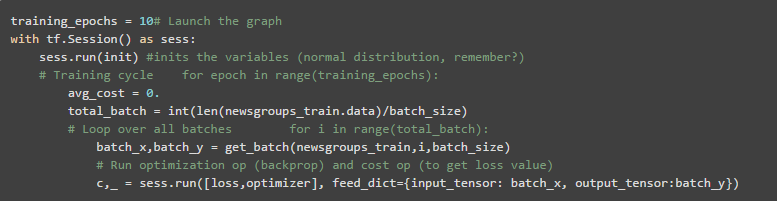
现在有了这个经过训练的模型。为了测试它,还需要创建图元素。
我们将测量模型的准确性,因此需要获取预测值的索引和正确值的索引(因为我们使用的是独热编码),检查它们是否相等,并计算所有测试数据集的平均值:
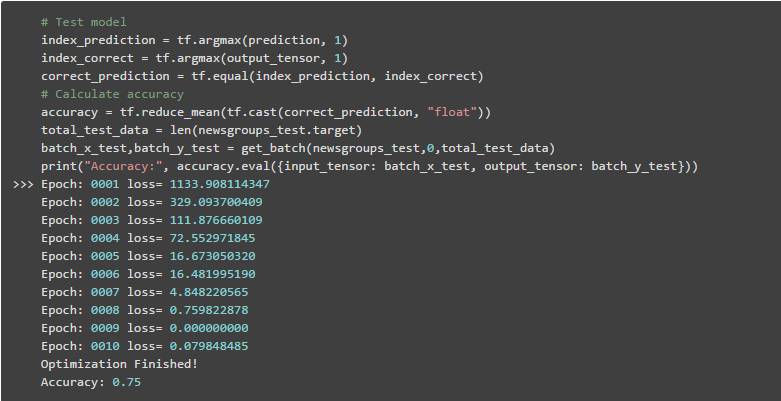
就是这样!你使用神经网络创建了一个模型来将文本分类到不同的类别中。恭喜!
可在 这里 看到包含最终代码的笔记本。
提示:修改我们定义的值,以查看更改如何影响训练时间和模型精度。
还有其他问题或建议?留下你们的评论。谢谢阅读!




