(点击上方蓝字,快速关注我们)
译文:xidui
英文:Sahand Saba
xidui.github.io/2015/10/29/深入理解python3-4中Asyncio库与Node-js的异步IO机制/
如有好文章投稿,请点击 → 这里了解详情
译者前言
如何用yield以及多路复用机制实现一个基于协程的异步事件框架?
现有的组件中yield from是如何工作的,值又是如何被传入yield from表达式的?
在这个yield from之上,是如何在一个线程内实现一个调度机制去调度协程的?
协程中调用协程的调用栈是如何管理的?
gevent和tornado是基于greenlet协程库实现的异步事件框架,greenlet和asyncio在协程实现的原理又有什么区别?
去年稍微深入地了解了下nodejs,啃完了 朴灵 的 《深入浅出Node.js》,自己也稍微看了看nodejs的源码,对于它的异步事件机制还是有一个大致的轮廓的。虽然说让自己写一个类似的机制去实现异步事件比较麻烦,但也并不是完全没有思路。
而对于python中并发我还仅仅停留在使用框架的水平,对于里面是怎么实现的一点想法也没有,出于这部分实现原理的好奇,尝试读了一个晚上asyncio库的源码,感觉还是一头雾水。像这样一个较为成熟的库内容太多了,有好多冗余的模块挡在核心细节之前,确实会对学习有比较大的阻碍。
我也搜了很多国内的关于asyncio以及python中coroutine的文章,但都感觉还没到那个意思,不解渴~在网上找到了这篇文章并阅读之后,我顿时有种醍醐灌顶的感觉,因此决定把这篇长文翻译出来,献给国内同样想了解这部分的朋友们。这篇文章能很好的解答我最前的4个问题,对于第5个问题,还有待去研究greenlet的实现原理。
前言
我花了一个夏天的时间在Node.js的web框架上,那是我第一次全职用Node.js工作。在使用了几周后,有一件事变得很清晰,那就是我们组的工程师包括我都对Node.js中异步事件机制缺乏了解,也不清楚它底层是怎么实现的。我深信,对一个框架使用非常熟练高效,一定是基于对它的实现原理了解非常深刻之上的。所以我决定去深挖它。这份好奇和执着最后不仅停留在Node.js上,同时也延伸到了对其它语言中异步事件机制的实现,尤其是python。我也是拿python来开刀,去学习和实践的。于是我接触到了python 3.4的异步IO库 asyncio,它同时也和我对协程(coroutine)的兴趣不谋而合,可以参考我的那篇关于生成器和协程的博客(译者注:因为asyncio的异步IO是用协程实现的)。这篇博客是为了回答我在研究那篇博客时产生的问题,同时也希望能解答朋友们的一些疑惑。
这篇博客中所有的代码都是基于Python 3.4的。这是因为Python 3.4同时引入了 selectors 和 asyncio 模块。对于Python以前的版本,Twisted, gevent 和 tornado 都提供了类似的功能。
对于本文中刚开始的一些示例代码,出于简单易懂的原因,我并没有引入错误处理和异常的机制。在实际编码中,适当的异常处理是一个非常重要的编码习惯。在本文的最后,我将用几个例子来展示Python 3.4中的 asyncio 库是如何处理异常的。
开始:重温Hello World
我们来写一个程序解决一个简单的问题。本文后面篇幅的多个程序,都是在这题的基础之上稍作改动,来阐述协程的思想。
写一个程序每隔3秒打印“Hello World”,同时等待用户命令行的输入。用户每输入一个自然数n,就计算并打印斐波那契函数的值F(n),之后继续等待下一个输入
有这样一个情况:在用户输入到一半的时候有可能就打印了“Hello World!”,不过这个case并不重要,不考虑它。
对于熟悉Node.js和JavaScript的同学可能很快能写出类似下面的程序:
log_execution_time = require('./utils').log_execution_time;
var fib = function fib(n) {
if (n < 2) return n;
return fib(n - 1) + fib(n - 2);
};
var timed_fib = log_execution_time(fib);
var sayHello = function sayHello() {
console.log(Math.floor((new Date()).getTime() / 1000) + " - Hello world!");
};
var handleInput = function handleInput(data) {
n = parseInt(data.toString());
console.log('fib(' + n + ') = ' + timed_fib(n));
};
process.stdin.on('data', handleInput);
setInterval(sayHello, 3000);
跟你所看到的一样,这题使用Node.js很容易就可以做出来。我们所要做的只是设置一个周期性定时器去输出“Hello World!”,并且在 process.stdin 的 data 事件上注册一个回调函数。非常容易,它就是这么工作了,但是原理如何呢?让我们先来看看Python中是如何做这样的事情的,再来回答这个问题。
在这里也使用了一个 log_execution_time 装饰器来统计斐波那契函数的计算时间。
程序中采用的 斐波那契算法 是故意使用最慢的一种的(指数复杂度)。这是因为这篇文章的主题不是关于斐波那契的(可以参考我的这篇文章(http://sahandsaba.com/five-ways-to-calculate-fibonacci-numbers-with-python-code.html),这是一个关于斐波那契对数复杂度的算法),同时因为比较慢,我可以更容易地展示一些概念。下面是Python的做法,它将使用数倍的时间。
from log_execution_time import log_execution_time
def fib(n):
return fib(n - 1) + fib(n - 2) if n > 1 else n
timed_fib = log_execution_time(fib)
回到最初的问题,我们如何开始去写这样一个程序呢?Python内部并没有类似于 setInterval 或者 setTimeOut 这样的函数。
所以第一个可能的做法就是采用系统层的并发——多线程的方式:
from threading import Thread
from time import sleep
from time import time
from fib import timed_fib
def print_hello():
while True:
print("{} - Hello world!".format(int(time())))
sleep(3)
def read_and_process_input():
while True:
n = int(input())
print('fib({}) = {}'.format(n, timed_fib(n)))
def main():
# Second thread will print the hello message. Starting as a daemon means
# the thread will not prevent the process from exiting.
t = Thread(target=print_hello)
t.daemon = True
t.start()
# Main thread will read and process input
read_and_process_input()
if __name__ == '__main__':
main()
同样也不麻烦。但是它和Node.js版本的做法是否在效率上也是差不多的呢?来做个试验。这个斐波那契计算地比较慢,我们尝试一个较为大的数字就可以看到比较客观的效果:Python中用37,Node.js中用45(JavaScript在数字计算上本身就比Python快一些)。
python3.4 hello_threads.py
1412360472 - Hello world!
37
1412360475 - Hello world!
1412360478 - Hello world!
1412360481 - Hello world!
Executing fib took 8.96 seconds.
fib(37) = 24157817
1412360484 - Hello world!
它花了将近9秒来计算,在计算的同时“Hello World!”的输出并没有被挂起。下面尝试下Node.js:
事件循环和线程
对于线程和事件循环我们需要有一个简单的认识,来理解上面两种解答的区别。先从线程说起,可以把线程理解成指令的序列以及CPU执行的上下文(CPU上下文就是寄存器的值,也就是下一条指令的寄存器)。
一个同步的程序总是在一个线程中运行的,这也是为什么在等待,比如说等待IO或者定时器的时候,整个程序会被阻塞。最简单的挂起操作是 sleep ,它会把当前运行的线程挂起一段给定的时间。一个进程可以有多个线程,同一个进程中的线程共享了进程的一些资源,比如说内存、地址空间、文件描述符等。
线程是由操作系统的调度器来调度的,调度器统一负责管理调度进程中的线程(当然也包括不同进程中的线程,不过对于这部分我将不作过多描述,因为它超过了本文的范畴。),它来决定什么时候该把当前的线程挂起,并把CPU的控制权交给另一个线程来处理。这称为上下文切换,包括对于当前线程上下文的保存、对目标线程上下文的加载。上下文切换会对性能造成一定的影响,因为它本身也需要CPU周期来执行。
操作系统切换线程有很多种原因:
另一个优先级更高的线程需要马上被执行(比如处理硬件中断的代码)
线程自己想要被挂起一段时间(比如 sleep)
线程已经用完了自己时间片,这个时候线程就不得不再次进入队列,供调度器调度
回到我们之前的代码,Python的解答是多线程的。这也解释了两个任务可以并行的原因,也就是在计算斐波那契这样的CPU密集型任务的时候,没有把其它的线程阻塞住。
再来看Node.js的解答,从计算斐波那契把定时线程阻塞住可以看出它是单线程的,这也是Node.js实现的方式。从操作系统的角度,你的Node.js程序是在单线程上运行的(事实上,根据操作系统的不同,libuv 库在处理一些IO事件的时候可能会使用线程池的方式,但这并不影响你的JavaScript代码是跑在单线程上的事实)。
基于一些原因,你可能会考虑避免多线程的方式:
线程在计算和资源消耗的角度是较为昂贵的
线程并发所带来的问题,比如因为共享的内存空间而带来的死锁和竞态条件。这些又会导致更加复杂的代码,在编写代码的时候需要时不时地注意一些线程安全的问题
当然以上这些都是相对的,线程也是有线程的好处的。但讨论那些又与本文的主题偏离了,所以就此打住。
来尝试一下不使用多线程的方式处理最初的问题。为了做到这个,我们需要模仿一下Node.js是怎么做的:事件循环。我们需要一种方式去poll(译者注:没想到对这个词的比较合适的翻译,轮训?不合适。) stdin 看看它是否已经准备好输入了。基于不同的操作系统,有很多不同的系统调用,比如 poll, select, kqueue 等。在Python 3.4中,select 模块在以上这些系统调用之上提供了一层封装,所以你可以在不同的操作系统上很放心地使用而不用担心跨平台的问题。
有了这样一个polling的机制,事件循环的实现就很简单了:每个循环去看看 stdin 是否准备好,如果已经准备好了就尝试去读取。之后去判断上次输出“Hello world!”是否3秒种已过,如果是那就再输出一遍。
下面是代码:
import selectors
import sys
from time import time
from fib import timed_fib
def process_input(stream):
text = stream.readline()
n = int(text.strip())
print('fib({}) = {}'.format(n, timed_fib(n)))
def print_hello():
print("{} - Hello world!".format(int(time())))
def main():
selector = selectors.DefaultSelector()
# Register the selector to poll for "read" readiness on stdin
selector.register(sys.stdin, selectors.EVENT_READ)
last_hello = 0 # Setting to 0 means the timer will start right away
while True:
# Wait at most 100 milliseconds for input to be available
for event, mask in selector.select(0.1):
process_input(event.fileobj)
if time() - last_hello > 3:
last_hello = time()
print_hello()
if __name__ == '__main__':
main()
然后输出:
$ python3.4 hello_eventloop.py
1412376429 - Hello world!
1412376432 - Hello world!
1412376435 - Hello world!
37
Executing fib took 9.7 seconds.
fib(37) = 24157817
1412376447 - Hello world!
1412376450 - Hello world!
跟预计的一样,因为使用了单线程,该程序和Node.js的程序一样,计算斐波那契的时候阻塞了“Hello World!”输出。
Nice!但是这个解答还是有点hard code的感觉。下一部分,我们将使用两种方式对这个event loop的代码作一些优化,让它功能更加强大、更容易编码,分别是 回调 和 协程。
事件循环——回调
对于上面的事件循环的写法一个比较好的抽象是加入事件的handler。这个用回调的方式很容易实现。对于每一种事件的类型(这个例子中只有两种,分别是stdin的事件和定时器事件),允许用户添加任意数量的事件处理函数。代码不难,就直接贴出来了。这里有一点比较巧妙的地方是使用了 bisect.insort 来帮助处理时间的事件。算法描述如下:维护一个按时间排序的事件列表,最近需要运行的定时器在最前面。这样的话每次只需要从头检查是否有超时的事件并执行它们。bisect.insort 使得维护这个列表更加容易,它会帮你在合适的位置插入新的定时器事件回调函数。诚然,有多种其它的方式实现这样的列表,只是我采用了这种而已。
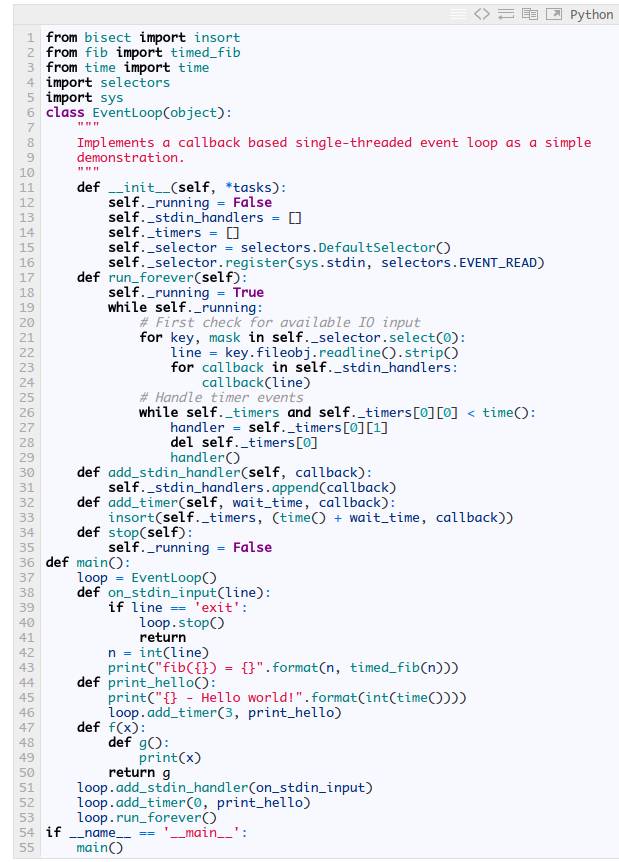
代码很简单,实际上Node.js底层也是采用这种方式实现的。然而在更复杂的应用中,以这种方式来编写异步代码,尤其是又加入了异常处理机制,很快代码就会变成所谓的回调地狱(callback hell )。引用 Guido van Rossum 关于回调方式的一段话:
要以回调的方式编写可读的代码,你需要异于常人的编码习惯。如果你不相信,去看看JavaScript的代码就知道了——Guido van Rossum
写异步回调代码还有其它的方式,比如 promise 和 coroutine(协程) 。我最喜欢的方式(协程非常酷,我的博客中这篇文章就是关于它的)就是采用协程的方式。下一部分我们将展示使用协程封装任务来实现事件循环的。
事件循环——协程
协程 也是一个函数,它在返回的同时,还可以保存返回前的运行上下文(本地变量,以及下一条指令),需要的时候可以重新加载上下文从上次离开的下一条命令继续执行。这种方式的 return 一般叫做 yielding。在这篇文章(http://sahandsaba.com/combinatorial-generation-using-coroutines-in-python.html)中我介绍了更多关于协程以及在Python中的如何使用的内容。在我们的例子中使用之前,我将对协程做一个更简单的介绍:
Python中 yield 是一个关键词,它可以用来创建协程。
当调用 yield value 的时候,这个 value 就被返回出去了,CPU控制权就交给了协程的调用方。调用 yield 之后,如果想要重新返回协程,需要调用Python中内置的 next 方法。
当调用 y = yield x 的时候,x被返回给调用方。要继续返回协程上下文,调用方需要再执行协程的 send 方法。在这个列子中,给send方法的参数会被传入协程作为这个表达式的值(本例中,这个值会被y接收到)。
这意味着我们可以用协程来写异步代码,当程序等待异步操作的时候,只需要使用yield把控制权交出去就行了,当异步操作完成了再进入协程继续执行。这种方式的代码看起来像同步的方式编写的,非常流畅。下面是一个采用yield计算斐波那契的简单例子:
def read_input():
while True:
line = yield sys.stdin
n = int(line)
print("fib({}) = {}".format(n, timed_fib(n)))
仅仅这样还不够,我们需要一个能处理协程的事件循环。在下面的代码中,我们维护了一个列表,列表里面保存了,事件循环要运行的 task。当输入事件或者定时器事件发生(或者是其它事件),有一些协程需要继续执行(有可能也要往协程中传入一些值)。每一个 task 里面都有一个 stack 变量保存了协程的调用栈,栈里面的每一个协程都依赖着后一个协程的完成。这个基于PEP 342中 “Trampoline”的例子实现的。代码中我也使用了 functools.partial,对应于JavaScript中的 Function.prototype.bind,即把参数绑定(curry)在函数上,调用的时候不需要再传参了。
下面是代码:
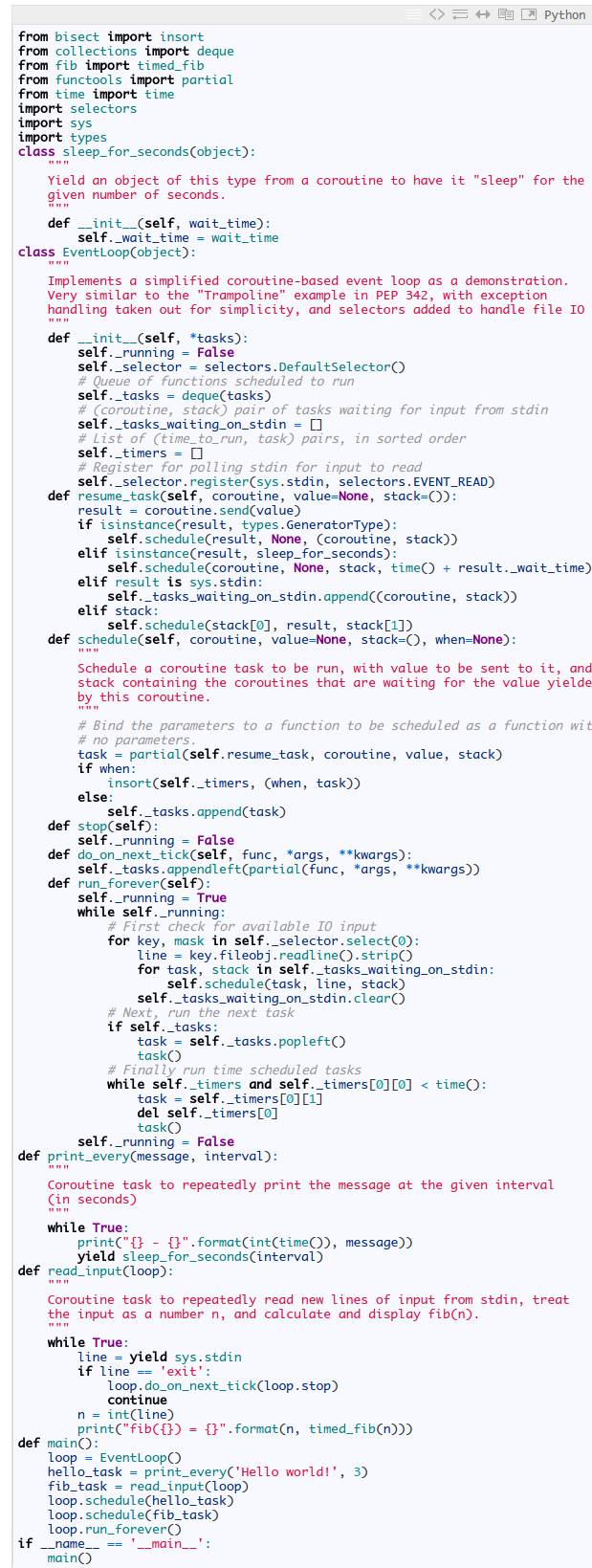
代码中我们也实现了一个 do_on_next_tick 的函数,可以在下次事件循环的时候注册想要执行的函数,这个跟Node.js中的process.nextTick多少有点像。我使用它来实现了一个简单的 exit 特性(即便我可以直接调用 loop.stop())。
我们也可以使用协程来重构斐波那契算法代替原有的递归方式。这么做的好处在于,协程间可以并发运行,包括输出“Hello World!”的协程。
斐波那契算法重构如下:
from event_loop_coroutine import EventLoop
from event_loop_coroutine import print_every
import sys
def fib(n):
if n <= 1:
yield n
else:
a = yield fib(n - 1)
b = yield fib(n - 2)
yield a + b
def read_input(loop):
while True:
line = yield sys.stdin
n = int(line)
fib_n = yield fib(n)
print("fib({}) = {}".format(n, fib_n))
def main():
loop = EventLoop()
hello_task = print_every('Hello world!', 3)
fib_task = read_input(loop)
loop.schedule(hello_task)
loop.schedule(fib_task)
loop.run_forever()
if __name__ == '__main__':
main()
程序的输出:
$ python3.4 fib_coroutine.py
1412727829 - Hello world!
1412727832 - Hello world!
28
1412727835 - Hello world!
1412727838 - Hello world!
fib(28) = 317811
1412727841 - Hello world!
1412727844 - Hello world!
不重复造车轮
前面两个部分,我们分别使用了回调函数和协程实现了事件循环来写异步的逻辑,对于实践学习来说确实是一种不错的方式,但是Python中已经有了非常成熟的库提供事件循环。Python3.4中的 asyncio 模块提供了事件循环和协程来处理IO操作、网络操作等。在看更多有趣的例子前,针对上面的代码我们用 asyncio 模块来重构一下:
import asyncio
import sys
from time import time
from fib import timed_fib
def process_input():
text = sys.stdin.readline()
n = int(text.strip())
print('fib({}) = {}'.format(n, timed_fib(n)))
@asyncio.coroutine
def print_hello():
while True:
print("{} - Hello world!".format(int(time())))
yield from asyncio.sleep(3)
def main():
loop = asyncio.get_event_loop()
loop.add_reader(sys.stdin, process_input)
loop.run_until_complete(print_hello())
if __name__ == '__main__':
main()
上面的代码中 @asyncio.coroutine 作为装饰器来装饰协程,yield from 用来从其它协程中接收参数。
异常处理
Python中的协程允许异常在协程调用栈中传递,在协程挂起的地方捕获到异常状态。我们来看一个简单的例子:
def coroutine():
print("Starting")
try:
yield "Let's pause until continued."
print("Continuing")
except Exception as e:
yield "Got an exception: " + str(e)
def main():
c = coroutine()
next(c) # Execute until the first yield
# Now throw an exception at the point where the coroutine has paused
value = c.throw(Exception("Have an exceptional day!"))
print(value)
if __name__ == '__main__':
main()
输出如下:
Starting
Got an exception: Have an exceptional day!
这个特性使得用异常处理问题有一个统一的处理方式,不管是在同步还是异步的代码中,因为事件循环可以合理地捕获以及传递异常。我们来看一个事件循环和多层调用协程的例子:
import asyncio
@asyncio.coroutine
def A():
raise Exception("Something went wrong in A!")
@asyncio.coroutine
def B():
a = yield from A()
yield a + 1
@asyncio.coroutine
def C():
try:
b = yield from B()
print(b)
except Exception as e:
print("C got exception:", e)
def main():
loop = asyncio.get_event_loop()
loop.run_until_complete(C())
if __name__ == '__main__':
main()
输出:
C got exception: Something went wrong in A!
在上面的例子中,协程C依赖B的结果,B又依赖A的结果,A最后抛出了一个异常。最后这个异常一直被传递到了C,然后被捕获输出。这个特性与同步的代码的方式基本一致,并不用手动在B中捕获、再抛出!
当然,这个例子非常理论化,没有任何创意。让我们来看一个更像生产环境中的例子:我们使用 ipify 写一个程序异步地获取本机的ip地址。因为 asyncio 库并没有HTTP客户端,我们不得不在TCP层手动写一个HTTP请求,并且解析返回信息。这并不难,因为API的内容都以及胸有成竹了(仅仅作为例子,不是产品代码),说干就干。实际应用中,使用 aiohttp 模块是一个更好的选择。下面是实现代码:
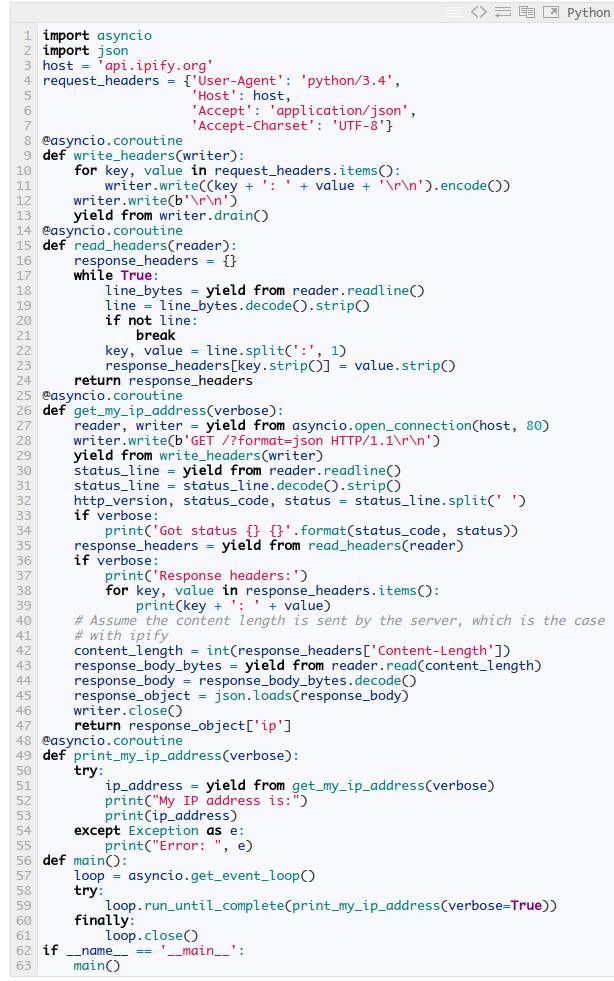
是不是跟同步代码看着很像?:没有回调函数,没有复杂的错误处理逻辑,非常简单、可读性非常高的代码。
下面是程序的输出,没有任何错误:
$ python3.4 ipify.py
Got status 200 OK
Response headers:
Content-Length: 21
Server: Cowboy
Connection: keep-alive
Via: 1.1 vegur
Content-Type: application/json
Date: Fri, 10 Oct 2014 03:46:31 GMT
My IP address is:
#
使用协程来处理异步逻辑的主要优势在我看来就是:错误处理与同步代码几乎一致。比如在上面的代码中,协程调用链中任意一环出错,并不会导致什么问题,错误与同步代码一样被捕获,然后处理。
依赖多个互不相关协程的返回结果
在上面的例子中,我们写的程序是顺序执行的,虽然使用了协程,但互不相关的协程并没有完美地并发。也就是说,协程中的每一行代码都依赖于前一行代码的执行完毕。有时候我们需要一些互不相关的协程并发执行、等待它们的完成结果,并不在意它们的执行顺序。比如,使用网络爬虫的时候,我们会给页面上的所有外链发送请求,并把返回结果放入处理队列中。
协程可以让我们用同步的方式编写异步的代码,但是对于处理互不相关的任务不论是完成后马上处理抑或是最后统一处理,回调的方式看上去是最好的选择。但是,Python 3.4的 asyncio 模块同时也提供了以上两种情形的支持。分别是函数 asyncio.as_completed 和 asyncio.gather 。
我们来一个例子,例子中需要同时加载3个URL。采用两种方式
使用 asyncio.as_completed 一旦请求完成就处理
使用 asyncio.gather 等待所有都完成一起处理
与其加载真的URL地址,我们采用一个更简单的方式,让协程挂起随机长度的时间。
下面是代码:
import asyncio
import random
@asyncio.coroutine
def get_url(url):
wait_time = random.randint(1, 4)
yield from asyncio.sleep(wait_time)
print('Done: URL {} took {}s to get!'.format(url, wait_time))
return url, wait_time
@asyncio.coroutine
def process_as_results_come_in():
coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']]
for coroutine in asyncio.as_completed(coroutines):
url, wait_time = yield from coroutine
print('Coroutine for {} is done'.format(url))
@asyncio.coroutine
def process_once_everything_ready():
coroutines = [get_url(url) for url in ['URL1', 'URL2', 'URL3']]
results = yield from asyncio.gather(*coroutines)
print(results)
def main():
loop = asyncio.get_event_loop()
print("First, process results as they come in:")
loop.run_until_complete(process_as_results_come_in())
print("\nNow, process results once they are all ready:")
loop.run_until_complete(process_once_everything_ready())
if __name__ == '__main__':
main()
输出如下:
$ python3.4 gather.py
First, process results as they come in:
Done: URL URL2 took 2s to get!
Coroutine for URL2 is done
Done: URL URL3 took 3s to get!
Coroutine for URL3 is done
Done: URL URL1 took 4s to get!
Coroutine for URL1 is done
Now, process results once they are all ready:
Done: URL URL1 took 1s to get!
Done: URL URL2 took 3s to get!
Done: URL URL3 took 4s to get!
[('URL1', 1), ('URL2', 3), ('URL3', 4)]
更加深入
有很多内容本篇文章并没有涉及到,比如 Futures 和 libuv。这个视频(http://www.youtube.com/watch?v=1coLC-MUCJc) (需要翻墙)是介绍Python中的异步IO的。本篇文章中也有可能有很多我遗漏的内容,欢迎随时在评论中给我补充。
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能











