
大数据文摘作品,转载要求见文末
作者 | 钱天培
5月19日,Teradata天睿公司在上海举办主题为“数据分析 卓越业务”的2017大数据峰会”。本届峰会围绕数据分析和业务咨询在各个行业的应用,尤其探讨了数据分析在人工智能、机器学习等前沿领域的应用和趋势。
天睿公司
首席技术官、
全球数据仓库技术的一流专家
Stephen Brobst在会上做了演讲,
Stephen Brobst主要谈到了机器学习和人工智能在过去的20年间是如何改变商业决策模式的,以及如何更好地在这次浪潮中获益。他指出,
运营智能化正逐渐成为了一种商业决策的新模式。

图:Teradata天睿公司首席技术官宝立明(Stephen Brobst)
从上世纪90年代起,随着商业运营数据井喷式的产生,以及数据存储技术的变革,运营智能化逐渐成为了一种商业决策的新模式。然而直到2010年,大多数公司对于越来越多且杂乱无章的数据一筹莫展。大部分公司浪费了90%的时间来搞清楚他们那些一团乱麻的数据到底代表了什么,而忽略了决策这一最终环节。而在这个时间节点,人工智能和机器学习带来了突破性的解决方案。

人工智能的到来使得这些杂乱无章的处理变得自动化。人类不必再需要手动查找各种变量,而把这一过程交给机器,实现变量自动化选择。
机器学习的介入并不是要推出什么新的预测、算法,它更多的是提出了一种新的概念——将从数据中学习从而获取信息的过程自动化。得益于此,现在我们可以将90%的时间用在决策这一最终目标上。
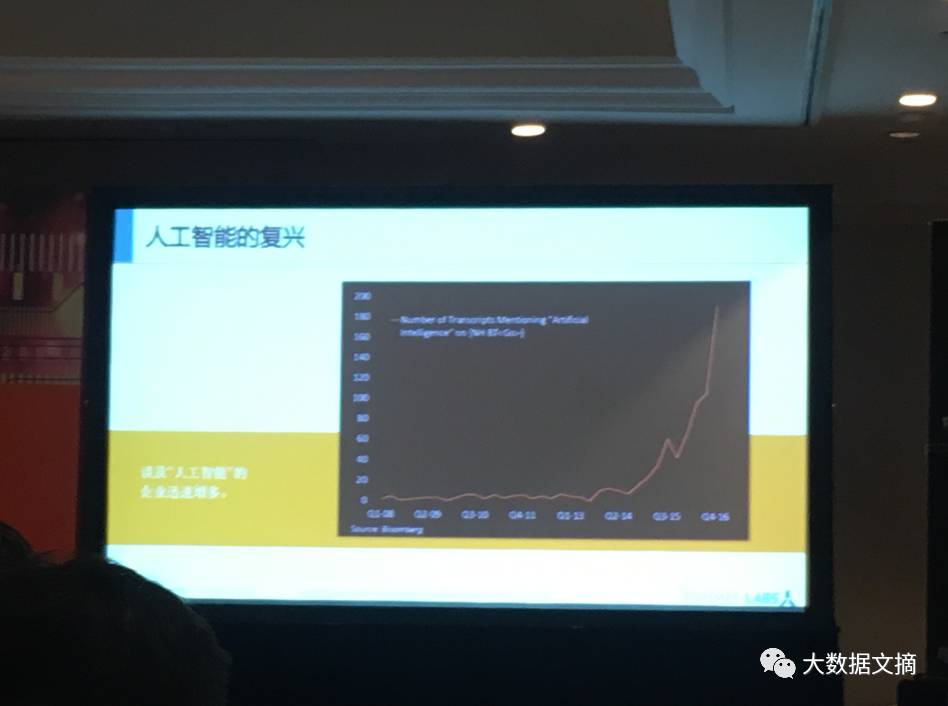
Stephen用图表的形式论证,人工智能在北美地区的应用呈指数级上升。几乎所有公司都开始强调用人工智能做决策。

人工智能带来了数据处理的自动化,而这种自动化有95%是依靠线性回归实现的。

关于对需求的预测,包括预测一些会发生的欺诈情况,有很多变量,还有数据和预测的结果之间的非线性的回归,这就叫做人工智能,能够远远超出传统的一些机器学习的范畴。
不同于线性模型,深度学习使用了一种多层次的神经网络的技术。这是一种非线性、非关系型数据库。深度学习淡化了领域知识的必要性,
使得人们在只具备些微领域知识甚至不具备领域知识的情况下也能实现数据分析的自动化。
我们来看一下深度学习是跟机器学习有什么不一样。在把人工智能转换成更加狭隘的定义就是深度学习。深度学习最基本来说,叫做一种多层次的神经网络的技术,以便来创建在中间的数据的表示功能来解决问题。这些是属于非线性的、非关系型的数据库。这些领域有很多繁杂的数据,或者是缺失的数据,或者是高维度的数据,都可以通过深度学习解决,而那些线性的模型在这个集群里是难以解决问题。
这些数据可以来自于各种不同的数据源,把这些数据汇集在一起,让我们的神经网络技术来自我组织、预测结果,这就对维度的知识、来自于数据科学家的支持的要求就少了一些。跟以前的科技相比,我们比较容忍丢失数据或者繁杂的数据,比如说这些犯罪者要去进行欺诈,因为被掩盖所以他们的数据很难找到。我们的神经网络能够更加有效地找出它的模式,并且能检测这些欺诈。这叫做多层次的神经网络的技术,从理论上说,它已经存在差不多有超过50年的时间了。
以前这种技术都是用一种学术论文里边描述的,并没有在现实当中真正被使用。这里边的原因是什么呢?因为这些技巧太需要大量的计算密集型的应用,很难有及时的预测,而且计算时间很长。这是需要大量的计算密集型的技术和能力,但是计算机的能力最近几年发展非常快,有能力充分地利用特殊的一些处理工艺,能够在过去几年让我们把深度学习从学术理论变成了一种现实当中可行的现实。其中一项关键技术是GPU的技术,就是图形处理技术。GPU也已经存在很长时间了,在我们在线游戏上都在用。比如孩子们在玩一些大量的怪兽、机器等游戏,还有魔兽等游戏,GPU能够提供这样一种图形和能力,有这样的用户进行游戏体验。
GPU的技术能够搞清楚如何来掌握这种技术。
作为一个产业来讲,能够在神经网络上
执行一些学习的算法
。
以前的算法在计算上是被限制了,现在我们能够来执行更大范畴的能力,能够用更高效率的技术。
GPU技术企业的股价在过去几年已经爆棚了,并不是因为游戏爆棚、增长,而是计算机科学家们搞清楚了如何来映射人工智能、深度学习放在GPU的技术里边。Teradata拥有GPU技术高级开发实验室,以及合作伙伴有亚马逊AWS,他们有GPU的技术,以及一些instances配置的一些情况。Teradata技术有充分利用这样的并行处理能力,能够来开发多层的神经网络的技术,能够来推动这样一些预测,能够来覆盖很多行业。
Teradata
充分地利用这些算法的发展,这些实验室能够利用GPU的开源技术,能够结合我们实时的流处理的能力。
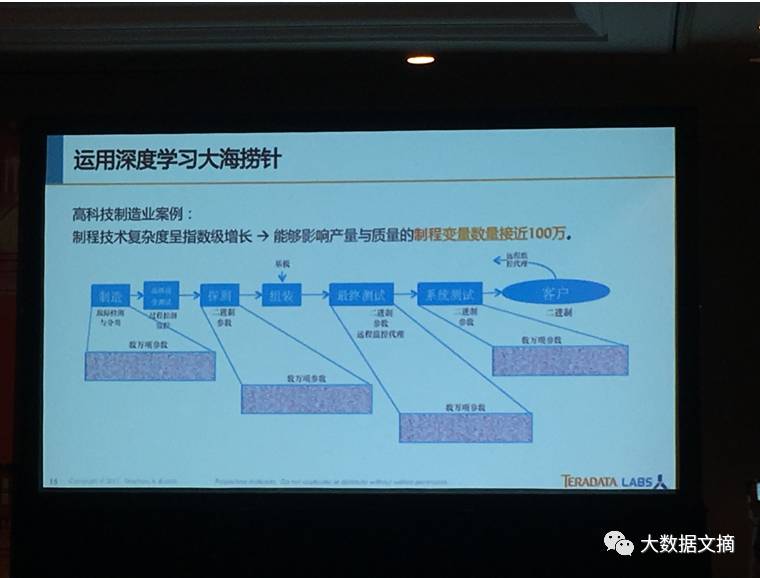
这有一个来自于一个美国的高科技制造公司的例子,他们有100万个不同的变量,而且这些就是计算要用的,来看一下有没有机会能够改变。传统的线性的模型不能够应对这么多数据,而且是没有线性关系的数据。有了深度学习之后,以及我们所说的多层神经网络的深度学习,他们就可以实现很好的改进,能够看一下机会在什么地方进行预测。这样的话,在他们的制造流程中就能做得更好。
那么这个预测的核心是什么?就是开源的软件。特别是在这个领域中的发展,人工智能的发展最重要的东西是从开源社区来的。我们可以看一下加州伯克利大学,还有Google的开源,还有Facebook的开源,他们这种开源的项目是可以给客户带来价值的。但是,你用了开源软件包进行部署,这对于数据科学家来讲需要很多专业知识。这些工具包可以到网站上去获取到,包括有开源的神经元的网络,这样你能够感觉得到用这些神经元网络的预测结果的能力,但是做软件的时候是很难的。
这个机器学习问题有100万个不同的变量,远超出传统的线性的模型的处理能力。而深度学习则能有效地进行数据分析,从而给他们的制造流程提供重要的优化建议。
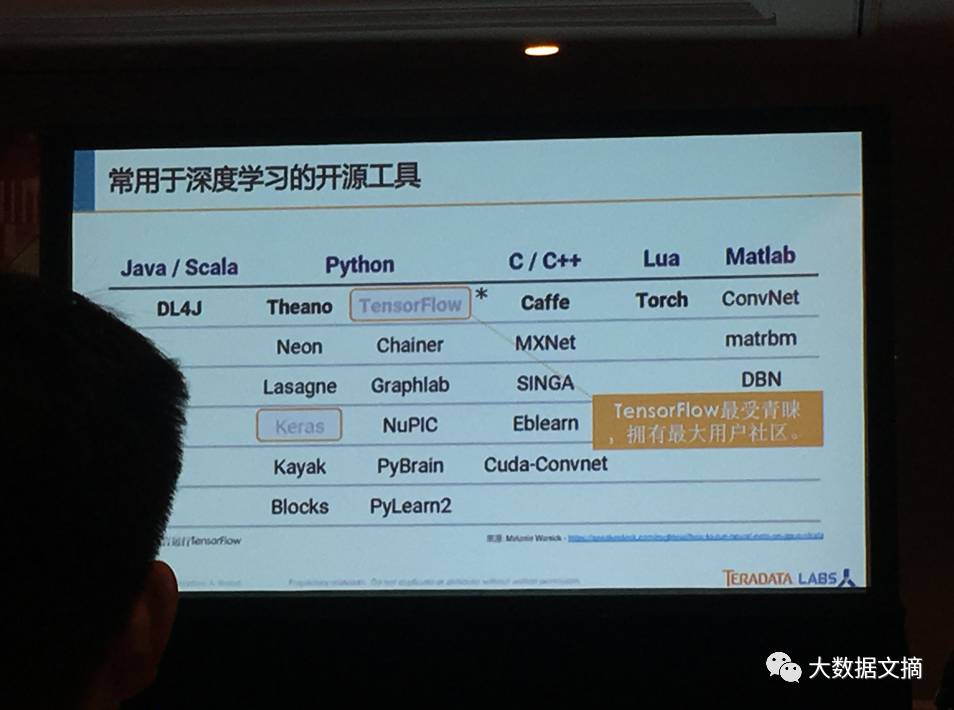
开源社区对人工智能发展所作出了重要贡献。如加州伯克利大学的开源,Google的开源,Facebook的开源等。这些开源技术能够为客户带来巨大的商业价值。然而,这些开源技术的实际应用对许多非数据科学家来说可不是那么简单的。
Teradata的人工智能专家团队通过对开源部署的关于及研究开发出了ThinkDeep这有框架,从而为非数据科学家建立了使用深度学习的生态系统。ThinkDeep旨在将深度学习和机器学习的框架带入实际中去,从而落实为企业的优秀分析能力。
在演讲以及会后记者问答环节中,Stephen为大数据文摘记者介绍了人工智能在金融领域的应用案例。
Stephen:
很重要的一个应用是反
欺诈,有了深度学习以后,它可以很大程度上降低欺诈的情况,使欺诈行为发生得越来越少,尤其是考虑到罪犯是变换不同的欺诈手法,因此学习的速度应该是特别特别快才行。
还有金融公司也想知道客户花钱的情况,比如说花钱都在什么地方、干了什么。如果他是刷信用卡,就很容易知道是在餐馆、机场还是什么地方花的,因为都有一个码,代表哪个是餐馆、哪个是什么。
还有一部分美国人爱写支票,比如他在哪花了300美元,作为金融机构来讲,不知道他花钱买了什么东西。要是识别这个人在支票上签字,最后谁签收的支票的时候,他可能能通过这个了解到这个客户到底是在什么地方花了这笔钱。但是因为人写字的时候写得乱七八糟,有的写得不清楚,所以识别起来还是挺不容易的。现在有了深度学习,深度学习来识别手写字体,到底是在什么地方、谁写的什么的时候,比人要做得更好。










