0x00前言
早在前段时间就尝试写过爬Google的了。当时由于解决不了验证码就删了,当然这次也没解决。验证码不能绕过,只能避免,减少遇见

0x001过程
爬虫我追求,快、稳。但是由于Google这恶心的验证码机制,导致我不得不放弃这个想法。转而话费大量时间来解决频频碰到验证码的问题
写法只有请求,不换user-agent头的,加上多进程或多线程调用。一次就封IP了
import requests
rqt=requests.get(url='https://www.google.com/search?q=xxx&start=1',headers={'user-agent':'Google Splider'},timeout=3)
后面参考了几篇文章和一个项目:
对于 Python 抓取 Google 搜索结果的一些了解:
https://juejin.im/post/5c2c6bbee51d450d5a01d70a
Google_search
https://github.com/MarioVilas/googlesearch
看了这两个操作之后,发现都是用了同一操作
随机User-Agent头
随机使用Google的搜索子域
收集的User-agent头
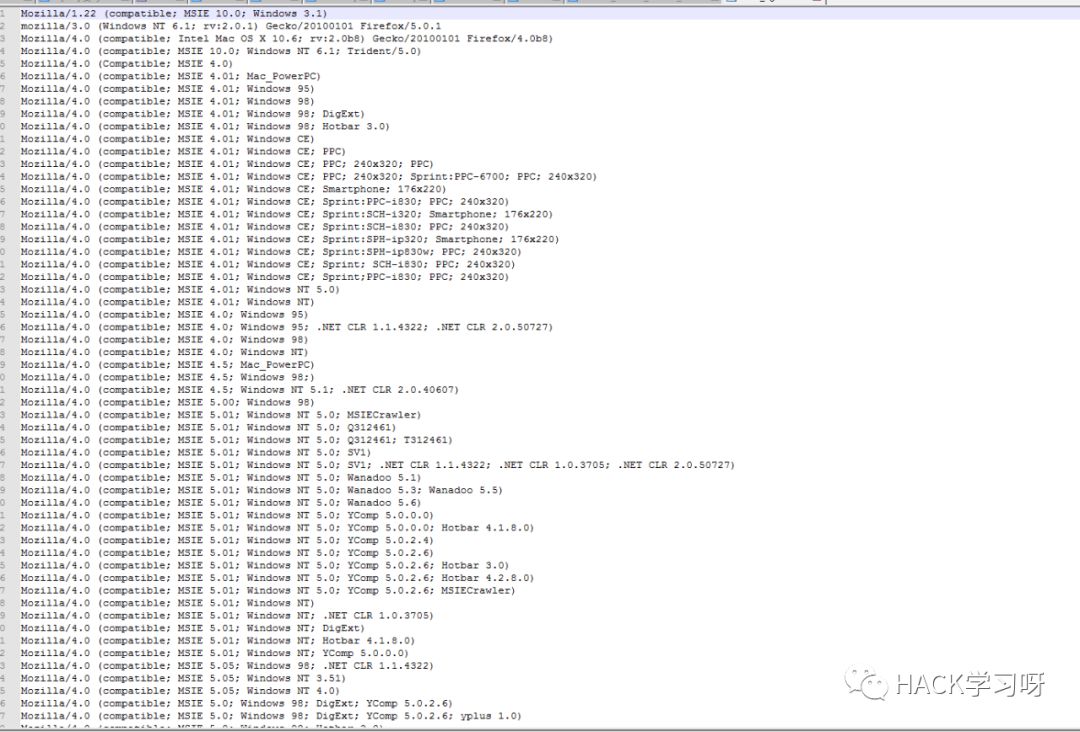
实现这两种随机很容易,只需全部放入两个数组。使用random.choice()随机抽取即可
def read():
dk=open('user_agents.txt','r',encoding='utf-8')
for r in dk.readlines():
data="".join(r.split('\n'))
yield data
def reads():
dk=open('domain.txt','r',encoding='utf-8')
for r in dk.readlines():
data="".join(r.split('\n'))
yield data
def fenpei(proxy,search,page,sleep):
user_agents=[]
google_searchs=[]
for ua in read():
user_agents.append(ua)
for domain in reads():
google_searchs.append(domain)
虽然实现随机了,但是还是很脆弱。还是经不起Google那个狗贼般的验证码的摧残,在给其加上一个延时
import random
import requests
import time
def read():
dk=open('user_agents.txt','r',encoding='utf-8')
for r in dk.readlines():
data="".join(r.split('\n'))
yield data
def reads():
dk=open('domain.txt','r',encoding='utf-8')
for r in dk.readlines():
data="".join(r.split('\n'))
yield data
def fenpei(proxy,search,page,sleep):
user_agents=[]
google_searchs=[]
for ua in read():
user_agents.append(ua)
for domain in





