作者:董超
来源:腾云阁
上一讲我们介绍了一下线性回归如何通过TensorFlow训练,这一讲我们介绍下逻辑回归模型,并通过该模型进行MNIST手写识别的训练
在本文的开始前,强烈推荐两个深度学习相关的视频集
1.台湾李宏毅教授的ML 2016,清晰明了,很多晦涩的原理能让你看了也能明白:https://www.youtube.com/watch?v=fegAeph9UaA&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49 2.周莫烦的TensorFlow教程,同样清晰明了:https://www.youtube.com/watch?v=RSRkp8VAavQ&index=1&list=PLXO45tsB95cKI5AIlf5TxxFPzb-0zeVZ8
0x00 概念
什么是逻辑回归
线性回归通常用于对于连续值预测,比如根据房价走势,给个房子的面积预测该房子以后的房价等。
然而,有时我们需要对事物分类(classify)而不是去预测一个具体的数值,例如给定一张含有数字(0-9 十个数字中的一个)的图片,我们需要将其分类为 0,1,2,3,4,5,6,7,8,9 十类;或者,我们需要将一首歌曲进行归类,如归类为流行,摇滚,说唱等。集合 [0,1,2,…,9]、[流行,摇滚,说唱,等等] 中的每一个元素都可以表示一个类;或者给一张照片判断该张图片是猫还是狗集合[0,1]、[猫,狗]。 一句话说概括,逻辑回归就是多分类问题。 0-9数字的手写识别也是输入一张图片,然后我们将其分类到0-9,所以也是可以运用逻辑回归滴~
逻辑回归模型构建
在解决问题之前,我们首先要建立个模型才能进一步解决问题,不过非常幸运的是线性回归中的许多概念与逻辑回归有相似之处,我们仍然可以使用y = W * x + b来解决逻辑回归问题,让我们看下线性回归和逻辑回归之间有什么差别: 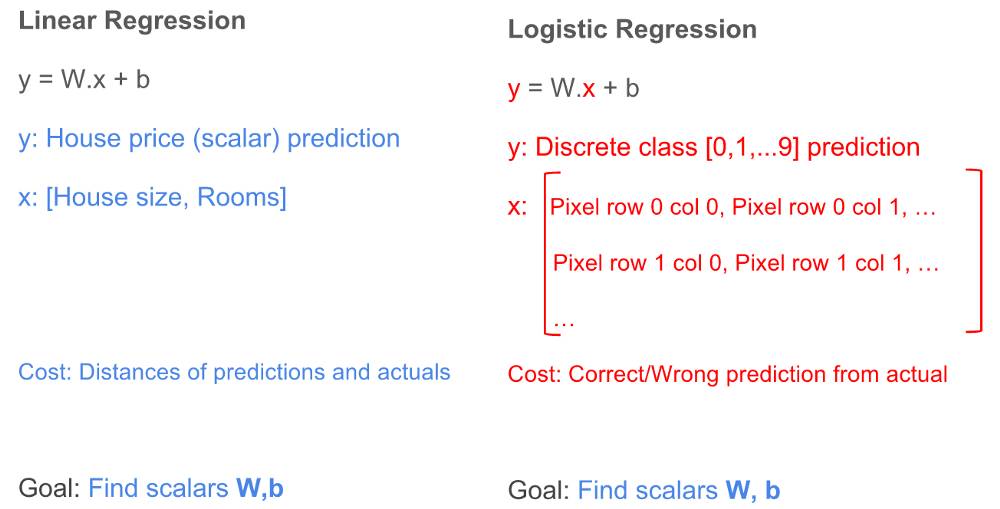
区别: 1.结果(y):对于线性回归,结果是一个标量值(可以是任意一个符合实际的数值),例如 50000,23.98 等;对于逻辑回归,结果是一个整数(表示不同类的整数,是离散的),例如 0,1,2,… 9。 2.特征(x):对于线性回归,特征都表示为一个列向量;对于涉及二维图像的逻辑回归,特征是一个二维矩阵,矩阵的每个元素表示图像的像素值。 3.损失函数:对于线性回归,成本函数是表示每个预测值与其预期结果之间的聚合差异的某些函数;对于逻辑回归,是计算每次预测的正确或错误的某些函数。
相似: 1.训练:都是去学习W和b的权值 2.预测:都是通过学习到的W和b进行预测
模型修改
输入X修改 
一般我们输入的图像是二维的数组,为了能够使用线性回归的方程我们需要做些修改,我们将输入的图像从二维压缩成一维,其实方法也很简单就如上图一样,将第2,3,4…行依次放到第1行后面即可。
输出Y的修改
我们在执行预测的时候是没法打包票说,预测的是什么东西的,我们一般会输出个概率数组,来表示我们要预测的东西属于某一类的概率 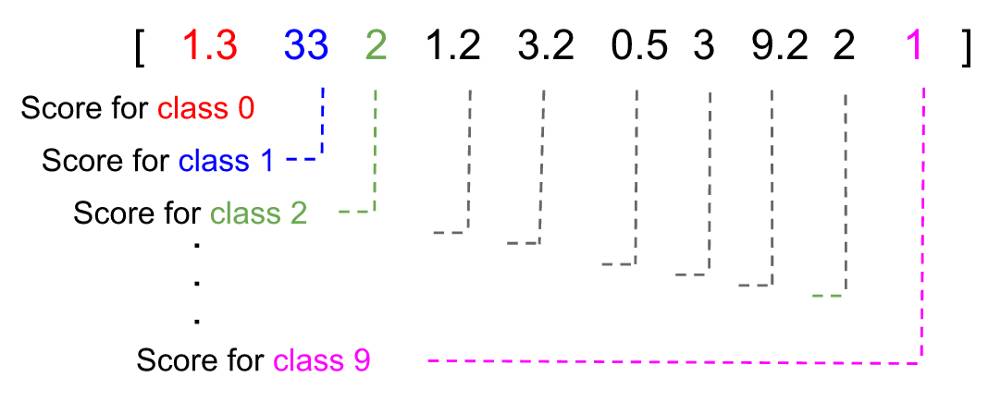 如上图,我们给出每一个类别的得分情况(大部分情况得分是概率),从上图我们亦可以看出,预测的结果是class 1,因为他的得分最高。
如上图,我们给出每一个类别的得分情况(大部分情况得分是概率),从上图我们亦可以看出,预测的结果是class 1,因为他的得分最高。
0x01 实现
我们拿MNIST手写识别来讲述下如何实现逻辑回归,MNIST手写识别的例子也算是机器学习祖传例子了,大家基本上都是拿这个例子入门的。
当然照惯例先上代码
#coding=utf-8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(64)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
然后我们详细讲述每一行代码的作用,一些上一讲已经介绍的概念这里我就不再介绍了~
1.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
这两行是导入MNIST的数据,如果本地没有数据,会自动从网络上下载。因为有监督的学习任务,所以还有对应的标签(也就是图像对应的真实数字),这部分位于(mnist.train.labels),标签也是以one-hot(one-hot就是有一个长度为N的数组,只有一位是1表示是某一个分类,其他位都是0)的方式表示,即这个数组共有10位,第2位1就是证明这个图像是数字1的图像。 例如,数字1的照片可表示为: 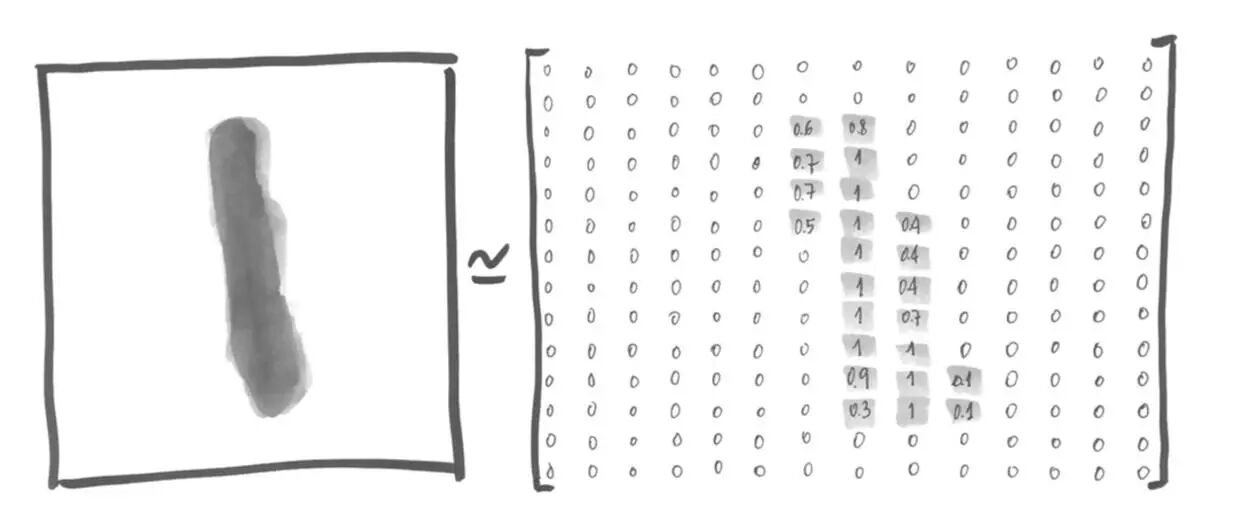 每一个位置代表了每一个像素灰的程序,取值0到1。这个矩阵可表示为一个28*28=784的数组。对应的one-hot数组为[0,1,0,0,0,0,0,0,0,0,0]。
每一个位置代表了每一个像素灰的程序,取值0到1。这个矩阵可表示为一个28*28=784的数组。对应的one-hot数组为[0,1,0,0,0,0,0,0,0,0,0]。
2.
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
这里定义
x = tf.placeholder(tf.float32, [None, 784])
784是因为MNIST的输入图像是2828的,所以转换成列是784,前面的None代表任意多个输入。 意思就是我们可以输入一个矩阵N784,代表N张MNIST图像数据。 定义
W = tf.Variable(tf.zeros([784, 10]))
这里有个小技巧,虽然模型是y = W * x + b 但实际上我们写代码的是都会写成y = x * W + b; 这个地方我觉得是两个原因 1.我们输入inputsize的数据,输出一个outputsize的预测结果,如果是x * W的,我们可以让 x = [N, inputsize];W = [inputsize, outputsize] 这样xXW 得到就是[N,outputsize]矩阵,每一横行都代表一个输入数据的预测结果,比较直观。如果我们使用W * x的形式的话,定义的矩阵就没有这么直观。 2.我还搜索了一下,发现有些资料说x * W的形式计算导数更加容易。
所以我们这里定义的W便是[inputsize, outputsize],因为MNIST输入的图像是28*28所以inputsize=784,我们要分类成0-9这十个数字,所以outpusize=10,因此b便是[10]
b = tf.Variable(tf.zeros([10]))
因为输出的size是10,所以这里定义一个长度为10的数组。
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
y是我们预测的输出,y_是真实的结果。 我们对y进行一下讲解,tf.matmul(x, W) + b是应用y = x * W + b模型,前面我们说过我们每次预测是很难100%确定我们预测的东西是什么,所以我们会输出一个概率数组,每一项标识是某一分类的概率。那怎么才能得到这个概率数组呢?这里我们使用softmax函数,那什么是softmax函数呢?我们简单介绍下,让大家有个简单的认识~ 首先我们先引用下维基百科上的定义 
简单的说softmax把一个k维的向量(a1,a2,a3,a4….aK)映射成(b1,b2,b3,b4….)其中bi是一个0-1的常数,然后可以根据bi的大小来进行多分类的任务,如取权重最大的一维。也有一个激活函数叫sigmoid通常也用于二分类任务。 这里有人可能要提问了,为什么不直接用y = x * W + b的输出来判断,而是再套一层softmax?
这里我觉有两个原因: 1.我们在训练的时候往往是通过改变W和b的值来拟合的,如果我们直接用y = x * W + b的输出结果,可能W和b值的一点小变化就会导致输出值产生比较大的波动,这样损失函数的波动也会比较大,这对我们进行预测是不利的,所以我们套一层softmax这样可以确保W和b的小幅改动时输出结果也是小幅改动,这样更利于训练。 2.通常直接的输出结果是不太直观的,比如输出[3.3, 1, 3 , 5]我们要进行一些转换,可以更好的将输出结果和输入结果进行结合,比如我们可以转换成[0, 0, 0, 1],表示我们预测的是第四个分类,但这个转换不太好不是1就是0,很多波动都没表现出来,同样不利于训练,所以我们还是采用softmax,这样输出结果就不会都为0,利于训练。当然跟我们采用的损失函数是交叉熵也有一定关系,下面还有介绍。
假如我们预测的[1]这个图像 它的 one-hot 向量是 [0,1,0,0,0,0,0,0,0,0],然后我们得到的y_是 [1.3, 33, 2, 1.2, 3.2, 0.5, 3, 9.2, 1],绘制如下 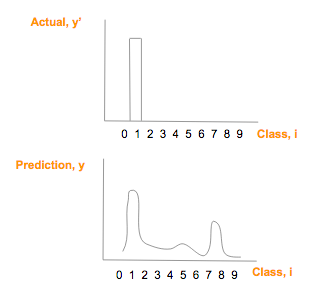 然后我们使用softmax公式进行概率转换
然后我们使用softmax公式进行概率转换 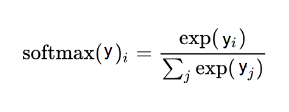 上面的公式还是比较简单的,如 a = [a1, a2, a3] 则
上面的公式还是比较简单的,如 a = [a1, a2, a3] 则 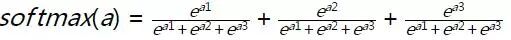 softmax([1.3, 33, 2, 1.2, 3.2, 0.5, 3, 9.2, 1])如下图所示
softmax([1.3, 33, 2, 1.2, 3.2, 0.5, 3, 9.2, 1])如下图所示 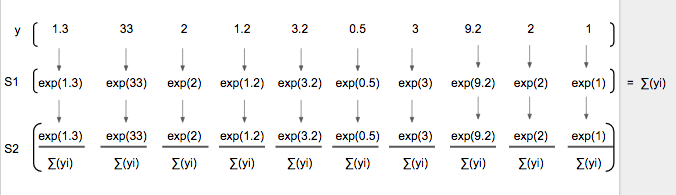 softmax(y)图形在形状上与 prediction (y) 相似,且所有项相加和为1,绘制如下
softmax(y)图形在形状上与 prediction (y) 相似,且所有项相加和为1,绘制如下 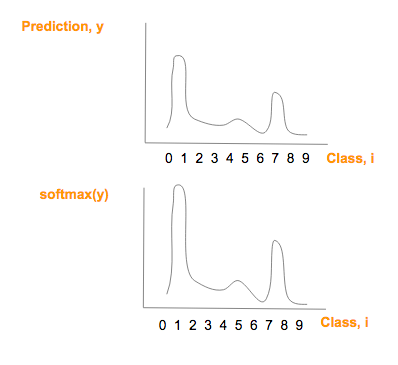
那怎么判断softmax后的结果和真实结果的相近程度呢? 也许有人想说想使用欧几里德距离,余弦距离等等前面这些也是可以的,但这里最适合是交叉熵(cross-entropy)。相关数学证明我们这里就不详细说明了。 交叉熵的公式 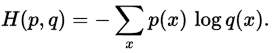 其中p(x)是真实的值,q(x)是我们预测的值 套用我们的y_和softmax(y)得
其中p(x)是真实的值,q(x)是我们预测的值 套用我们的y_和softmax(y)得 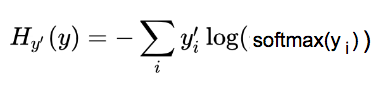 为了便于理解我们对这个公式分为3部分
为了便于理解我们对这个公式分为3部分 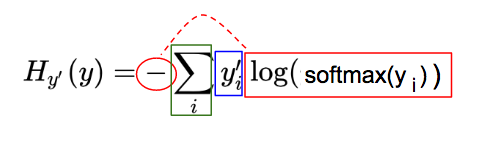 蓝:实际图像类(y’)对应的 one-hot 图
蓝:实际图像类(y’)对应的 one-hot 图 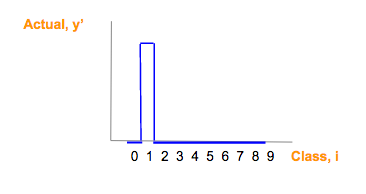 红:由预测向量元素(y)经过softmax(y),-log(softmax(y))一系列变化而来:
红:由预测向量元素(y)经过softmax(y),-log(softmax(y))一系列变化而来: 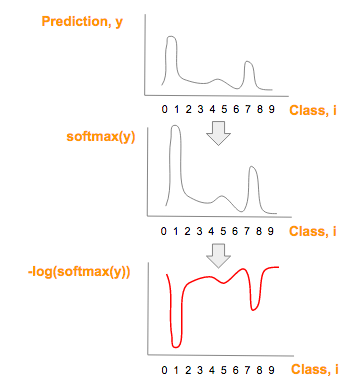 绿:每一图片类别 i,其中,i = 0, 1, 2, …, 9, 红蓝部分相乘的结果
绿:每一图片类别 i,其中,i = 0, 1, 2, …, 9, 红蓝部分相乘的结果 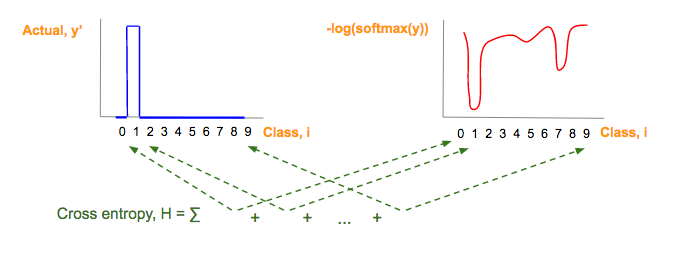 于是有了下面这行代码
于是有了下面这行代码
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) reductionindices的默认值时None,即把inputtensor降到0维,也就是一个数。 对于2维inputtensor,reductionindices=0时,按列;reduction_indices=1时,按行。因为我们每行都是一组输入,所以这里按行。
3.
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) 这里我们仍旧采用梯度下降的方法,学习速率0.5,目的是减小损失函数cross_entropy。
4.
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(64)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
这里开始输入数据进行训练,分为1000个迭代,每次迭代输入64组数据,是用的小批梯度下降 (Mini-Batch Gradient Descent),每次迭代TF都会自动学习W和b的值。
5.
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) correct_prediction便是我们预测的正确与否的数组。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。后面的1也是代表按行。 我们实例运行输出一下y看看值 [ 5.85600610e-05 3.37338224e-09 9.09965966e-05 1.22266507e-03 1.30357535e-06 1.67362687e-05 7.03774949e-09 9.98453379e-01 1.52235698e-05 1.41092940e-04] 我们对其tf.argmax便可以得到7,因为下标为7的位置概率最大(从0开始)。这样每一行数据都会得到一个数表明该行数据预测的值是多少。
tf.equal会将相应位置的值进行比较相同True,不同得到False。 经过上面的运算correct_prediction便得到了一个对所有数据预测正确与否的数组。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.cast(correct_prediction, tf.float32)是将我们前面得到的[True,False,True…]数组转换为[1.0,0,1.0….]
tf.reduce_mean对转换得到的数组求平均数,这个值便是预测正确率。
我们运行整个程序i7的电脑CPU耗时1.5秒左右,最后的正确率在92%左右。
参考附录
1.https://medium.com/all-of-us-are-belong-to-machines/gentlest-intro-to-tensorflow-4-logistic-regression-2afd0cabc54#.pq40rg98t 2.http://neuralnetworksanddeeplearning.com/chap3.html#softmax
题图:pexels,CC0 授权。

点击阅读原文,查看更多 Python 教程和资源。










