AI科技评论按:虽然CVPR 2017已经落下帷幕,但对精彩论文的解读还在继续。下文是宜远智能的首席科学家刘凯对此次大会收录的《结合序列学习和交叉形态卷积的3D生物医学图像分割》(Joint Sequence Learning and Cross-Modality Convolution for 3D Biomedical Segmentation)一文进行的解读。
3D医学图像的切割的背景
3D医学图像的切割是医学图像处理里一个非常重要的工作,比如脑部MRI数据、肺CT数据和X光数据等等。现在大多数的3D医学图像分割方法都只用了一个形态或把多个形态堆起来变成不同的通道,该工作中提出了一个包含交叉形态卷积层(cross-modality convolution layer)的深度编码-解码的网络结构(deep encoder-decoder structure)来合并核磁共振的不同形态,还利用卷积LSTM来对2D切片序列建模,并且把多形态卷积和LSTM网络结合在一起,做到端到端的学习。为了防止收敛到某一特定的类,论文中使用了权重策略和two-stage训练来处理类不均匀的情况。
该工作主要针对使用核磁共振(MRI)对脑部肿瘤部位做切割。脑肿瘤如神经胶质瘤和胶质母细胞瘤有各种不同的形状,并且会出现在大脑的任何地方,对精确的定位肿瘤带来了挑战。脑肿瘤手术扫描头部肿瘤的核磁共振有四种不同策略,自旋晶格弛豫(T1),T1-对比(T1C),自旋自旋松弛(T2)和流体衰减反转恢复(FLAIR),对应着四种不同的形态,每一种扫描的策略对不同的肿瘤组织会有特定的反应,可以利用多种形态的核磁共振图像来自动的区分肿瘤组织,辅助医生诊断。
网络结构
该工作的主要贡献是把多形态卷积和LSTM网络结合在一起,做到端到端的对3D影像做切割。网络结构的输入是多形态的核磁共振数据序列,可以给每个像素预测出肿瘤类型,模型主要包含三个部分:多形态编码,交叉形态卷积和卷积LSTM。系统的详细框架如下图1,不同形态的切片被堆叠在一起(b)然后传到多形态编码部分里不同的卷积网络(一个卷积网络对应一种形态),获得语义上的隐藏特征表示(c),多个形态的隐藏特征在交叉形态卷积层发生聚合(d),然后使用卷积LSTM来更好的挖掘连续切片的空间序列关联(e)。通过拼接2D的预测结果序列生成3D图像分割。模型综合切片序列学习和多形态融合一起优化,形成一个端到端的系统。
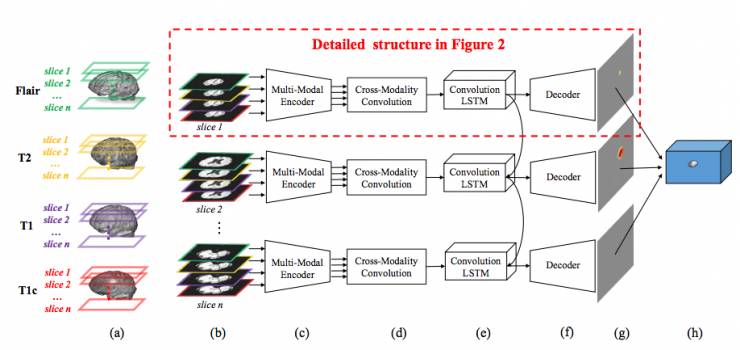
图1 系统框架:(a)根据切片为每个3D核磁共振形态(Flair, T2, T1, T1c)提取切片,(b)相同深度的4个切片被堆叠在一起,(c)每个堆里面4个切片被放到多形态编码器里面学习隐藏语义特征表示,(d)利用交叉形态卷积来聚合不同形态的信息,(e)利用卷积LSTM来对连续的切片建模,(f)解码网络用来对卷积LSTM的输出进行上采样,获得和输入图像一样的分辨率,(g)最后的结果是对每个像素位置预测肿瘤类型,(h)堆叠2D的预测结果到3D的分割。
系统的三个主要部分:
(1)编码器和解码器
因为BRATS-2015训练集比较小,我们希望多形态编码器和解码器的参数尽量少,防止过拟合。编码器是用和SegNet类似的结构,包含4个卷积层和4个最大池化层。每个卷积层用3X3的核来生成特征映射,然后通过batch Norm层和ReLU。最大池化层大小为2,步长为2,下采样的因子为2。在解码器网络,每个解卷积层做转置卷积,然后用一个卷积和batch normalization。完成上采样后,特征映射变成了和输入一样的分辨率。我们再把解码器的结果到多标签的soft-max分类器来输出每个像素每个类的概率。
(2)交叉形态卷积
用来融合全部的形态,在多形态编码器之后,4个形态的切片被编码成了一个大小为h*w*C的空间,w和h是特征的维度,C是通道,我们把4个形态同一个通道的切片放到一起,变成C*4*h*w的特征空间,然后用核为4*1*1的核来做3D卷积。这样同时综合了空间信息和不同的形态信息。
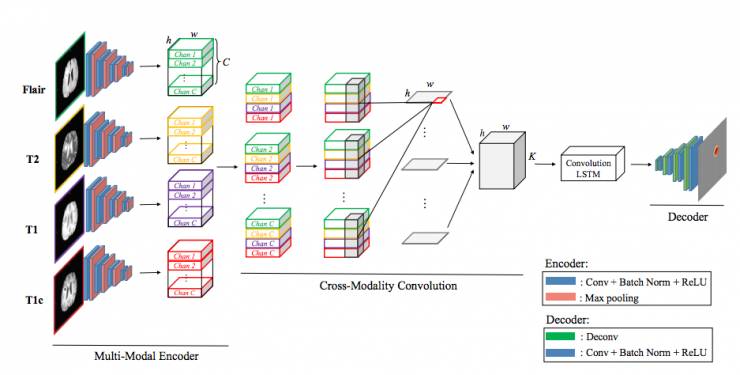
交叉形态卷积相当于给4个形态设置了权重。多形态编码器输出的特征是4*h*w*C的,我们reshape成C*h*w*4的然后做交叉形态卷积。
(3)切片序列学习
该工作使用一个端到端的切片序列学习框架去建模切片之间的相关性。使用带卷积的LSTM,和普通的LSTM区别是,在输入到初始状态以及状态之间的转移,卷积LSTM(convLSTM)把矩阵乘法替换为卷积操作,这样就保留了较长系列的空间信息。
除了方法上的创新,在应用方面也有一些不错的trick,比如:
1.BRATS-2015数据集的类严重不均匀,模型容易收敛到预测所有的像素为没有肿瘤问题,使用了median frequency平衡法,在交叉熵loss函数设定了一个权重。
2.两阶段训练:第一阶段只采样包含了肿瘤问题的切片,然后用median frequency方法来减少大类的权重,在第二阶段,降低学习率,去掉median frequency,让分布接近真实的分布。
3.在第一阶段训练中,避免采样到空的序列(全部切片都是正常的大脑组织)。训练LSTM的时候,使用正交初始化来处理梯度消失的问题。
缺陷
这篇论文有一点小瑕疵,虽然提到KU-Net模型是和他们方法最相关的模型,但是在最后实验部分提了因为KU-Net没有公开源码而没有进行实验对比,这种理由比较少见,个人认为既然很相关,应该把别人的算法实现,然后跟他们的结果作比较才比较有说服力。
论文地址:https://arxiv.org/abs/1704.07754
———————— 给爱学习的你的福利 ————————
CCF-ADL在线讲习班 第80期:区块链—从技术到应用
顶级学术阵容,50+学术大牛
快速学习区块链内涵,了解区块链技术实现方法
课程链接:http://www.mooc.ai/course/113
或点击文末阅读原文

——————————————————————————











