Long Short Term Memory(LSTM) are the most common types of Recurrent Neural Networks used these days.They are mostly used with sequential data.An in depth look at LSTMs can be found in this incredible blog post.
Our Aim
As the title suggests,the main aim of this blogpost is to make the reader comfortable with the implementation details of basic LSTM network in tensorflow.
For fulfilling this aim we will take MNIST as our dataset.
The MNIST dataset
The MNIST dataset consists of images of handwritten digits and their corresponding labels.We can download and read the data in tensorflow with the help of following in built functionality-
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
The data is split into three parts-
Training data(mnist.train)-55000 images of training data
Test data(mnist.test)-10000 images of test data
Validation data(mnist.validation)-5000 images of validation data.
Shape of the data
Let us discuss the shape with respect to training data of MNIST dataset.Shapes of all three splits are identical.
The training set consists of 55000 images of 28 pixels X 28 pixels each.These 784(28X28) pixel values are flattened in form of a single vector of dimensionality 784.The collection of all such 55000 pixel vectors(one for each image) is stored in form of a numpy array of shape (55000,784) and is referred to as mnist.train.images.
Each of these 55000 training images are associated with a label representing the class to which that image belongs.There are 10 such classes(0,1,2…9).Class labels are represented in one hot encoded form.Thus the labels are stored in form of numpy array of shape (55000,10) and is referred to as mnist.train.labels.
Why MNIST?
LSTMs are generally used for complex sequence related problems like language modelling which involves NLP concepts such as word embeddings, encoders etc.These topics themselves need a lot of understanding.It would be nice to eliminate these topics to concentrate on implementation details of LSTMs in tensorflow such as input formatting,LSTM cells and network designing.
MNIST gives us such an opportunity.The input data here is just a set of pixel values.We can easily format these values and concentrate on implementation details.
Implementation
Before getting our hands dirty with code,let us first draw an outline of our implementation.This will make the coding part more intuitive.
A vanilla RNN
A Recurrent Neural Network,when unrolled through time,can be visualised as-
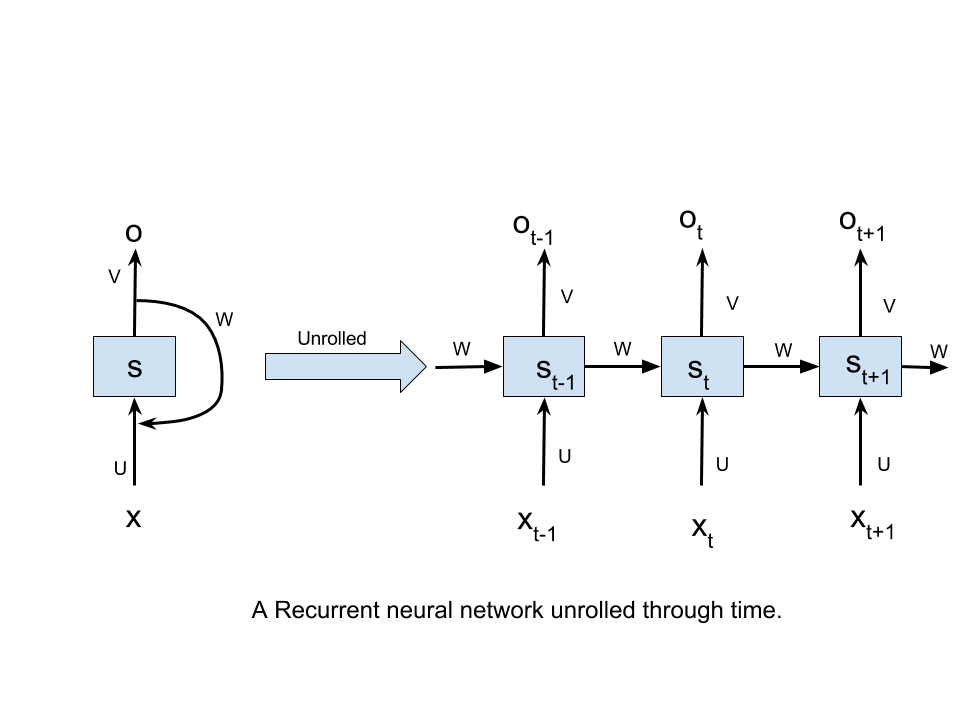
Here,










