
作者Tony Siciliani 本文为36大数据独译,译者:随风
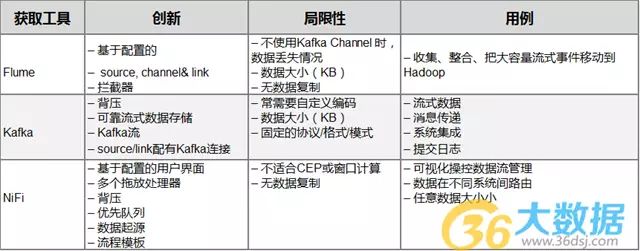
我们在建设一个大数据管道时,需要在Hadoop生态系统前仔细考虑,如何获取大体量、多样化以及高速性的数据。在决定采用何种工具以满足我们的需求时,最初对于扩展性、可靠性、容错性以及成本的考虑便发挥了作用。本文,我们将聚焦于三种Apache获取工具:Flume, Kafka, and NiFi。这三种工具在横向比较中都展示出了良好的性能,同时还提供了一种插件体系结构,在这种结构中可通过定制组件来使功能得到扩展。
一个Flume部署包括一个或多个配置有拓扑结构的agent。Flume Agent是一个JVM进程用来控制Flume拓扑结构的基本构件,其中包括source, channel 和sink。Flume客户先把event传送到source,source再把这些events成批放置到一个叫做channel的暂时缓冲区,然后数据从此流向连接数据终端的sink。一个sink也可以是其它Flume agents的后续数据资源。Agent之间可以被连接,并且含有多个source,channel和sink。
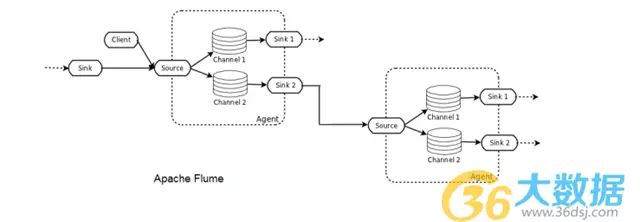
Flume是一个分布式的收集、聚合和将事件流传输到Hadoop的系统。它配备有多个内置source、channel和link,比如Kafka Channel and Avro sink。Flume是基于配置的并且含有拦截器以对传输中的数据进行简单转换。
如果不小心谨慎,使用Flume是很容易把数据丢失掉的。比如,为寻求高吞吐量而选择memory channel(记忆渠道)的弊端是,当agent节点下降数据就会丢失。File channel(文件渠道)则以延长潜伏期为代价而提供持久性。即使如此,因为数据并没有复制到其他节点,所以file channel的可靠性就只能和普通磁盘一样。Flume 的确通过多跳/扇入扇出流来提供扩展性,对于高可用性,agent可以被横向衡量。
Kafka是一种高吞吐量的分布式消息总线,它可以使数据生产者从消费者中分离出来。各种消息被组织到话题中,然后将话题分成多个分区,通过节点再将分区成批复制,这叫做代理。与Flume相比,Kafka有更好的延展性以及信息持久性。Kafka现有两种类型:一种是“经典”生产者/消费者模式,另一种是新 Kafka-Connect,它可以给外部数据商店提供可配置连接器。
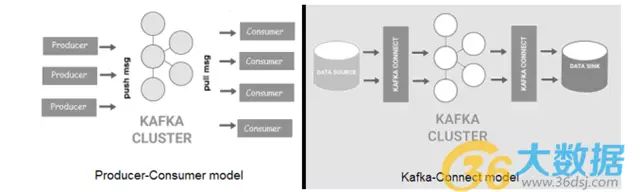
Kafka可用于大型软件系统构件中的事件处理和整合。 数据飙升,背压可以立即被处理。除此之外,Kafka还配置有Kafka Streams,对于Apache Spark 或 Apache Flink来说,这可以用于简单的流处理而不需要一个单独集群。
因为信息被留存在磁盘上并且在集群内被复制,所以信息丢失的情况就不像Flume那么普遍。也就是说,生产商/源和消费者/链经常需要自定义编码,要么使用Kafka客户端,要么通过Connect API。 和Flume一样,它在信息大小方面也有局限性。最终,为了能够交流,Kafka生产商和消费者都不得不同意协议、格式、模式,但这些在某些情况下还是存在问题的。
不同于Flume和Kafka,NiFi可以处理任意大小的信息。在一个基于网站的拖放UI(用户界面)背后, NiFi可在集群中进行运作并且提供实时操控,这就使得在任何源和目的地之间,管理数据移动变得更加容易。它支持存在不同格式、模式、协议、速度和大小的分布源。

NiFi可用于有着严格安全要求和达标要求的任务关键数据流中,在那里我们可以看见整个过程并且做出实时改变。在编写时,有将近200个非传统的处理器(包括Flume和Kafka处理器),它们可以被拖&放、配置并且立即投入使用。 NiFi的一些关键特征被优先呈现, 比如数据的可追踪性和每次连接的背压门限配置。
尽管NiFi被用于制造可容错生产管线,但它至今仍不能像Kafka一样复制数据。节点如果下降,那么数据流就可能被导向另一个节点,但是在失败节点后排队的数据就不得不等待直到节点回来。NiFi既不是一个成熟的ETL工具,也不是适合CEP的理想型。为此,NiFi反而应该像Apache Flink, Spark Streaming 或 Storm一样连接到一个流式框架。
这并不是有且只有一个工具,能同样把所有事情都做好并解决你所有的需求。把能以更好的方式做不同事情的工具结合起来,就会把功能集结起来,同时在处理一大串情况时就会增强灵活性。NiFi和Flume会根据你的需求,也可以做到像Kafka生产商和消费者一样的。
Flume和Kafka的结合现在非常流行,它有一个专属名字:Flafka(这并不是编造的)。Flafka包括一个 Kafka source, Kafka channel和Kafka sink。当通过Kafka渠道(channel)时,Flume event就被存储起来并且为了弹性就通过Kafka代理被复制了下来。把Flume和Kafka结合起来就使得Kafka避免自定义编码,同时也利用了Flume经检验的 source和sink。
结合两种工具或许显得很浪费,因为这好像在功能上有些重叠。比如,NiFi和Kafka都能提供代理来连接生产者和消费者。然而,他们所做的却截然不同:在Nifi中,大多数数据流逻辑并不在生产者/消费者中,而是存在于代理中,这就有利于集中控制。NiFi被建造用于做了一个重要的事情,那就是数据流管理。把两种工具相结合,NiFi就可以解决Kafka所不能解决的数据流挑战,同时又利用了Kafka可信赖的流式数据存储。
仍有很多的内容要谈论,但如果那样的话,这就是一本书的主题了而不只是一篇文章。同时,正如这里所提及的工具飞速进展一般,这篇简洁的分析也会像其他人看待新兴科技一样,迟早会过时的。
End
如果有人质疑大数据?不妨把这两个视频转给他
视频:大数据到底是什么 都说干大数据挣钱 1分钟告诉你都在干什么
人人都需要知道 关于大数据最常见的10个问题
从底层到应用,那些数据人的必备技能
如何高效地学好 R?
一个程序员怎样才算精通Python?
排名前50的开源Web爬虫用于数据挖掘
33款可用来抓数据的开源爬虫软件工具
在中国我们如何收集数据?全球数据收集大教程
PPT:数据可视化,到底该用什么软件来展示数据?
干货|电信运营商数据价值跨行业运营的现状与思考
大数据分析的集中化之路 建设银行大数据应用实践PPT










