用 10 周时间,让你从 TensorFlow 基础入门,到搭建 CNN、自编码、RNN、GAN 等模型,并最终掌握开发的实战技能。4 月线上开课,
www.mooc.ai
现已开放预约。
雷锋网按:
在近日(4 月 28 日)的北京 GMIC 大会新技术演示 Show 上,王璠向外界展示了中科创达在嵌入式人工智能方面所做的工作。这位百度出身的 90 后的技术总监,目前带领着一支 30 人的 ThunderView 技术团队专注于嵌入式 AI 的算法研究。
目前在人工智能领域,不管是学术圈还是工业圈,大家都认同一个趋势,那就是在很多应用场景上计算需要落地到设备上,让设备拥有智能化——即嵌入式的 AI,这个是人工智能领域新开辟出的一个分支。
中科创达技术总监王璠坚定的对雷锋网说。

↑ 王璠
那么什么是嵌入式 AI 呢?
据雷锋网了解,所谓嵌入式 AI,就是设备无须联网通过云端数据中心进行大规模计算去实现人工智能,而是在本地计算,在不联网的情况下就可以做实时的环境感知、人机交互、决策控制。
谈及嵌入式 AI 和云端计算的 AI 的区别,王璠告诉雷锋网,对于一般的 AI 系统,数据可以在服务器端进行计算,人们往往会通过增加模型的大小、网络的深度,调用尽可能多的计算资源,以期得到更加精确的计算结果。而对于嵌入式 AI 来说,就需要反其道而行之了,王璠总结道,
云端计算的 AI 致力于如何更好的解决问题,而嵌入式的 AI 则致力于如何更加经济的解决问题。
嵌入式 AI 的应用场景有哪些?
对于嵌入式 AI 的应用场景,王璠表示,云端计算虽然精确度高,但并不是所有的场景都适合,比如:
-
辅助驾驶或者自动驾驶系统
,如果在云端计算,设备端采集到数据后上传,计算完成后再返回终端,这样会不可避免的带来一定的延时,而在驾驶的场景中,这种延时意味着危险系数的提高。
-
数据安全
,比如家里安装了一个监控摄像头,用来关注老人和孩子的安全,上传到云端的计算也意味着隐私被泄露的风险提升。
-
脱机
,虽然现在通信技术发展的很快,但是仍然会碰到在地下停车场、商场里没有信号的情况,这时候就不能指望云端计算有很好的用户体验了。
所以,嵌入式的人工智能还是有很大的市场需求的。
同样是做嵌入式的人工智能,地平线 CEO 余凯曾经说过,嵌入式 AI 的应用场景地平线看好三个方向:安防、智能家庭、智能驾驶。对此,王璠也表示赞同,同时表示这三个方向在实现难度上也是逐渐递增的。
从算法方面来看,目前 ThunderView 算法解决方案包括深度学习算法、算法优化、算法集成三个部分。王璠提到,深度学习算法和算法优化这两个部分在执行过程中是高度耦合在一起的,同时算法优化部分的工作非常重要,难度也最大。目前他们已经在图像处理、机器视觉等领域取得了一些成果,王璠告诉雷锋网:
在 2017 年的国际消费类电子产品展览会(CES)及世界移动通信大会(MWC)上,我们团队携手高通公司在高通展台上展示了我们的物体识别及智能拍照引导算法。这些算法独立运行在高通的便携设备上,支持单机运行,不需要联网。实时识别物体,实时对用户的拍照行为进行引导。
也是在今年的 MWC 上,我们联合 ARM 公司在 ARM 展台展示了食品识别及热量估算的算法。利用在 ARM 设备上的深度学习引擎,我们在 ARM 双摄设备上展示了食品识别和热量估算的移动应用程序。

↑ MWC2017 高通展台展示的 ThunderView 算法技术
因为对于深度学习的网络模型而言,如果一个应用场景优化的比较好的话,是可以将其适配到不同的任务中的。所以目前我们的选择是先把基本场景做好,然后再将技术推广至不同的领域。比如现在和高通的合作是在检测方面,和 ARM 的合作是在分割和识别方面,而我们的目标是要在每一个领域至少做到业界 state of the art 的水平,王璠信心满满的告诉雷锋网。
那么如何更加经济的用嵌入式 AI 解决问题呢?
王璠表示,嵌入式设备的计算资源有限,虽然移动芯片的计算能力突飞猛进,拿现在能力最强的高通骁龙 835 为例,它的单精浮点运算性能为 630GFLOPS,比起 2000 年前后的超算,已经可以进入前 100 了。但是比起现在 PC 端的 Tesla P100,其单精浮点运算性能可达 10TFLOPS,仍有十几倍的差距。这就意味着嵌入式 AI 和 PC 端的玩法将完全不同。
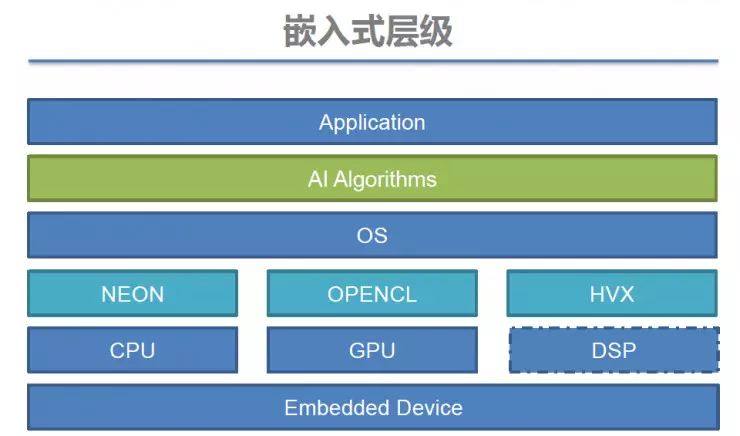
一般来说嵌入式的开发层级从上到下可以分为:应用层(Application),算法层(AI Algorithms),操作系统层(OS),驱动层以及芯片层。由于移动芯片计算能力的限制,嵌入式人工智能除了需要优化算法层之外,还需要关注底层驱动和操作系统的优化——这就需要算法团队不仅在操作系统领域里经验丰富,还需要和芯片厂商有紧密的合作。
同时,对于嵌入式,用户对功耗和发热等性能要求又极为敏感。所以王璠表示,综合这些因素后,现阶段我们做嵌入式的计算必须要有高效、经济的算法。而要达到这个目标,则需要从硬件和软件两方面着手。
硬件
对于中科创达,硬件是基于高通、ARM 这些厂商的芯片。不仅如此,王璠提到,他们在技术层面的合作已非常深入,目前的合作方式为硬件厂商开发加速引擎,并将芯片提前提供给中科创达算法团队来开发技术,这个过程中硬件厂商会基于算法团队提出的一些意见来改进引擎。王璠举了个例子,中科创达在 MWC2017 上和高通合作系统,高通在硬件优化上面提供了很大的帮助,他们内部开发了一个完全针对与深度学习算法的加速引擎,使运算获得了 5 倍左右速度的提升。一个好的引擎,可以让 AI 系统落地到嵌入式设备上取得事半功倍的效果。
软件
软件方面则需要更加经济的计算模型,在保证准确率的前提下,尽量减少计算量。
首先是一个经济的网络设计。
用深度学习的方法来处理 AI,很多时候是一个搭积木的过程。随着现在人工智能方面开源的程度越来越大,从网上能得到的公开资源诸如文章、网络结构、评测、训练好的模型等等都很多,善用这些资源,把各模块嵌到网络里面,达到既满足你当前的需求,又具有更好效果的网络。
第二,从繁入简。
传统的 AI 的算法,都是在一个很庞大的集群来运行的。在这种情况下,网络的大小可能到几百兆,甚至几个 G,速度也比较慢。假如要放到嵌入式上,就需要从繁入简。这里有两个方法:
第三点,适用场景。
对于不同的任务场景,最优的网络设计是不一样的。尤其在嵌入式上,需要尽可能的让运行速度更快。测试集和用户实际使用场景是不一样的,所以在模型设计好后还需要根据用户可能碰到的实际情况做适配。
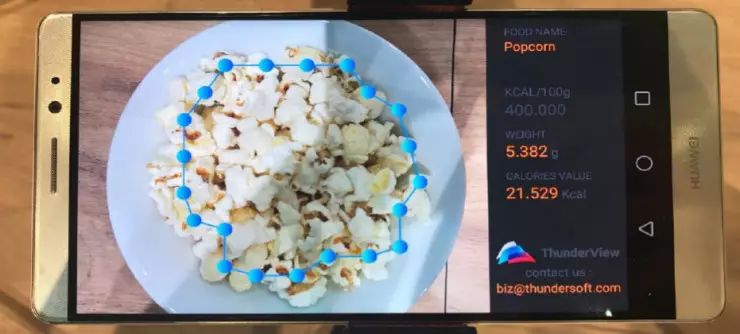
↑ MWC2017ARM 展台展示的 ThunderView 算法技术
第四点是共享参数。
尽可能的用同一套参数来完成多种不同的任务。比如在 MWC 上,创达和 ARM 联合做的一个技术,主要是做食物的识别和卡路里的计算。我们需要完成的任务,降到算法层级来说,需要第一知道是什么食物,第二要知道这个食物在哪里,轮廓是多大,知道体积后才能估计它有多少卡路里。在做食物分类的时候,在深度学习的参数内部已经包含了很多关于这个食物的信息。当最后把分割任务加进去的时候,实际上并没有浪费任何一个多余的参数,只是最后抽出来一些特征,做一个简单的拟合,就可以得到一个比较好的效果。
最后,王璠总结道,要想嵌入式人工智能玩得好,必须做到软硬件的充分结合。
TensorFlow & 神经网络算法高级应用班” 要开课啦!
从初级到高级,理论 + 实战,一站式深度了解 TensorFlow!
本课程面向深度学习开发者,
讲授如何利用 TensorFlow 解决图像识别、文本分析等具体问题。课程跨度为 10 周,将从 TensorFlow 的原理与基础实战技巧开始,一步步教授学员如何在 TensorFlow 上搭建 CNN、自编码、RNN、GAN 等模型,并最终掌握一整套基于 TensorFlow 做深度学习开发的专业技能。
两名授课老师佟达、白发川身为 ThoughtWorks 的资深技术专家,具有丰富的大数据平台搭建、深度学习系统开发项目经验。
时间:
每周二、四晚 20:00-21:00
开课时长:
总学时 20 小时,分 10 周完成,每周 2 次,每次 1 小时
线上授课地址:
www.mooc.ai(点击
阅读原文
查看)





