基础准备
前面我们介绍了多重线性回归模型的基础内容及SPSS软件的操作过程,同时也介绍了如何通过各种指标判断多重线性回归模型的拟合质量如何。
数据分析技术:多重线性模型;也难也不难的建模从这里开始吧!
SPSS分析技术:多重线性方差分析;自主创业不能盲目,你做好市场调研了吗?
SPSS分析技术:回归模型的自变量筛选方法;全军出击OR稳扎稳打步步为营
如果拟合质量不好,可能存在的问题主要有以下两个方面:
-
极端值(强点)的影响
。我们都知道,在线性回归分析中,自变量回归系数的确定主要采用最小二乘法,而最小二乘法的原理就是兼顾每个数据点的影响,使得最后的离差平方和最小。最小二乘法就好比生活中的老好人,谁都不得罪,与某些小团体内的人人或者特别有个性的离群者都保持相同程度的联系,这时小团体的人很可能因为看到其与离群者的关系而刻意疏远他。用最小二乘法拟合得到的多重线性回归模型同样如此,会极大的受到极端值的影响而失去客观和准确性。
-
自变量间的多重共线性问题
。多重共线性指自变量间存在线性相关关系,也就是说自变量间可以互相建立线性回归方程。若自变量间存在多重共线性关系,那么得到的多重线性回归模型也是不准确和不可用的。
案例分析
本篇采用的案例依旧是上篇文章:
SPSS分析技术:回归模型的自变量筛选方法;全军出击OR稳扎稳打步步为营
的内容。下面我们还是以上篇文章的数据来判断和解决极端值和多重共线性问题。文章的数据都已经上传到QQ群中,大家可以前往QQ群的群文件中下载,跟随学习。
案例的研究背景是固体垃圾的产生量与城市不同用途土地面积之间的多重线性回归模型的建立。
极端值检查过程和结果
极端值可以用两种指标来检查:残差和极端值统计量。SPSS软件利用残差进行极端值检查需要在【分析】-【回归】-【线性】-【统计】中选择下图残差区域的个案诊断,系统默认的离群值为3个标准差(注意,这里将残差进行标准化处理)。
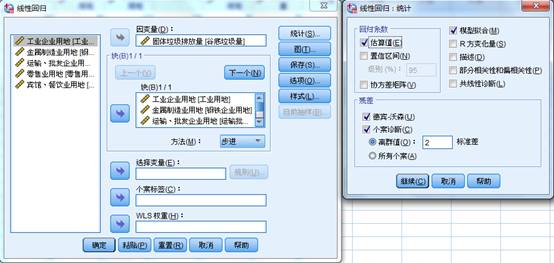
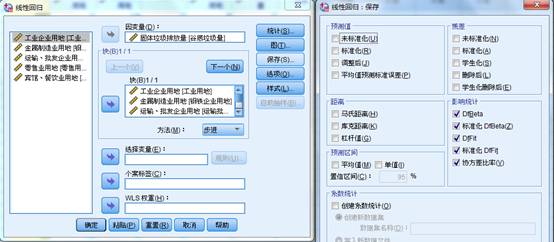
除此之外,还可以选择【保存】按钮,在影响统计中,将DfBeta、标准化DfBeta、DfFit、标准化DfFit和协方差比例选中。以上这些指标的分析逻辑都是比较删除某个记录前后,偏回归系数或残差的差异情况,以此来判断极端值(离群值),值越大,极端值的可能性越大。为了便于比较,其中两个标准差指标如果大于2,可以认为是极端值。
案例的分析结果
个案诊断结果,可以发现,第8个数据点的标准化残差值达到2.105,大于2,可以认为该数据点是极端值(离群值)。结合第8个数据点的标准化DfFit值1.42,虽然小于2,但是大于1。综合两个结果,可以认为该数据点是极端值。

对于极端值,我们不能盲目的直接删除了事。应该找到该值,考虑是否是录入错误或者是某些特殊情况导致该值的离群,如果是以上两种情况导致的,那么可以修改和删除该数据点。如果以上两种情况都不符合,那么需要考虑是否采用加权最小二乘法进行多重线性回归,或者增加样本量,看是否是样本量过小导致该值类似的情况出现较少,使得该值成为极端值。
多重共线性的检查与处理
自变量的多重共线性会导致得到的多重回归模型存在错误,不能显示自变量与因变量之间真实的相互关系情况。如果自变量间存在多重共线性关系,那么在用SPSS进行多重线性回归分析时,可能会出现以下这些违反逻辑的情况:
-
整个回归模型的假设检验是通过的,但是个别自变量的检验却无法通过。
-
专业上认为应该有统计学意义的自变量检验结果却是没有统计学意义。
-
有些自变量的回归系数大小或符号与实际情况相违背,难以解释。
-
增加或删除一个自变量,有些自变量的回归系数出现大的变动。
如果多重回归模型出现以上情况,那么就应该考虑自变量存在多重共线性问题。SPSS对于多重共线性的判断指标有以下几种:
容忍度(Tolerance)
、
方差膨胀因子(VIF,Variance Inflation Factor)
、
特征根(Eigenvalue)
、
条件指数(Condition Index)
和
变异构成(Variance Proportion)
。
-
容忍度(Tolerance)等于1减去以该自变量为因变量,其它自变量依旧为自变量的线性回归模型的决定系数的剩余值(1-R方)。显然,容忍度越小,共线性越严重。一般的认识是,当容忍度小于0.1时,存在严重的多重共线性。
-
方差膨胀系数(VIF)等于容忍度的倒数。一般情况下,VIF的值不应该大于5,放宽到容忍度的水平,就是不应该大于10。
-
特征根(Eigenvalue)对模型中常数项及所有自变量计算主成分,如果自变量间存在较强的线性相关关系,则前面的几个主成分数值较大,而后面的几个主成分较小,甚至接近于0。
-
条件指数(Condition Index)等于最大的主成分与当前主成分的比值的算数平方根。第一个主成分被定义为1。如果有几个条件指数较大,那么就提示存在多重共线性关系。
-
变异构成(Variance Proportion)是指回归模型中常数项和自变量项被主成分解释的比例。如果某个主成分对两个或多个自变量的解释的比例都较大,说明这几个自变量间存在一定的共线性。
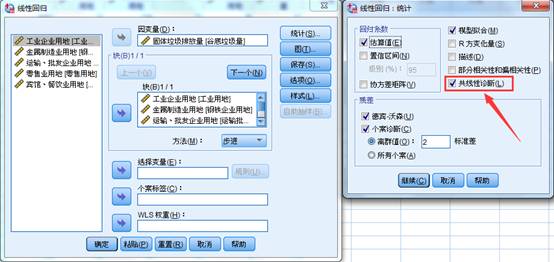
在SPSS中选中【统计】按钮中的共线性诊断,就会输出上面的结果。
我们依旧使用上面的例题为例,介绍各种共线性诊断指标的作用。我们首先看容忍度和方差膨胀系数(VIF)的结果。可以看到在全部生成的四个线性回归模型中,只有最后一个模型的宾馆、餐饮用地和零售业用地这两个自变量的容差小于0.2,VIF值大于7,说明这两个自变量间存在共线性关系。
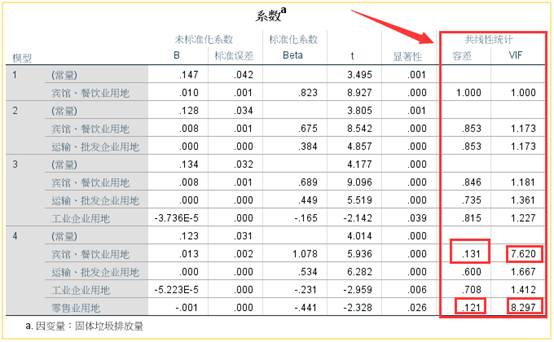
再结合特征根、条件指数和变异构成这三个指标。前面三个模型的特征根差距不大,第四个模型的前四个特征根与最后一个存在较大的差异,说明该模型可能存在共线性情况。再看条件指标,第四个模型的最后一个公因子的条件指标达到8.642,同样说明了这个可能性。最后看变异构成,最后一个公因子中,宾馆餐饮用地与零售业用地的公因子方差解释比例都达到0.96,说明它们之间存在共线性。
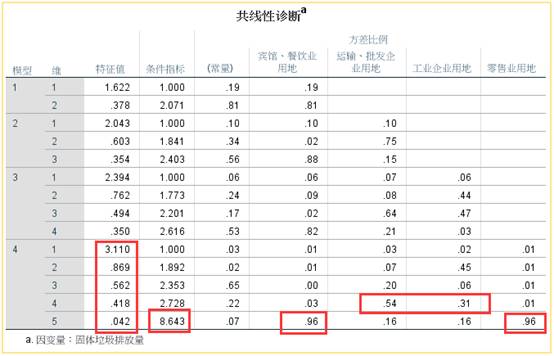
结合以上五个因子,我们可以认为宾馆餐饮用地与零售业用地这两个自变量间存在共线性情况。需要做进一步处理。
除了以上这五个指标以外,还可以使用前面提高过的散点图举证和简单线性相关系数矩阵来判断它们之间是否存在多重共线性关系。如果发现自变量间存在多重共线性时,可以采用以下方法解决:
-
逐步回归:
逐步回归能够在一定程度上对多重共线性的自变量组合进行筛选,将对因变量变异解释较大的自变量保留,而将解释较小的自变量删除。遗憾的是,对于共线性较为严重时,逐步回归的变量自动筛选方法就显得无力了。
-
岭回归:
岭回归是一种专门用于共线性数据分析的有偏估计回归方法,它实际上是一种改良的最下二乘法,通过放弃最小二乘法的无偏性,以损失部分信息,降低精度为代价来寻求效果稍差但是回归系数更符合实际的回归方程。
-
主成分回归:
主成分回归能够对存在多重多重共线性的自变量提取主成分,提取出来的主成分之间是完全互相独立的,然后再用提取出来的主成分与其它的自变量一起进行多重线性回归。
-
路径分析:
如果自变量之间的联系规律比较清楚,比如很多实证研究中的变量情况。那么可以考虑使用路径分析模型。
岭回归、主成分分析和路径分析我们将在后面的文章中详细介绍!!!
所有例题的数据文件都会上传到QQ群中,需要对照练习的朋友可以前往下载,QQ群号见下方温馨提示或直接扫描下方二维码加入!
温馨提示:
-
SPSS教学视频,请点击
:
《SPSS入门基础》视频教程
;
-
生活统计学QQ群:
134373751,
用于分享文章提到的各种案例资料、软件、数据文件等。支持各种资料的直接下载和百度云盘下载。
-
生活统计学微信交流群,
用于各自行业的数据研究项目及其成果交流分享;由于人数大于100人,请添加微信possitive2,拉您入群。
-
数据分析咨询,请点击首页下方“
互动咨询
”板块,获取咨询流程!






