20万,这是新智元今天达到的用户总数。在飞向智能宇宙的旅程中,感谢每一位和新智元同行的朋友。您的关注和支持是“新智元号”星舰永不枯竭的燃料。
20 万,每一位乘客对我们来说都弥足珍贵。我们希望加深对每一位乘客的了解,恳请您对这份问题不多、且不涉及任何隐私的调查问卷给出宝贵的反馈。
新智元正在举行
评论赠书活动
,
点击阅读原文投票
,并留下你对新智元公众号的建议,赢取《深度学习》免费赠书。
来源: 2017.icml.cc
作者:Sergey Levine and Chelsea Finn
编译:四叠半
【新智元导读】
本文来自 ICML 2017 的 tutorial,主题是深度学习应用中的决策和控制问题,
介绍了与强化学习相关的强化和最优控制的基础理论,以及将深度学习扩展到决策和控制中的一些最新成果,包括基于模型的算法,模仿学习和逆向强化学习,探索当前深度强化学习算法的前沿和局限性。
完整PPT下载:https://sites.google.com/view/icml17deeprl

将
“
神通广大
”
的神经网络模型与简单可扩展的训练算法结合在一起的深度学习对包括计算机视觉,语音识别和自然语言处理在内的一系列监督学习领域产生了巨大的影响。深度网络具备的捕获复杂、高维度功能并学习灵活的分布式表示的能力使得这一成功得以实现。这种能力可以对现实世界的决策和控制问题产生影响,机器不仅能对复杂的感官模式进行分类,还可以选择行动,并解释其长期的影响。
决策和控制问题在更经典的深度学习应用中缺乏相关的监督,并带来了一些挑战,需要新的算法开发来解决。在本教程中,我们将介绍与强化学习相关的强化和最优控制的基础理论,讨论将深度学习扩展到决策和控制中的一些最新成果,包括基于模型的算法,模仿学习和逆向强化学习,探索当前深度强化学习算法的前沿和局限性。

深度强化学习,决策与控制

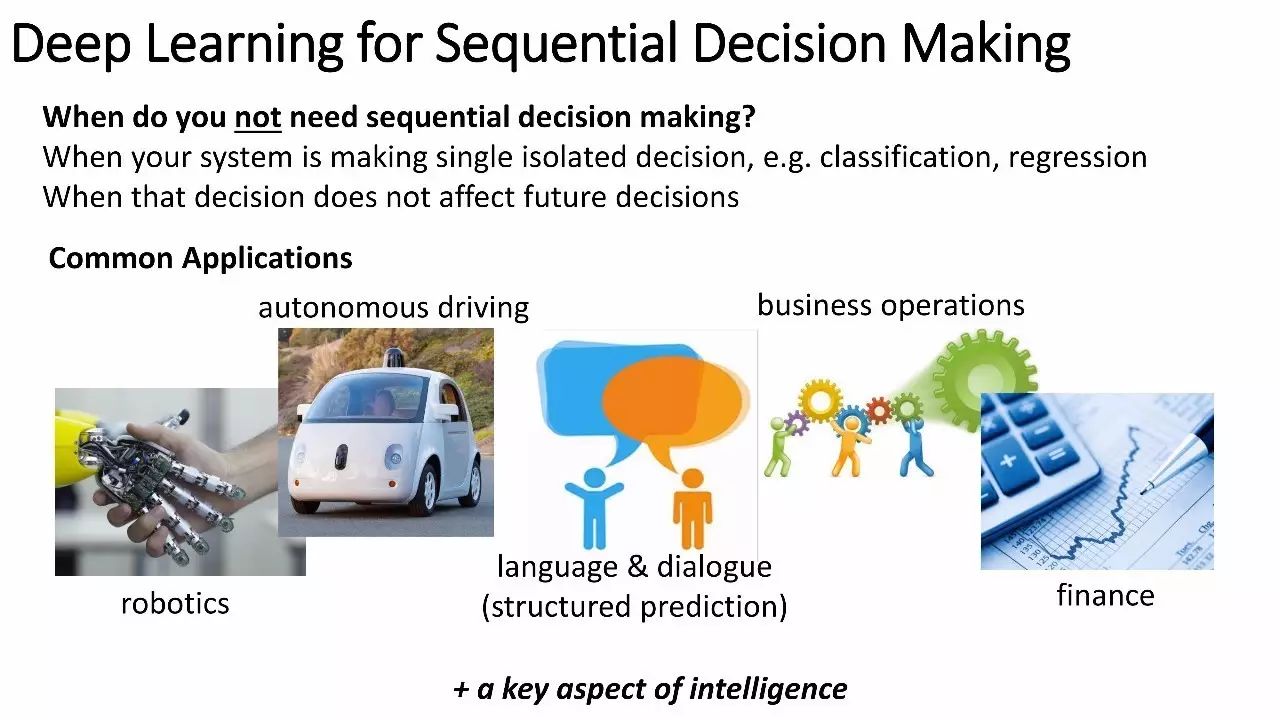
序列决策的深度学习
什么时候不需要顺序决策?
-
当你的系统在做单独的决策时,例如,分类,回归
-
当这个决策不影响未来的决策时
一般的应用
机器人、自动驾驶、语言&对话(结构化预测)、商业运作、金融
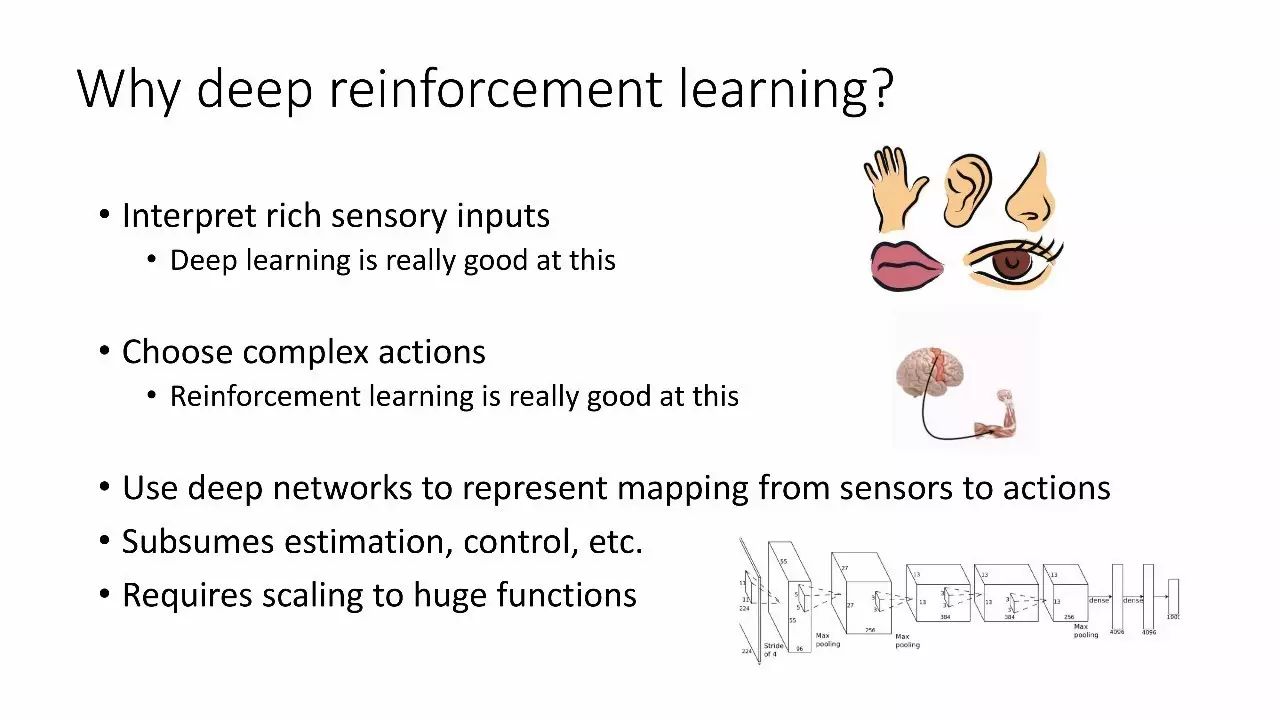
为什么选择深度强化学习?
-
深度学习对于解释丰富的感官输入很好
-
对于选择复杂行动,强化学习很好
-
使用深度网络来表示感官和动作的映射
-
包含预估、控制,等
-
需要扩展到大型的功能
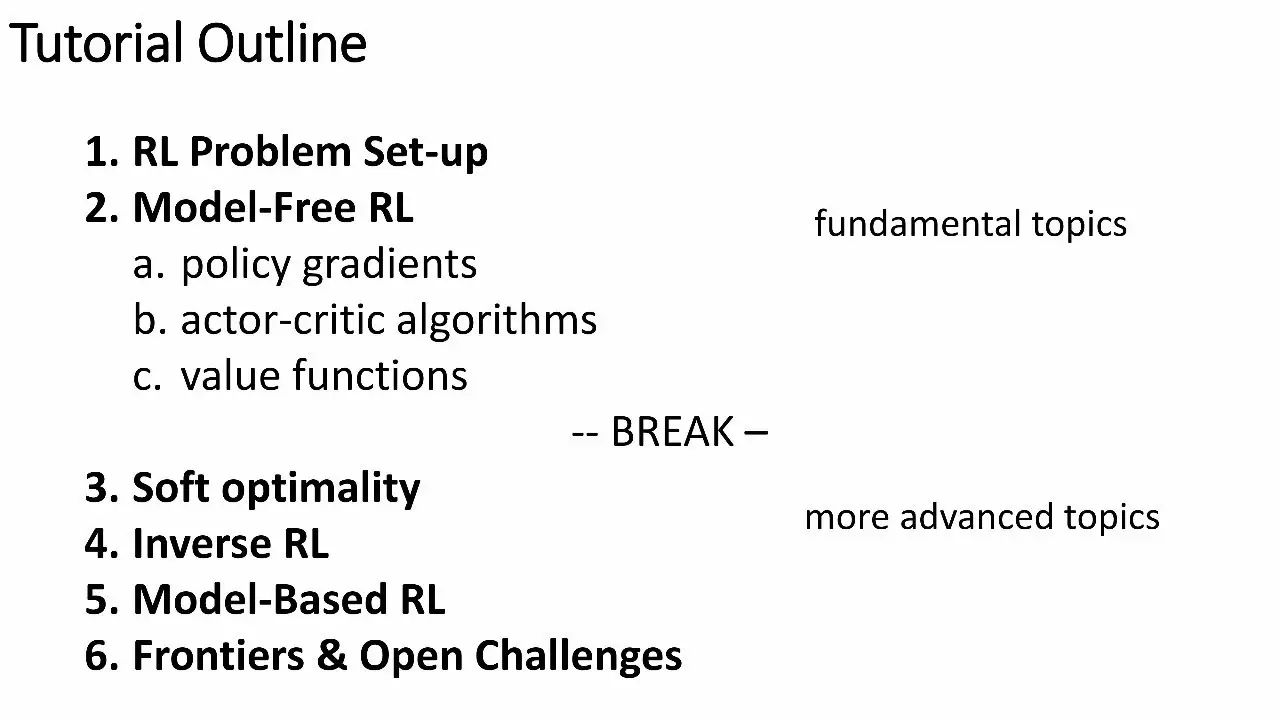
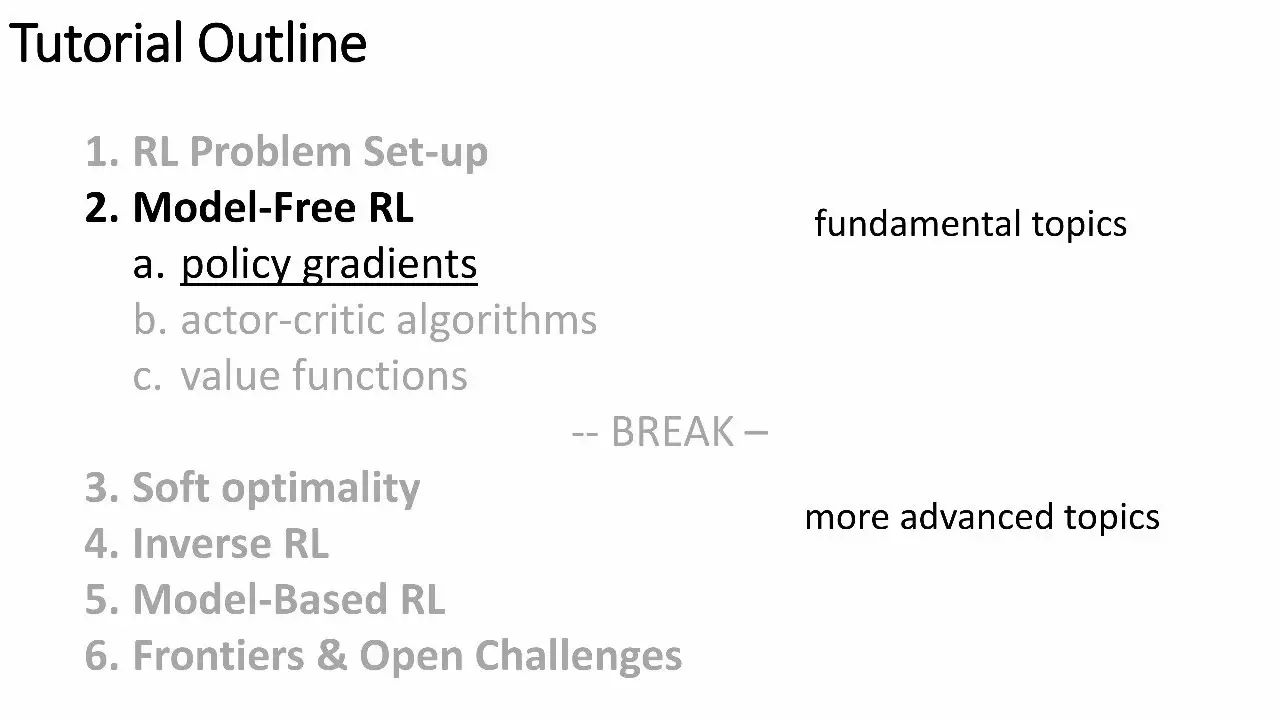
本教程结构:
-
强化学习的问题设置
-
无模型强化学习
策略梯度
actor-critic 算法
价值函数
3. Soft optimality
4. 反向RL
5. 基于模型的RL
6. 前沿与开放性挑战
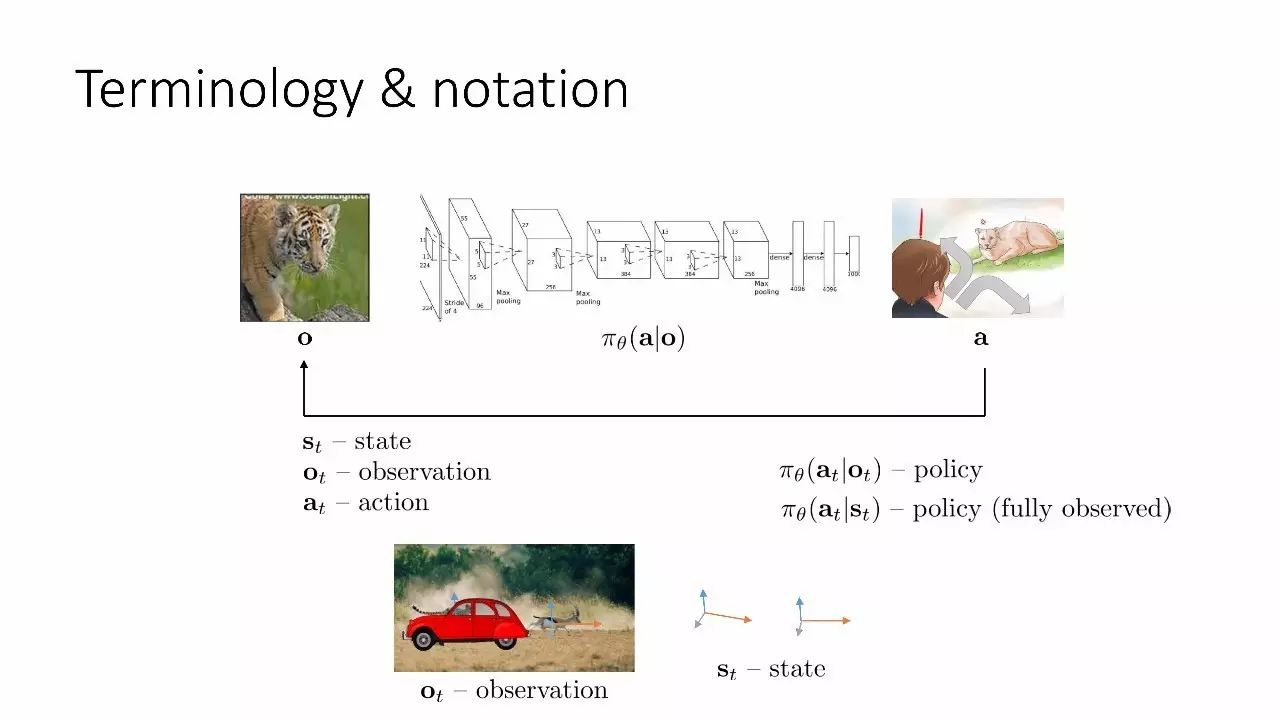
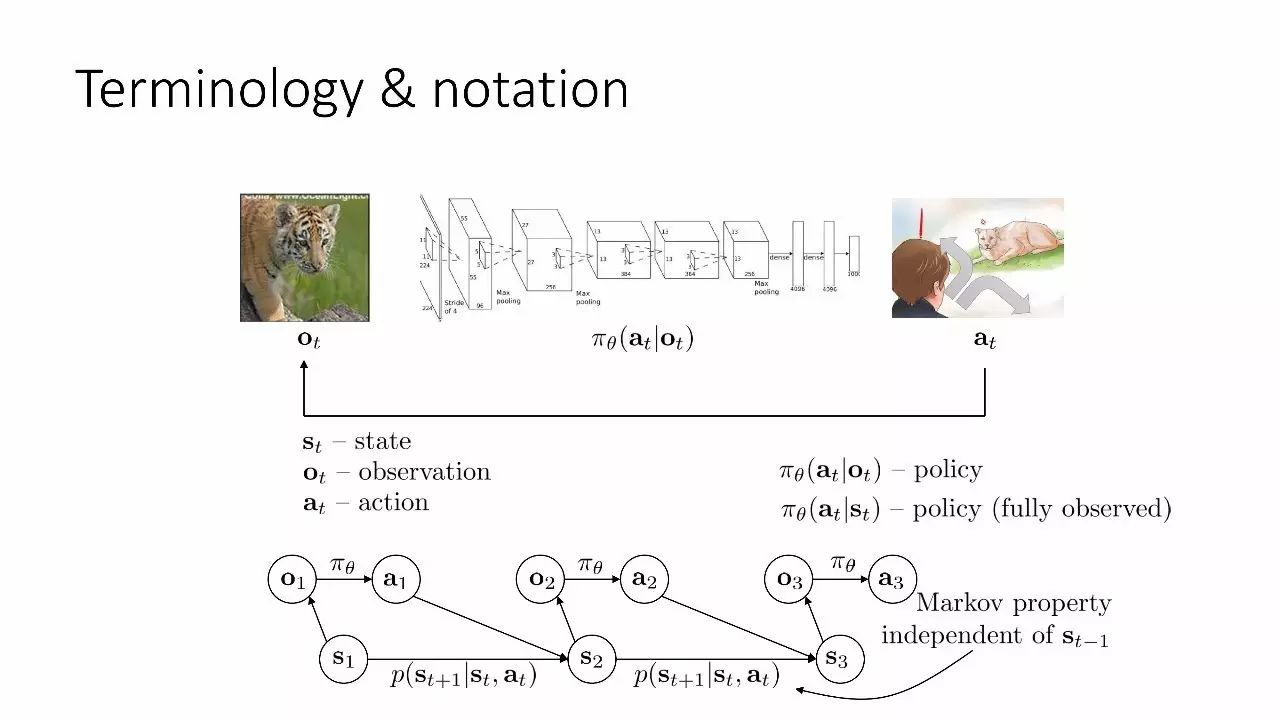
术语和符号
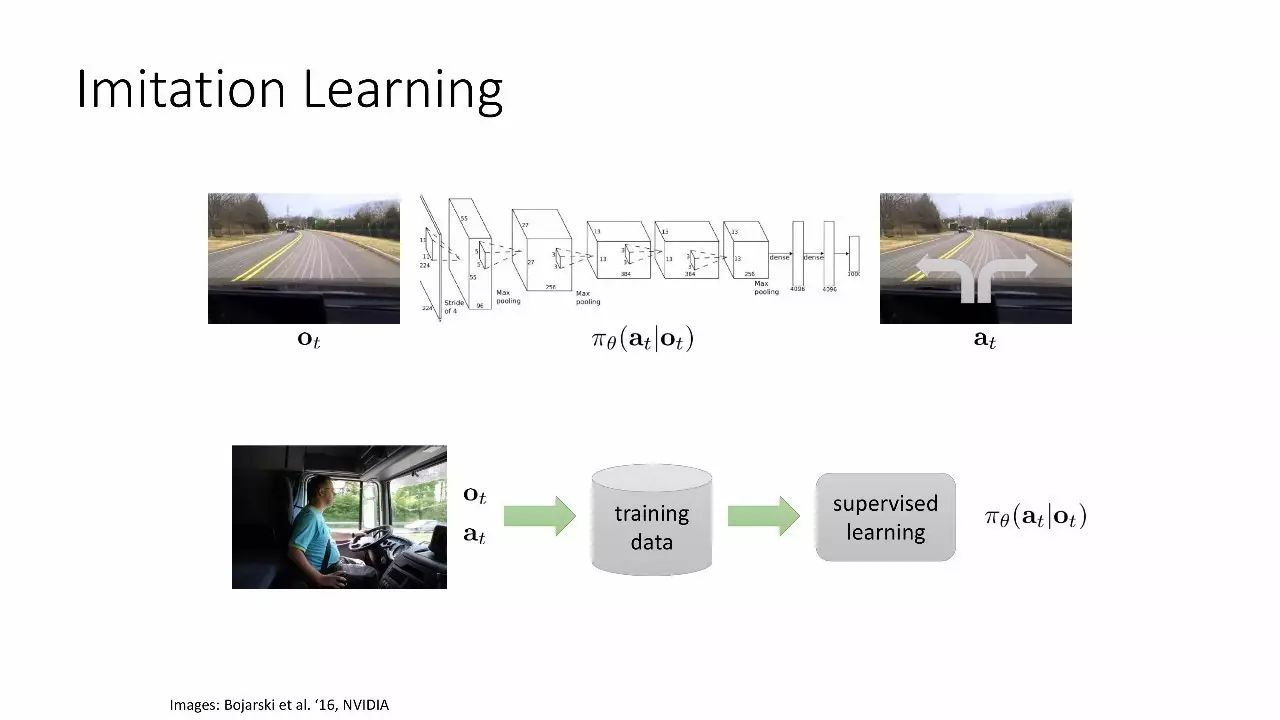
模仿学习

奖励函数
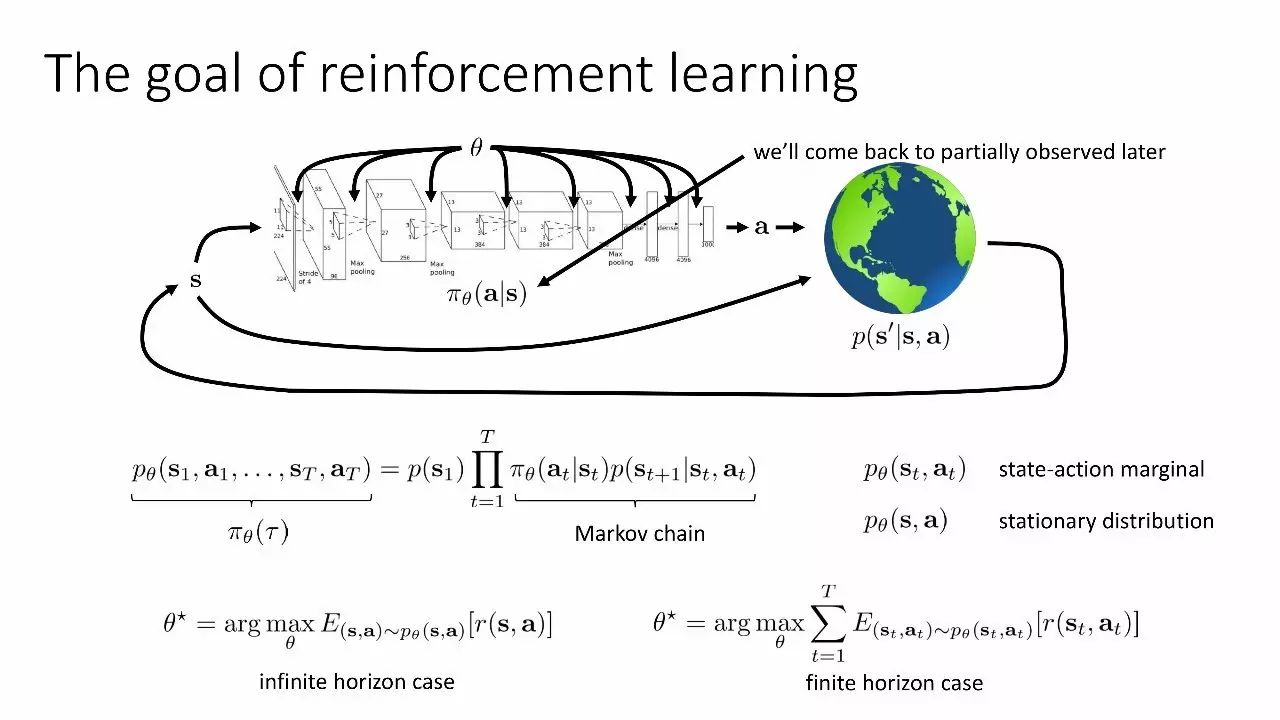

强化学习的目标
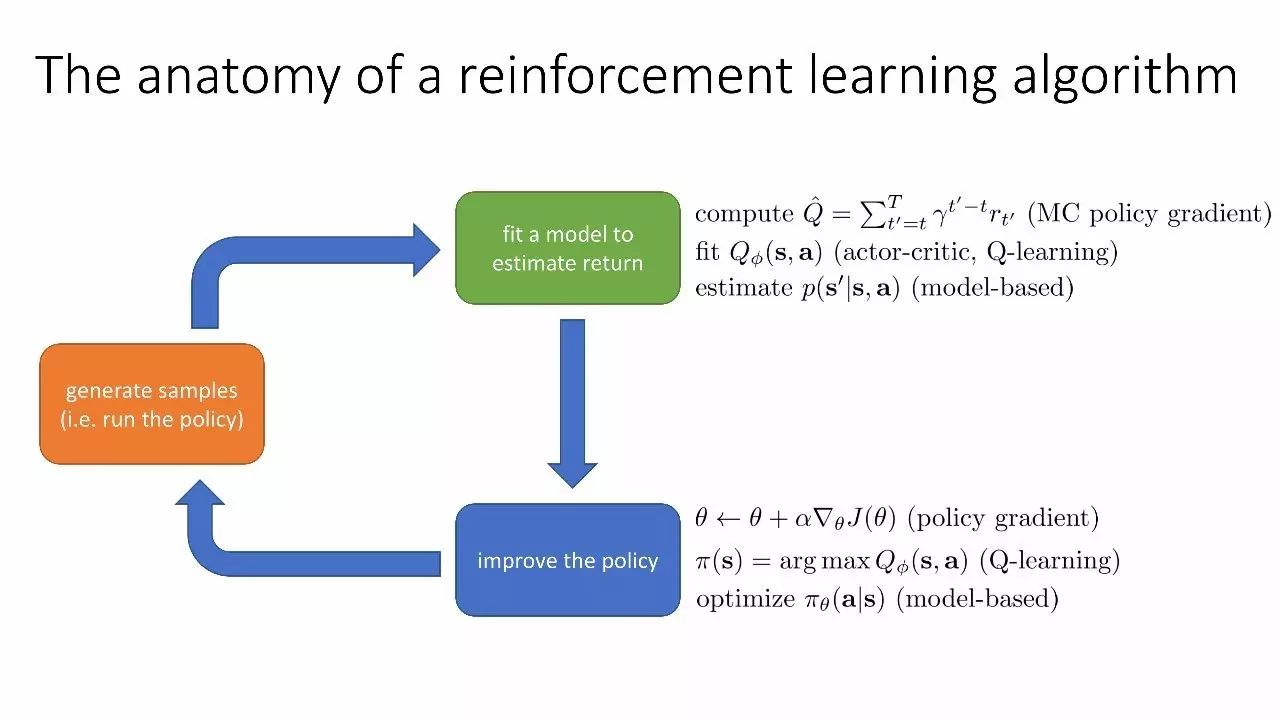
强化学习算法解剖
生成样本(即运行策略)→拟合一个模型来预估回报→改善政策

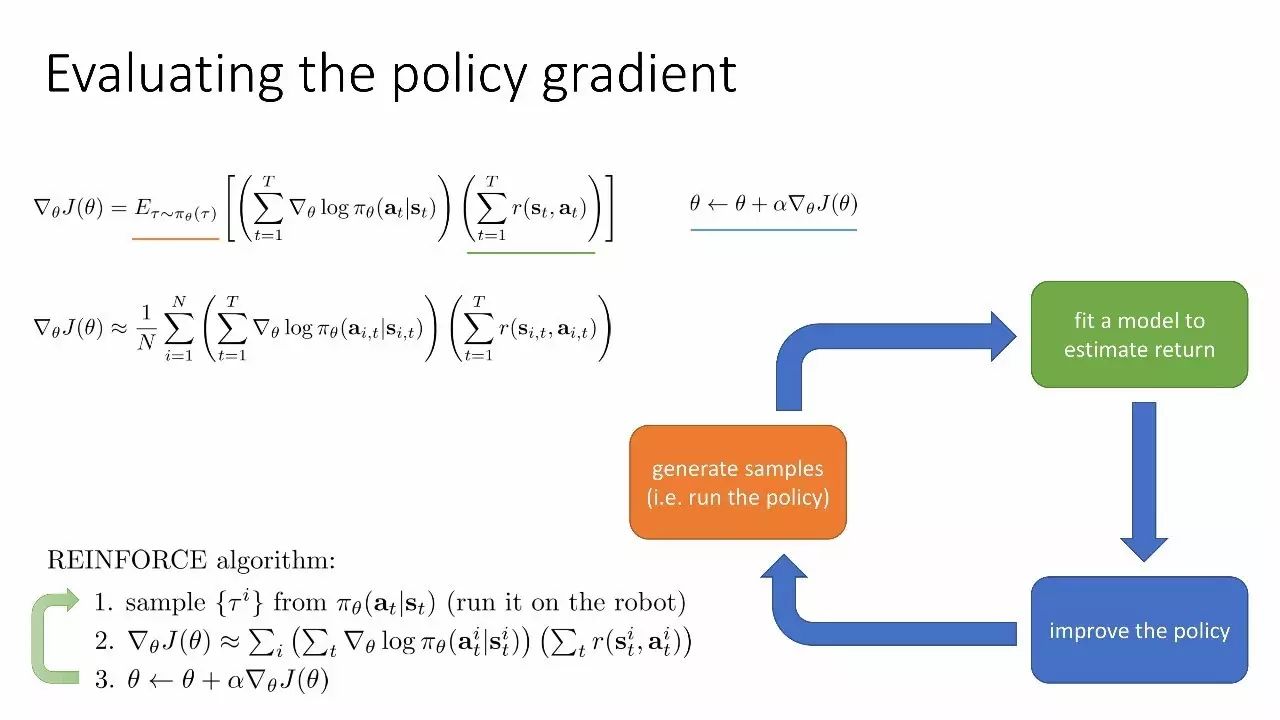


评估策略梯度
 策略梯度存在的问题
策略梯度存在的问题
(上)高方差
(下)慢收敛,难以选择学习率

减小方差

基线
平均奖励不是最好的基线,但相当好了。

控制变量

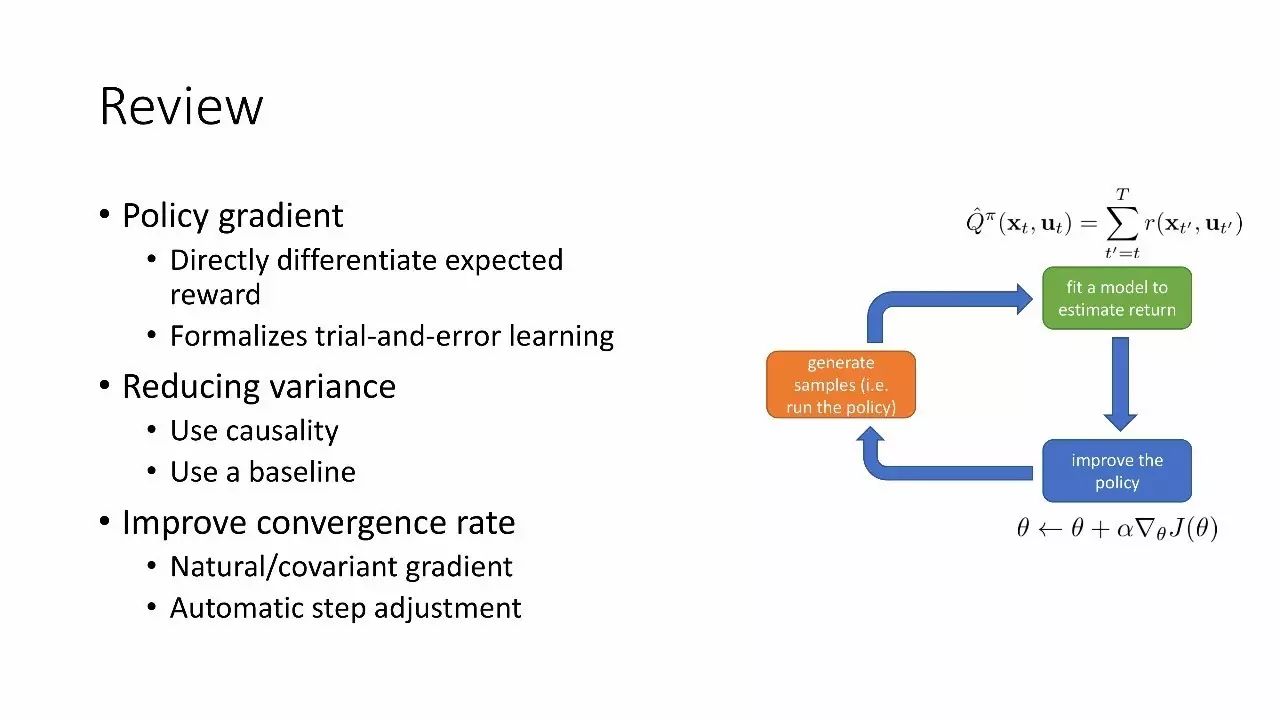
回顾
策略梯度:
直接微分期望奖励
rial-and-error学习
减小方差
使用因果性
使用基线
改善收敛率
自然/协变量梯度
自动步长调整
协变量/自然策略梯度

策略梯度例子:TRPO
-
自然梯度
-
自动步长调整
-
离散行动和连续行动
-
容易使用
-
可编码


策略梯度方面的推荐阅读论文

改善策略评估
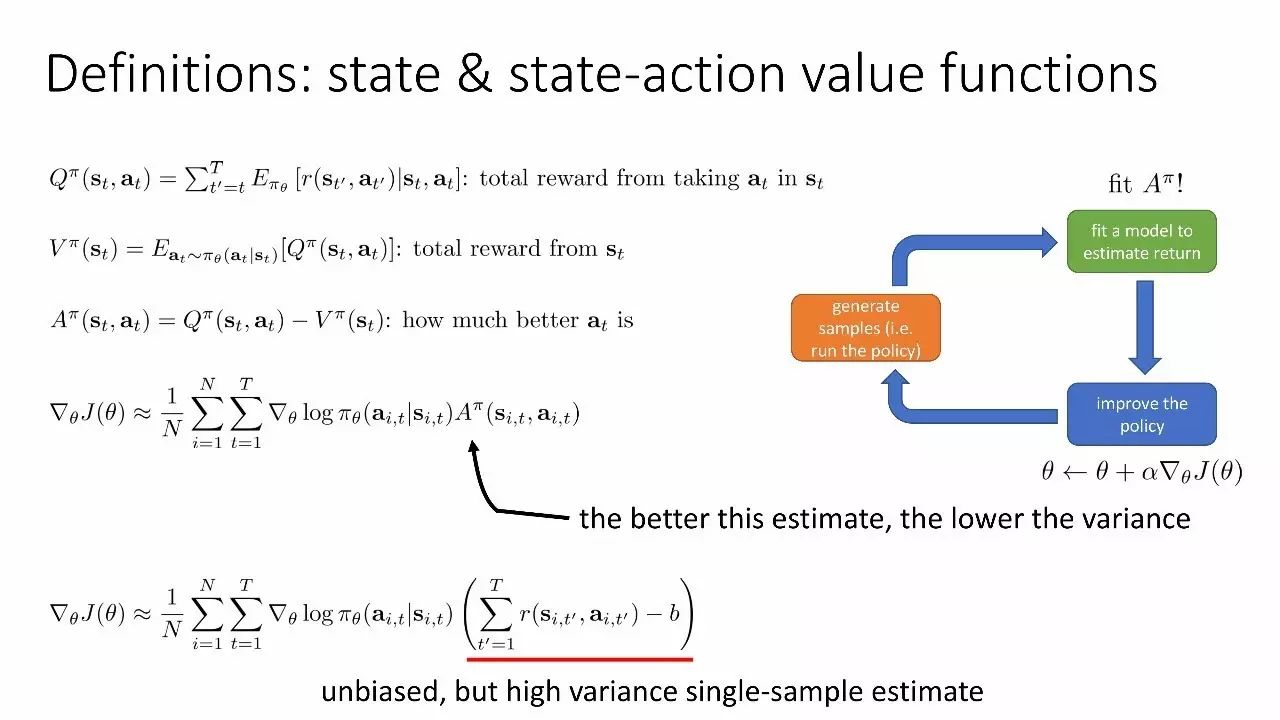
定义:state 价值函数和 state-action 价值函数

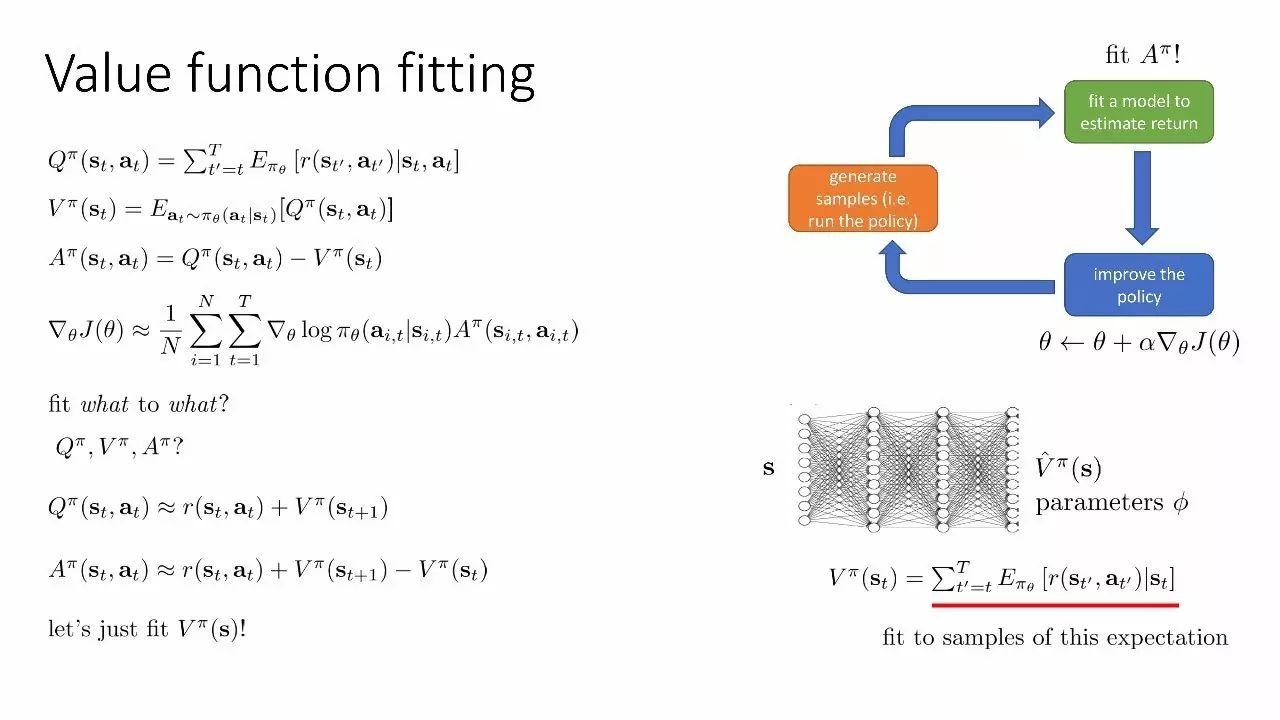
价值函数拟合

batch actor-critic 算法
online actor-critic 算法
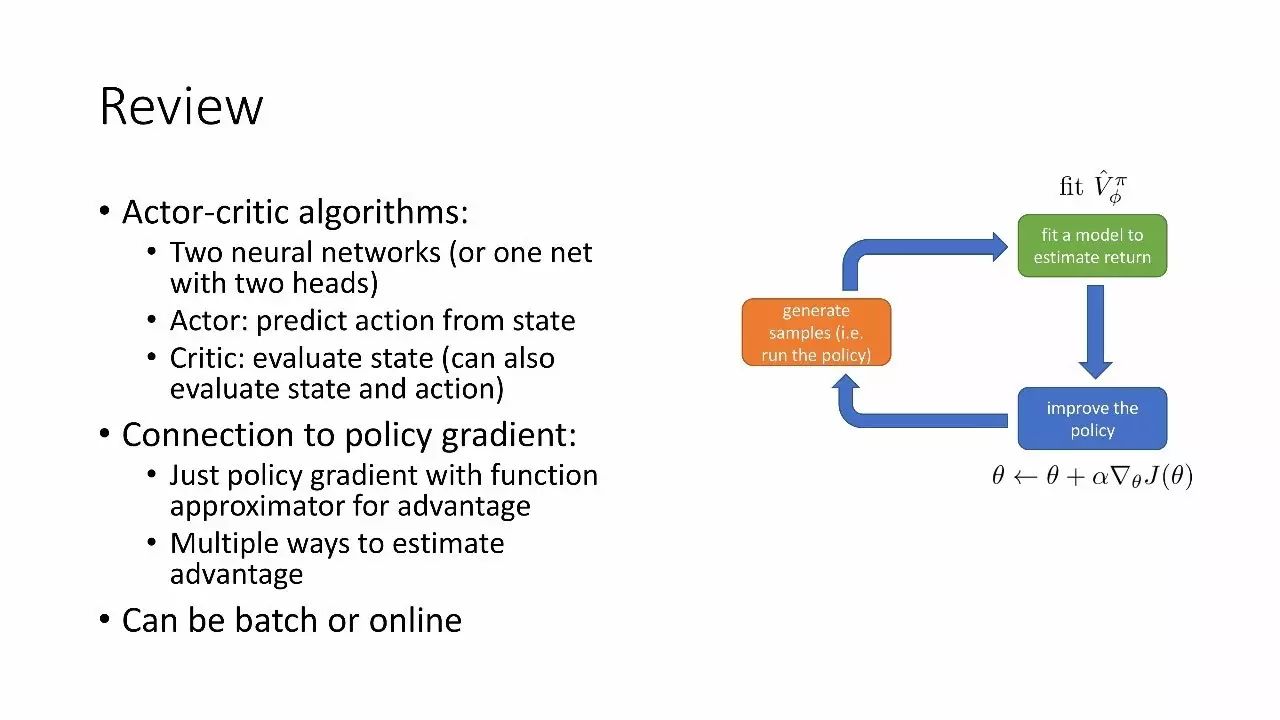
回顾
actor-critic 算法:
两个神经网络
actor:根据state预测行动
critic:评估state(也可评估state和action)
与策略梯度连接
可以是batch,也可以是online

actor-critic 的例子

actor-critic 的推荐阅读论文

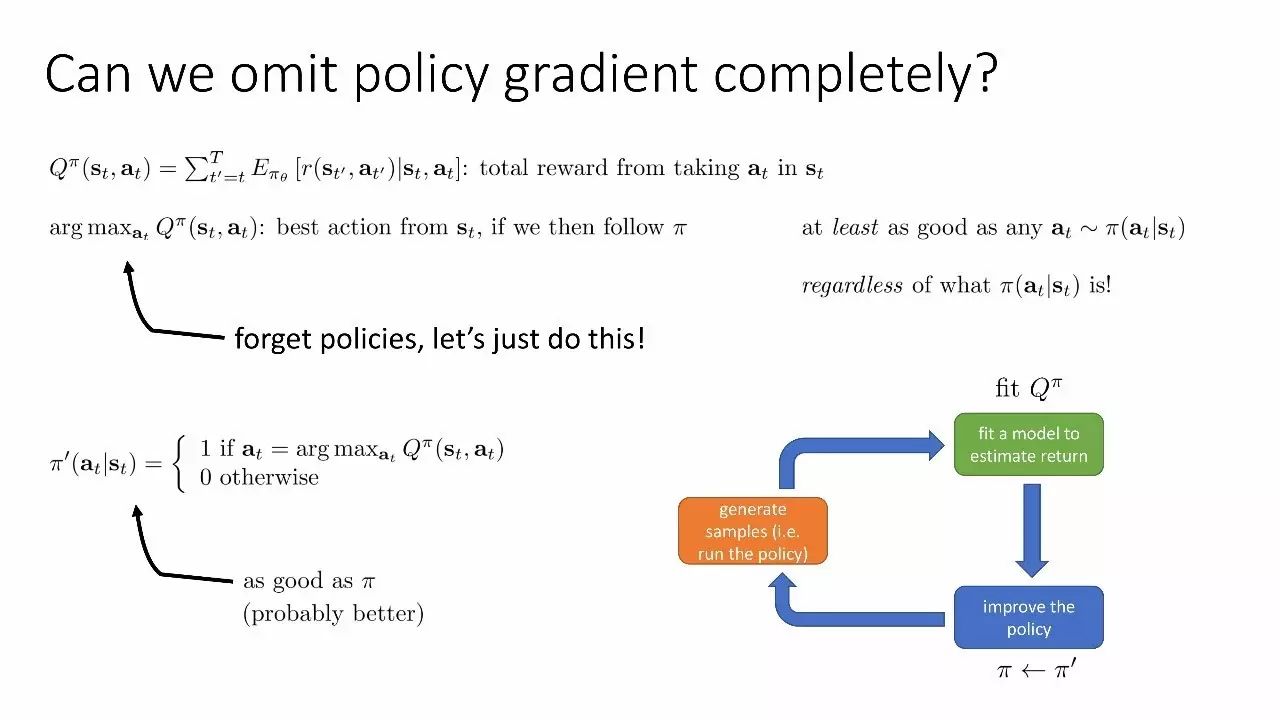
可以完全省略策略梯度吗?

动态规划

Bellman 误差最小化
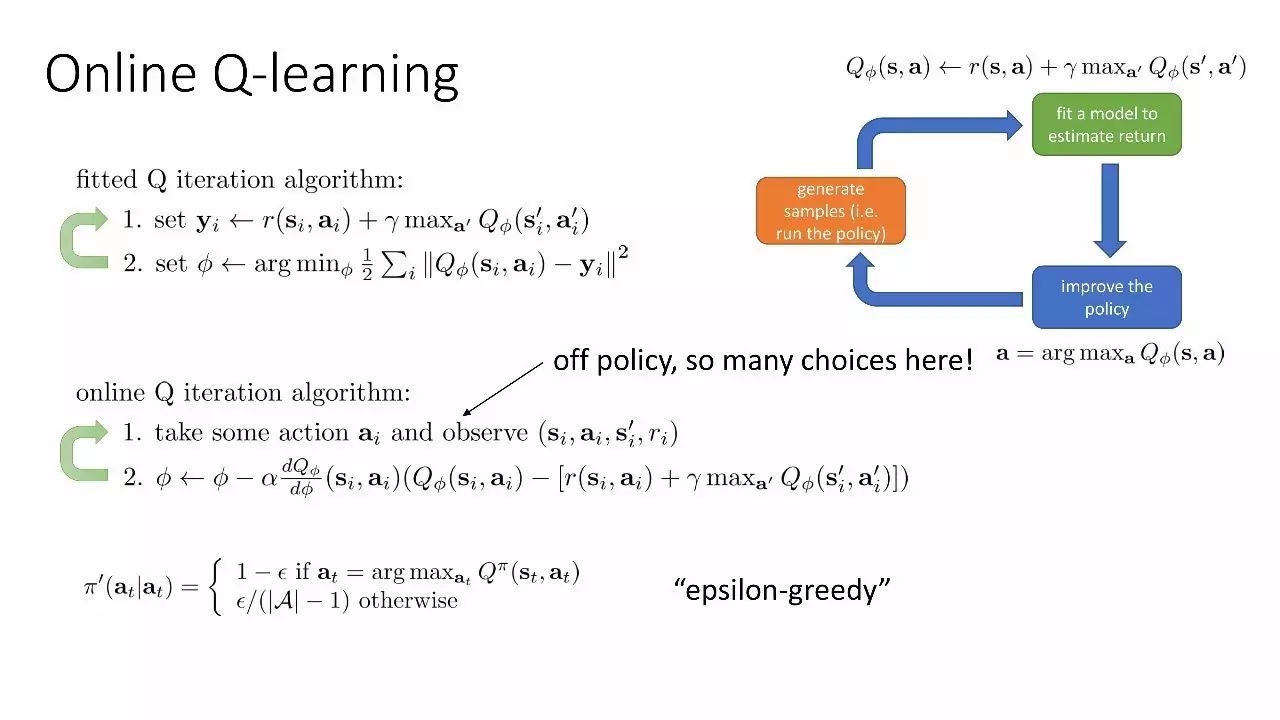
online Q-learning
拟合Q迭代函数

实践Q学习

连续行动的Q学习
选择1:使用容易优化的函数类别
选择2:学习一个近似最大值
DDPG (Lillicrap et al., ICLR 2016)
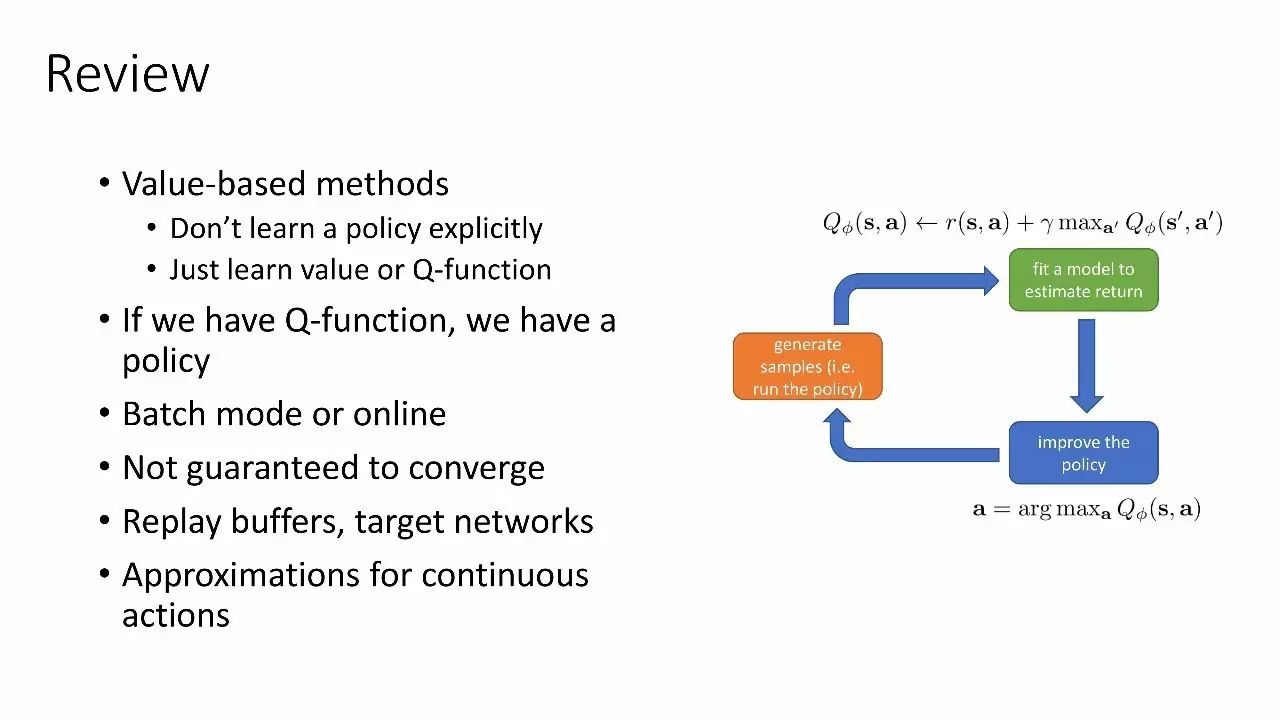
回顾
-
基于价值的方法
-
不要显式地学习一个策略
-
学习价值或Q函数
-
假如有了Q函数,就有了策略
-
batch模式或online模式
-
对收敛没有保证

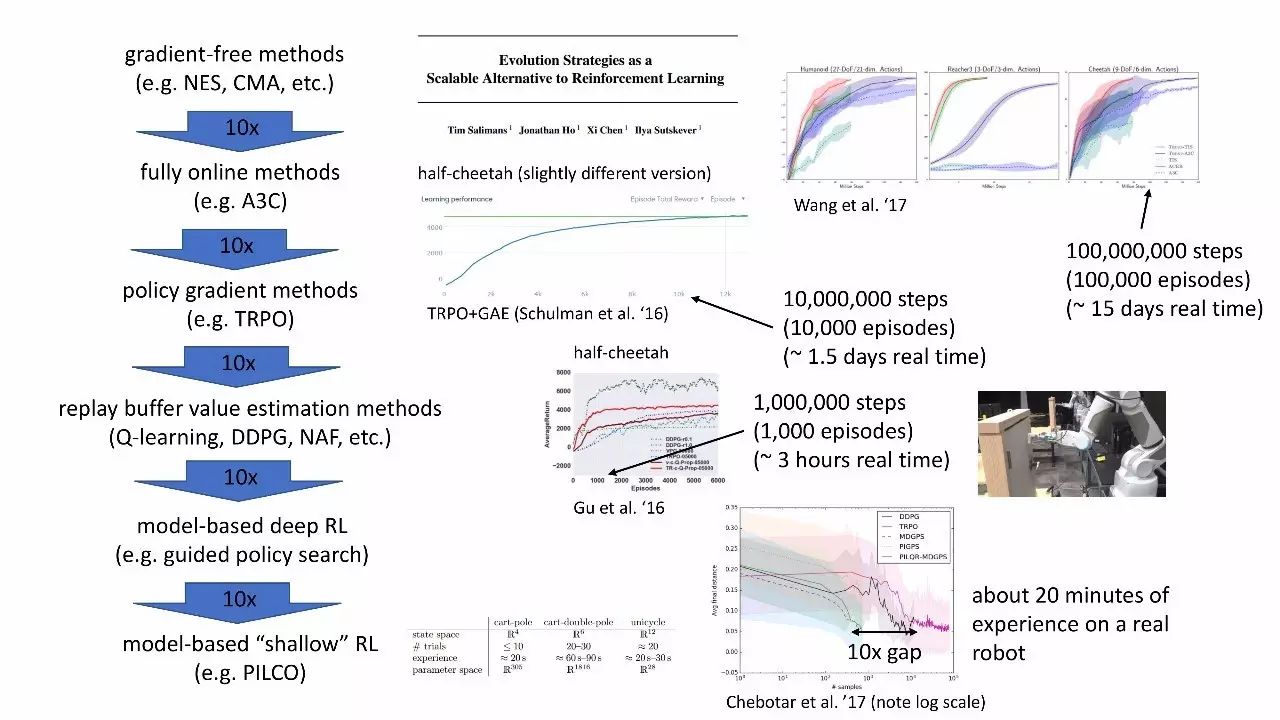
Q-learning的例子

Q-learning方面推荐阅读的论文
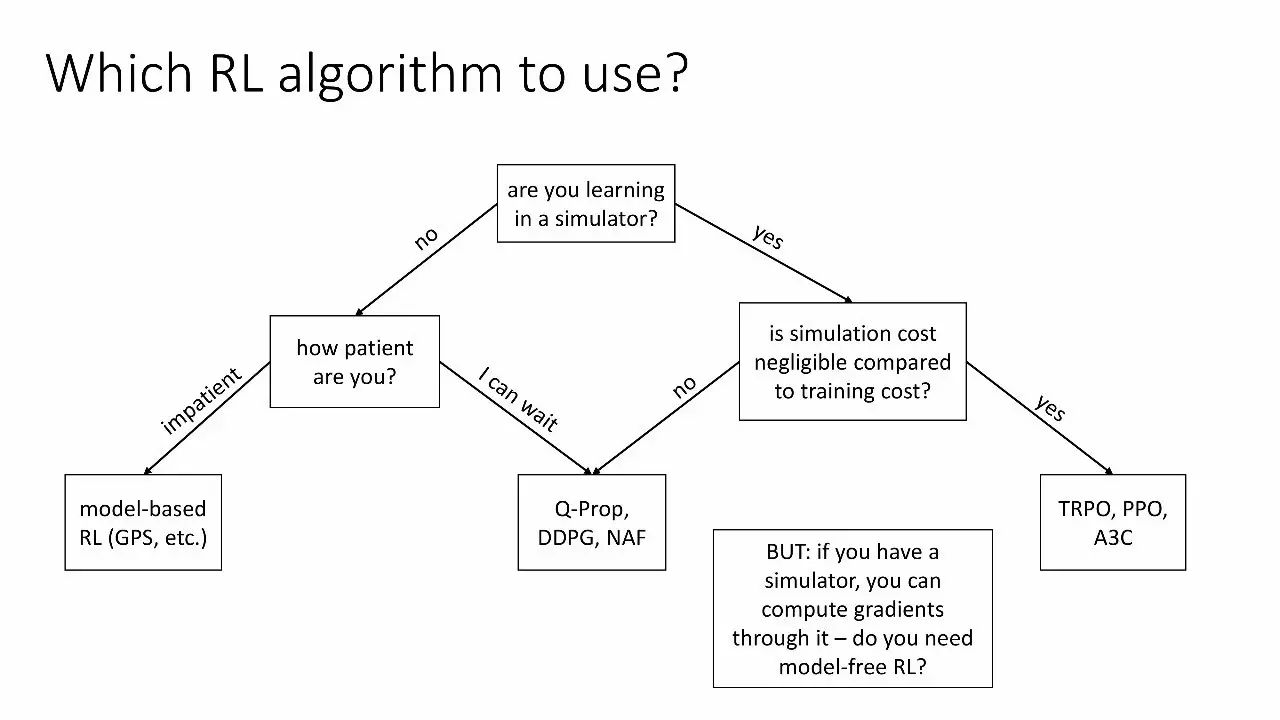
使用哪个RL算法?
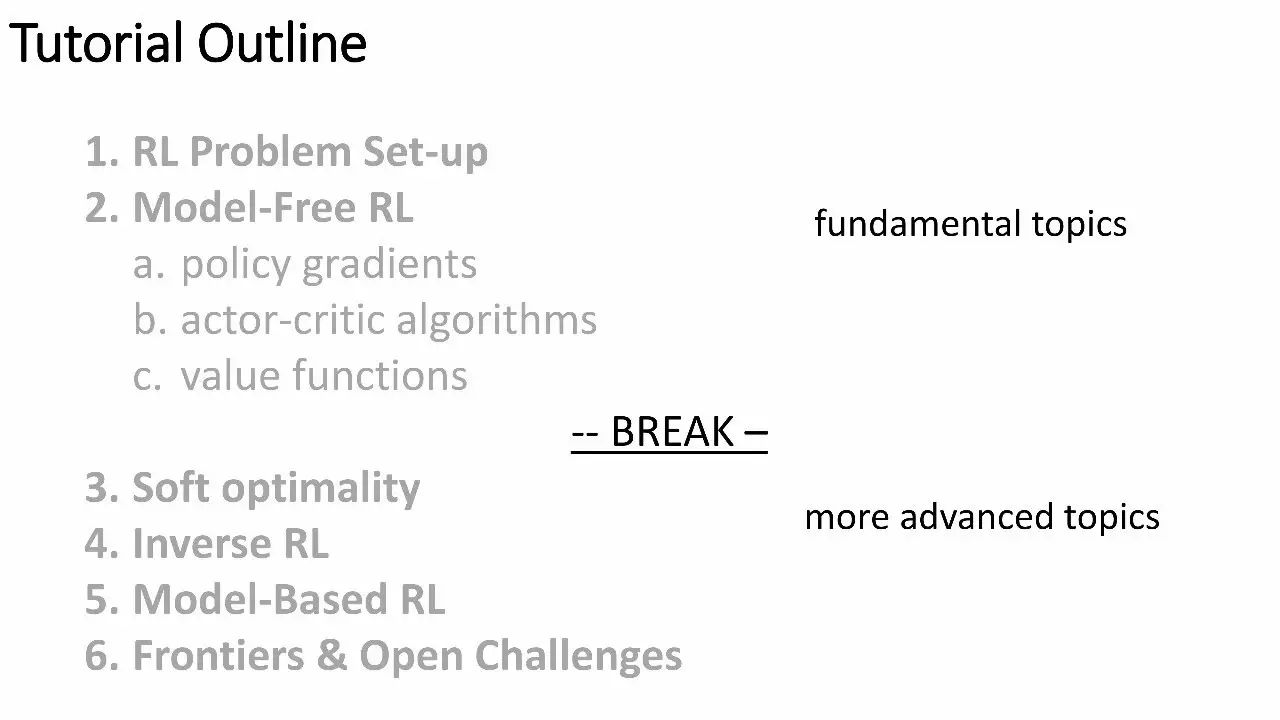
以下属于更高级的主题,包括 Soft optimality、反向RL、基于模型的RL、以及更多开放性挑战
完整ppt下载地址:https://sites.google.com/view/icml17deeprl
【号外】
新智元正在进行新一轮招聘,
飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~






