
版权声明:本文内容来自快科技,如您觉得不合适,请与我们联系,谢谢。
然消费级的芯片仍是Intel、NVIDIA等公司的核心业务之一,但其实真正的“摇钱树”还要数企业级、工业级的产品,比如加速卡、服务器计算方案等,况且还是展示实力的炫技良机。去年,Intel和NVIDIA还因为“深度计算”某些指标到底谁强公开对掐,令人侧目。
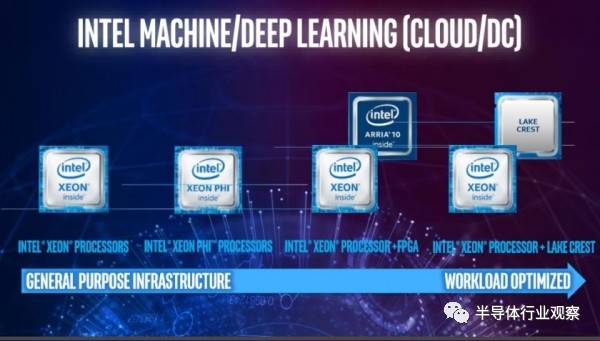
近日,Intel展示了旗下用于深度神经网络计算(Deep Neural Network,DNN)的Lake Crest家族新芯的进展,基于Nervana平台打造,宣称可以在同样晶体管密度的情况下提供比GPU更强大的性能。

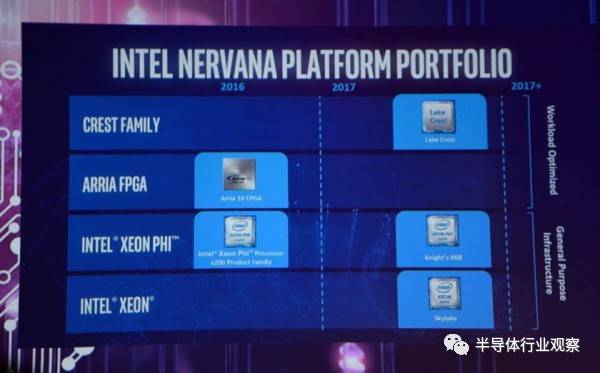
据悉,Intel从2016年8月开始,投入了3.5亿美元研发服务于DNN的Nervana软硬件一体化平台,目前包括Lake Crest家族和下一代Knights Crest,前者是定于今年上半年发布的独立加速卡,它们应该都会以ARRIA FPGA的形式利用,匹配Xeon处理器。
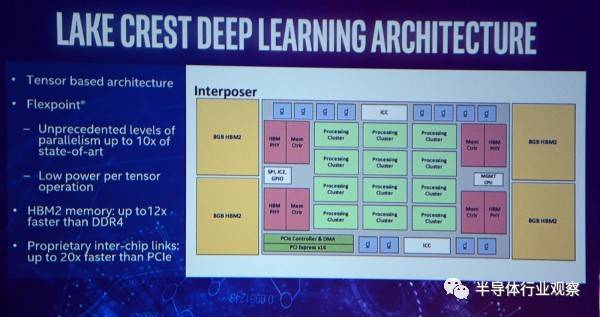
不同于市面现行的Xeon Phi,Lake Crest专为AI负载设计。Intel称自己使用了Flexpoint架构,MCM多芯片封装,搭载32GB HBM2存储,内部互联速度是PCIe的20倍,浮点运算性能8TFLOPS。
路线图显示,Intel应该会在今年发布Knights Mill (Xeon Phi) 和Xeon E5 V5 Skylake处理器时宣布Lake Crest的登场。
要说遗憾,可能不得不提因为禁售令,Intel的加速产品无法进入中国。



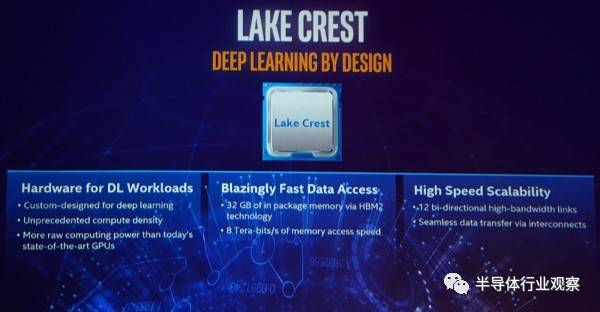
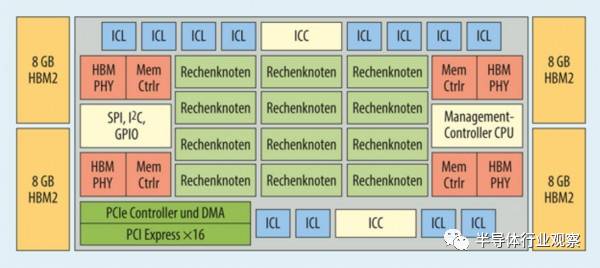
12个运行核心

【关于转载】:转载仅限全文转载并完整保留文章标题及内容,不得删改、添加内容绕开原创保护,且文章开头必须注明:转自“半导体行业观察icbank”微信公众号。谢谢合作!
 【关于投稿】:欢迎半导体精英投稿,一经录用将署名刊登,红包重谢!来稿邮件请在标题标明“投稿”,并在稿件中注明姓名、电话、单位和职务。欢迎添加我的个人微信号MooreRen001或发邮件到 [email protected]
【关于投稿】:欢迎半导体精英投稿,一经录用将署名刊登,红包重谢!来稿邮件请在标题标明“投稿”,并在稿件中注明姓名、电话、单位和职务。欢迎添加我的个人微信号MooreRen001或发邮件到 [email protected]

点击阅读原文加入摩尔精英




