来源:theregister.co.uk
作者:Cheryl Everitt
译者:刘小芹
【新智元导读】本文用一个机器学习评估客户风险水平的案例,从准备数据到测试模型,详解了如何随机森林模型实现目标。

机器学习模型可用于提高效率,识别风险或发现新的机会,并在许多不同领域得到应用。它们可以预测一个确定的值(e.g.下周的销售额),或预测分组,例如在风险投资组合中,预测客户是高风险,中等风险还是低风险。
值得注意的是,机器学习不是在所有问题上都工作得非常好。如果模式是新的,模型以前没有见过很多次,或者没有足够的数据,机器学习模型的表现就不会很好。此外,机器学习虽然可以支持各种用例,但仍然需要人类的验证、感觉检查和专门领域知识。
话虽如此,我们可以通过解决上述用例之一来看看机器学习可以实现哪些目标。让我们通过机器学习技术的一个基本应用,看看将一组客户数据转变为风险水平评估这个预测涉及了哪些过程。
我们可以使用分类模型——预测每个项分别属于哪个类或组。可以很好地实现这个任务的一类算法是随机森林。这种类型的模型是基于决策树,即一种使用不同的变量(有关客户的信息)来分割一组对象(在这个用例中是客户),并继续分割,直到每个对象都被放置到特定的类别。随机森林是这样的决策树的集合。使用多个树可以降低过拟合(模型对于第一组特定的训练数据集工作得非常好,但对后续数据集工作不好)的风险。
创造像这样复杂的模型似乎令人望而生畏。但好消息是,许多语言都有预构建这种类型的模型的库。在这个用例下,我使用的是python库scikit-learn(以及用于管理数据集的pandas和numpy库)。
在继续之前,请确保你已经安装了Python(我使用的是Python2),并且在上面提到的3个包装中加载。这个可以在终端做,用pip安装pandas(numpy和sklearn也是一样)。
下面的示例都使用 Jupyter Notebook,这是数据科学家很常用的工具。相同的代码段直接在Python控制台或其他任何Python IDE中工作。
导入的语句使库对当前的段可用。然后,继续将数据从csv文件加载到dataframe(这是pandas使用的特定格式的数据结构),然后添加标题名字。

现在,数据保存在 pandas 的 dataframe(df),如下图所示,选择前5行作为样本。
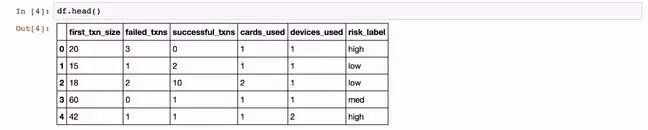
为了让模型进行预测,需要“训练”。也就是说,模型被显示一组已经具有相关分类的数据。从这些数据,模型可以了解有关数据主体(在这个case是客户)本身的信息与它的标签(高风险、中风险、低风险)之间的关系。
在随机森林模型的情况下,是通过数据集特征来对数据进行划分或分割,从而找到相关性。例如,根据“使用的设备数量”来进行划分,可以把使用一个设备的和使用两个设备的分成两组(根据数据集的基数,可能有两个以上的组)。进一步的分类要使用不同的信息,直到可以将所有记录划分到最终的类别(在这个case是风险级别)。
模型训练好之后,使用模型未遇见过的其他数据对其进行测试。新的数据已经没有原始标签,要求模型自己去预测值。
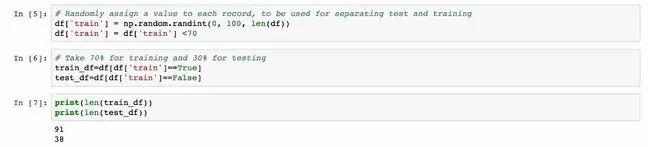
为了实现这一点,数据集需要分成两部分。一部分用于训练,另一部分用于测试。下面的代码段为每个观察值随机分配1到100之间的值,并将分配到低于70的随机数的那些行分到训练集,其余的作为测试集。因此,大约70%的数据用于训练。在每个数据集print一个值,可以显示这是有效的。
现在,应该为这个模型准备好训练集。创建一个变量来保存对特征(有助于确定最终类别的信息)的引用和另一个变量来保存类别本身。
首先,为类别创建变量。下面示例中的变量 train_labels 保存了数据集中的risk_label 列的内容。这些是风险级别的“高”,“中”或“低”,但是使用“因数分解”函数转变为数字(0, 1, 2)。
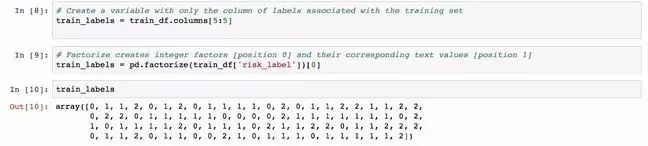
接下来,特征的名称被捕捉到一个单独的变量中,即下面示例的columns_for_features。同时,随机森林分类器被创建并存储在名为classifier 的变量中。
现在,训练模型的一切都准备好了。分类器有一个函数 fit,通过训练数据集(train_df)被告知要注意的行,以及训练标签,或已经可用的类别。
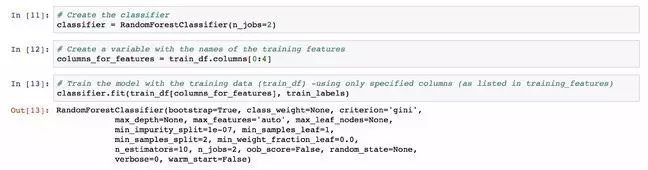
所以现在模型可以训练了。它将会确定“features”与“labels”之间的关系,并且只有当features可用时才能确定数据未知的label。
使用测试数据集,可以测试模型的执行性能。分类器有一个叫做predict的函数,它从前面准备的test_df数据集传递特征数据。它的输出是一组整数(0, 1, 2),分别表示标签('high','med','low'),即模型预测出的类别。

这很令人兴奋,但意义不是很大。几个快速步骤可以将值解码回文本标签,然后将模型得出的类别与测试数据集中的原始标签进行比较。

下面的表格显示了每个真实的组与预测组的比较。这里显示的是,对于高风险的10个观察值,该模型预测其中9个是高风险,1个是中等风险。对于18个的低风险的观察值,该模型的预测完全一致。对于最后10个中等风险的观察值,模型的预测有7项正确,另外3项被错误地预测为高风险。

这是一个不错的结果。几个小步骤,我们就能够创建一个模型,训练它识别数据中的模式,并基于这些训练,模型能够预测新数据的类别。这意味着,你的公司可能不再需要人去人工审查所有的客户资料,你可以简化过程并只关注高风险客户。
在这个case中,分类器预测的是风险水平。同样的技术也可以应用于预测客户流失,机器故障以及其他各种业务问题。
在实际应用中,这个过程要花更多的时间,但这是理解机器学习的基本原理和关键步骤的很好的第一步。
此外,使用预先准备好的数据集有很大好处。在大多数情况下,要做大量的工作将数据变为易于建模的形式之后,机器学习的荣耀才会显现。这些工作包括数据清洗,特征选择,转换和格式化等。
原文:https://www.theregister.co.uk/2017/06/21/15_minutes_in_machine_learning/

点击阅读原文查看新智元招聘信息









