
糖豆贴心提醒,本文阅读时间8分钟
最近在读Python源码中有关内存管理的部分。Python在分配小块内存(小于256字节)时,采用了内存池,以降低对内核内存分配程序的调用频次。在内存池的设计上,采用了一个分层的设计,由上到下依次是arena、pool、block。这次我看到的这个比较费解的结构,就来自于分配内存时,对于pool的处理。
谜团
在最主要的分配内存的函数_PyObject_Alloc中,我看到了这么一段代码:

从注释和函数命名中也能看出来,这段代码的意思,大概是从arena的freepools中拿出一个pool,插入到usedpools的开头。但是,这里有一个奇怪的地方:
如果说usedpools中存储的不同size的pool链表,那么为什么index要用size+size来表示呢?
初探
首先,我在代码中搜索了一下usedpools,找到了这么一段注释:
This is involved. For an index i, usedpools[i+i] is the header for a list of
all partially used pools holding small blocks with “size class idx” i. So
usedpools[0] corresponds to blocks of size 8, usedpools[2] to blocks of size
16, and so on: index 2*i blocks of size (i+1)<
哦,就是说,我要找到保存8字节block的pool,就去usedpools[0+0];找16字节的pool,就去usedpools[1+1]。再看一下上面代码中的size的由来:

果然可以和注释里写的对应起来(注意,注释里的2*i是usedpools的index,而这里的nbytes是实际需要分配的block的字节大小,所以一个需要左移位,一个需要右移位,互相转换)。
但是目前为止,好像处在一个“知其然,而不知其所以然”的状态:这里没有解释为什么是这样一个奇葩的size+size的index。
深入
往下,又有一段注释(Python源码的注释真详细):
Major obscurity: While the usedpools vector is declared to have poolp
entries, it doesn’t really. It really contains two pointers per (conceptual)
poolp entry, the nextpool and prevpool members of a pool_header. The
excruciating initialization code below fools C so that
usedpool[i+i]
“acts like” a genuine poolp, but only so long as you only reference its
nextpool and prevpool members. The “- 2 sizeof(block )” gibberish is
compensating for that a pool_header’s nextpool and prevpool members
immediately follow a pool_header’s first two members:
union { block *_padding;
uint count; } ref;
block *freeblock;
each of which consume sizeof(block
) bytes. So what usedpools[i+i] really
if* C believes it’s a poolp
pointer, then p->nextpool and p->prevpool are both p (meaning that the headed circular list is empty).
这一大段注释说了什么呢?大意就是,你以为usedpools里放的是poolp类型?其实里面是两两一对的poolp,一个是nextpool指针,一个是prevpool指针。这里还使用了一些trick,让C语言认为usedpools里放的是pool_header变量,只要使用者能保证只使用它的nextpool、prevpool成员。
直接看usedpools的定义吧:

展开宏定义:

而PTA(x)定义为,usedpools[2x]的地址减去2个block*长度的地址。结合pool_header的定义:

nextpool和pool_header的地址之间,正好差了2个block*的偏移量。所以,在初始化usedpools之后,当把usedpools[size+size]当作pool_header时,那么usedpools[size+size]->nextpool将正好取到usedpools[size+size]的地址,也就是指向usedpools[size+size];而usedpools[size+size]->prevpool将也正好取到usedpools[size+size]的地址。因此:

这段代码+注释就说得通了。
然后,经过:
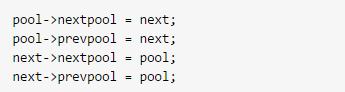
这么一折腾,usedpools中存储的一对地址(nextpool, prevpool)就指向了真正的pool_header变量pool。
知其所以然
但是,为什么要这么绕的设计这样的usedpools结构呢,直接存储一个完整的pool_header不简单明了吗?下面这段注释给出了答案:
It’s unclear why the usedpools setup is so convoluted. It could be to
minimize the amount of cache required to hold this heavily-referenced table
(which only needs the two interpool pointer members of a pool_header).
就是说,这样的一个usedpools表,会经常的被使用,使用这种结构,就可以减少放入缓存中的数据量(毕竟,我们只需要放入两个指针,而不是整个pool_header),从而也就提高了缓存的效率。为了提高效率,还真是无所不用其极啊。
到这里,obmalloc.c中我认为最费解的一个数据结构,就弄清楚啦。






