这是Pascal Vincent在2015年深度学习夏季学校讲的机器学习入门。浅显易懂,值得一读。

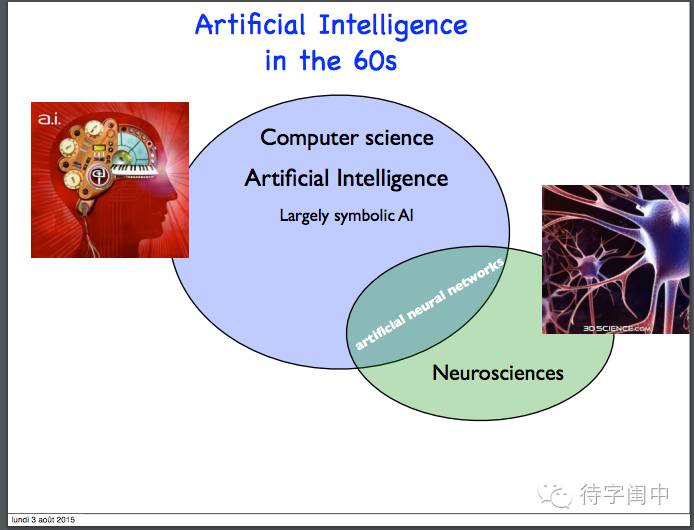
AI的两种不同的思路:神经元网络和符号主义。最后是学习和概率模型获胜,从而催生了机器学习。

60年代的AI。
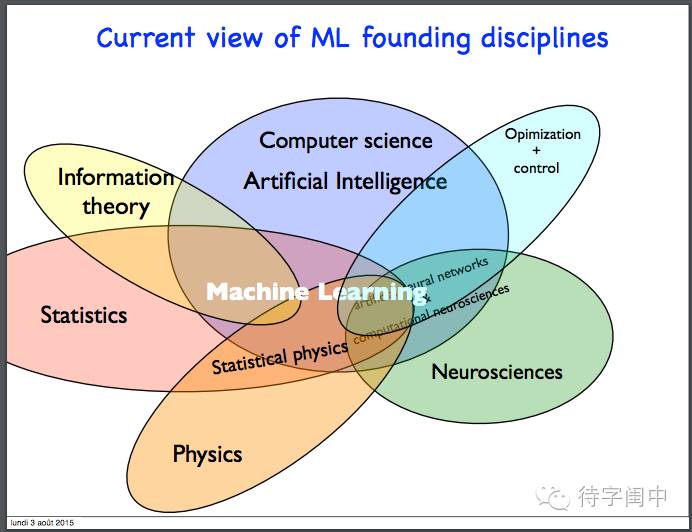
现在的机器学习是跨学科综合体。
机器学习:研究基本原理,开发神奇算法,利用收集的数据生成预测函数,能够应用到新的相似数据上。

机器学习的主要材料是数据!数据表示成很多的同质的样本,最好每个样本表示成一个数字向量。

数据预处理,提取体征,表示成向量,和目标值。
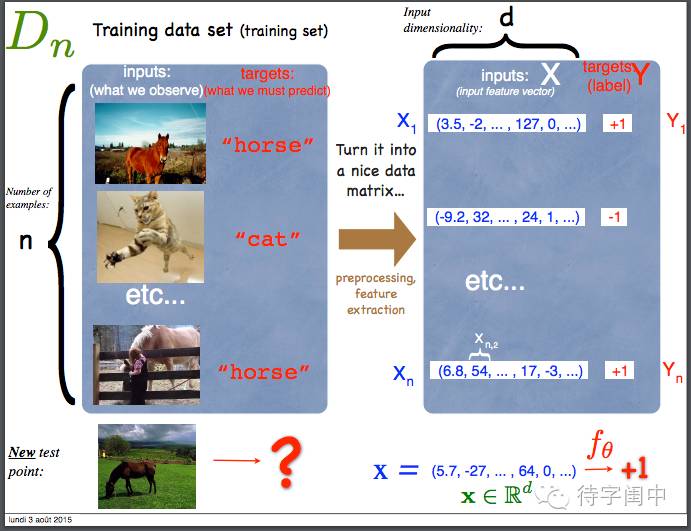
问题空间:样本大小n,特征维度d,目标维度m。

将数据变成一系列样本。一个样本需要保存哪些信息,需要预测什么。

将样本转换成一个输入向量。
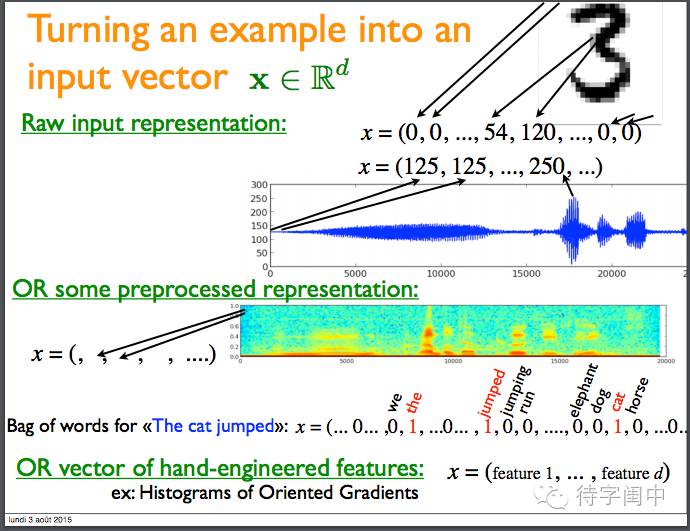
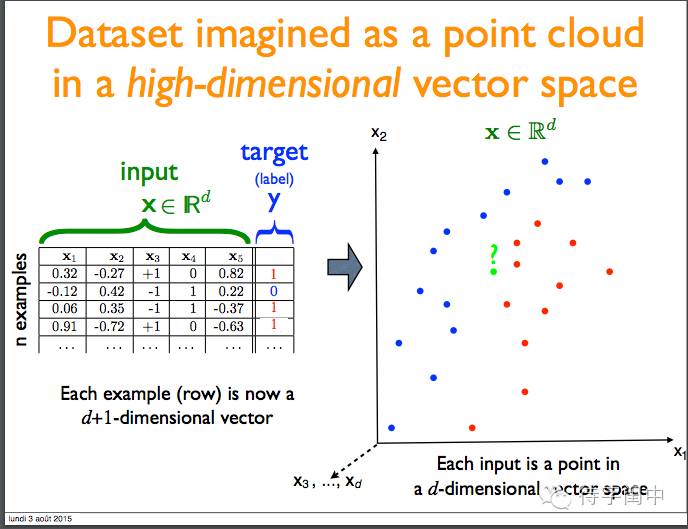
将数据集在一个高维空间表示。
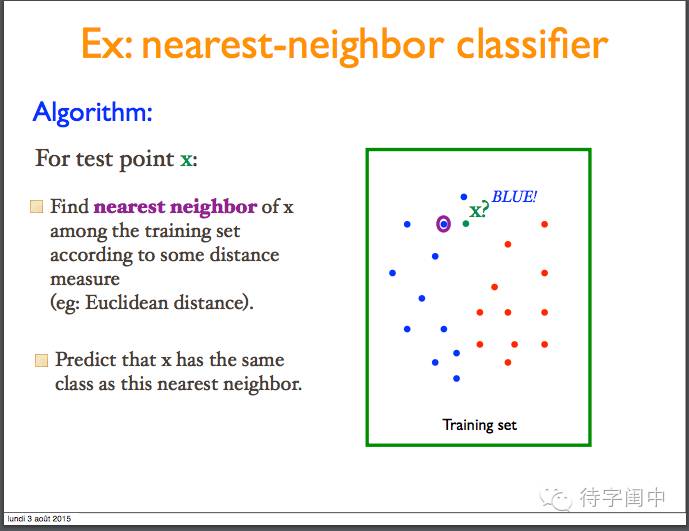
举例:nearest neighbor classifier:根据某种距离计算,在训练集中找出最近的邻居,然后预测新的样本和邻居有同样的类别。
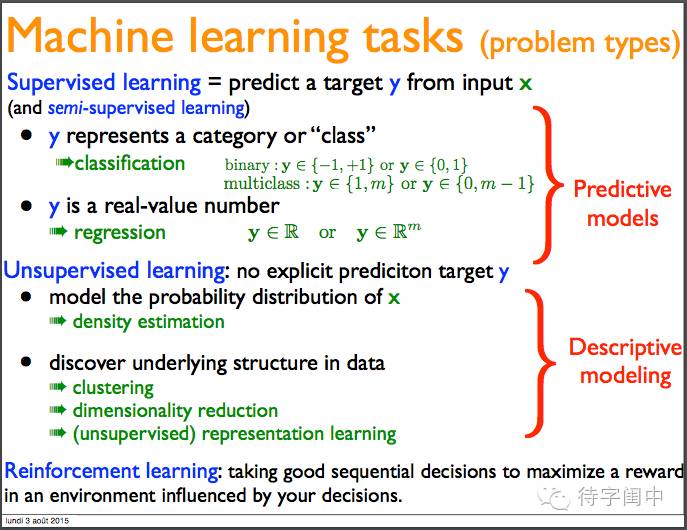
机器学习任务(问题类型):监督学习,无监督学习,强化学习。
监督学习:分类问题,回归问题。
无监督学习:概率分布模型,发现数据的内部结构(聚类,降维,表示学习)
强化学习:从与环境的交互决策过程中获取最大化回报。
学习阶段:训练,预测。目标不是记住训练集,而是要能够在新的未来的样本上很好的泛化预测。

举例:一维回归。
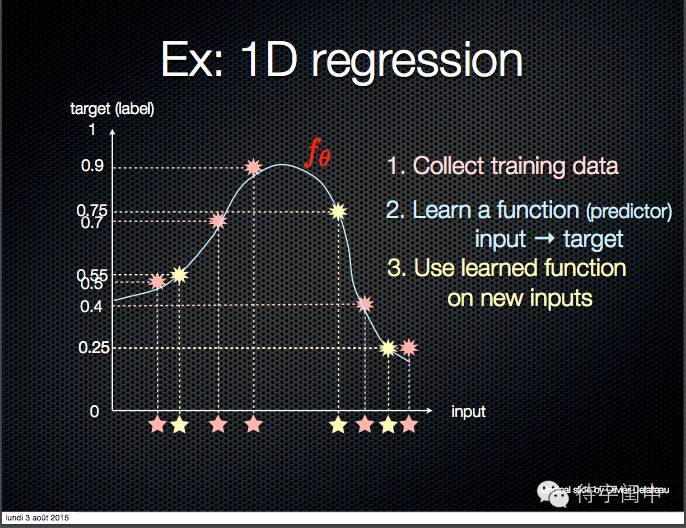
监督学习任务示例。
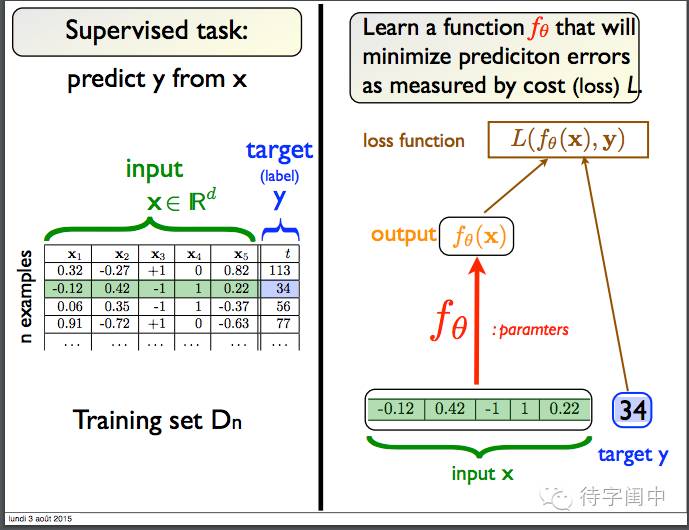
一个机器学习算法一般对应着三个部分:函数家族(模型族),评估质量(损失函数),找到最好的函数(模型)(优化)。

评估一个函数(模型)的质量,寻找最好的函数(模型)。

评估模型的标准。

对某些机器学习任务的标准损失函数。

有的损失函数很难直接去优化,所以需要替代损失函数。

期望风险:对于将来的从不知道的分布来的无限多的样本,我们的预测平均来说将会做的多差。
经验风险:对于有限的样本集,我们的预测平均来说会做的多差。

最小化经验风险。

评估泛化错误。

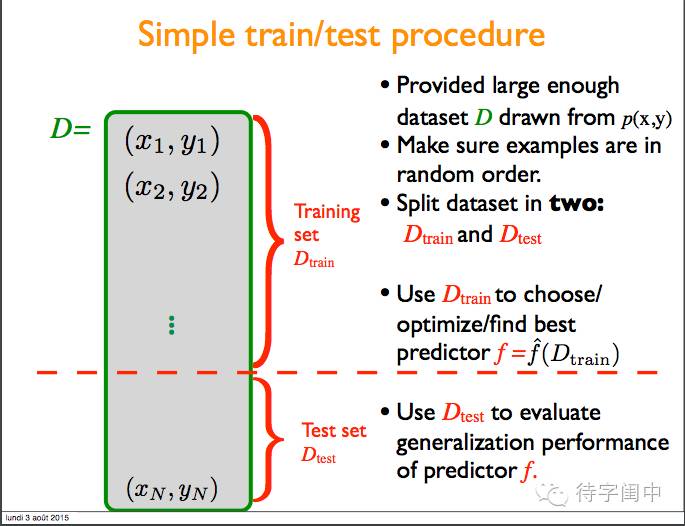
简单的训练/测试流程。将样本集随机打乱,然后分成两个部分,训练集和测试集。用训练集来选择/优化/发现最好的预测函数(模型),然后用测试集来评估模型的泛化能力。
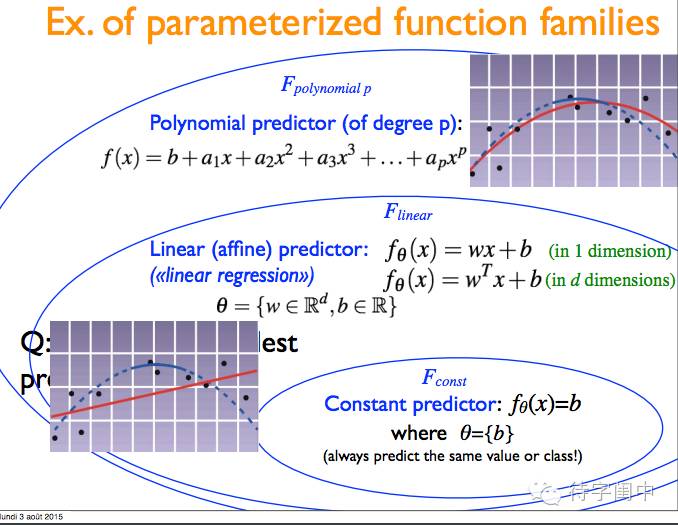
模型选择,实际上是从函数家族中选择一个特殊函数。

举例:参数化函数家族。比如常数,线性,多项式。
一个学习方法的能力。

有效能力,能力控制的超参数。

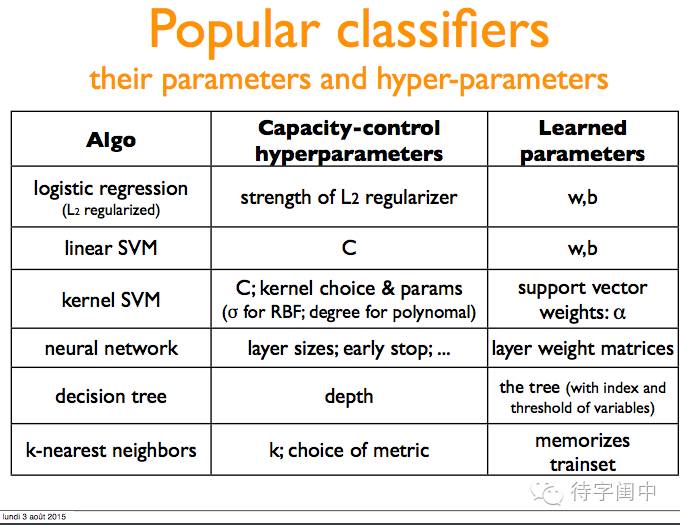
常用的分类器和它们的学些参数,超参数。
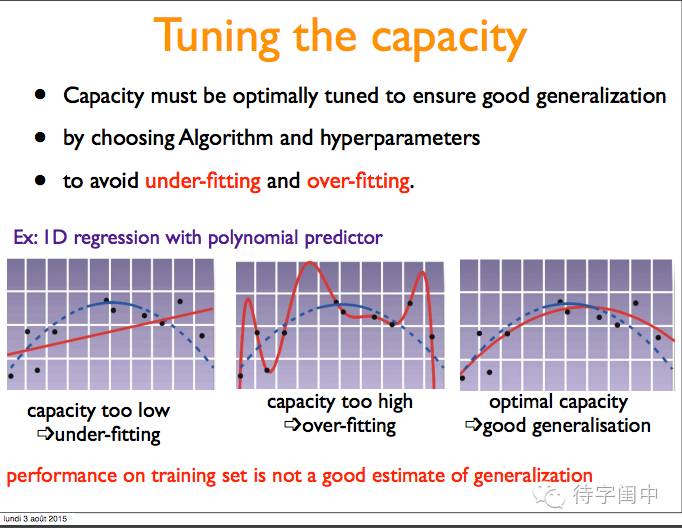
选择算法和调参来保证泛化,避免欠拟合和过拟合。
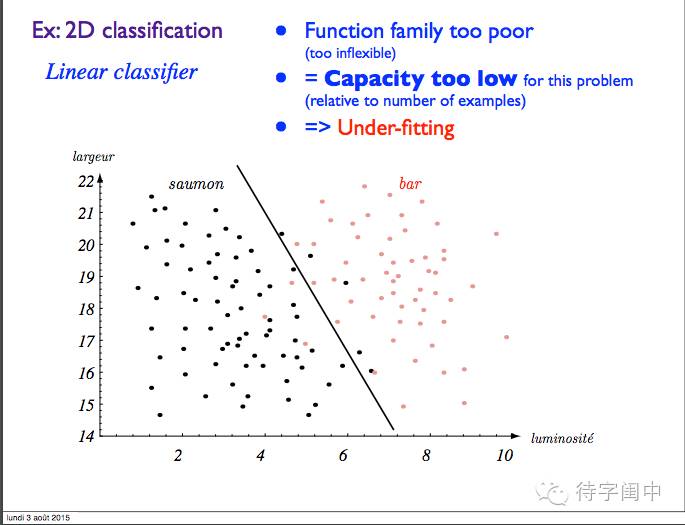
举例:二维分类。函数太差,能力有限,欠拟合。
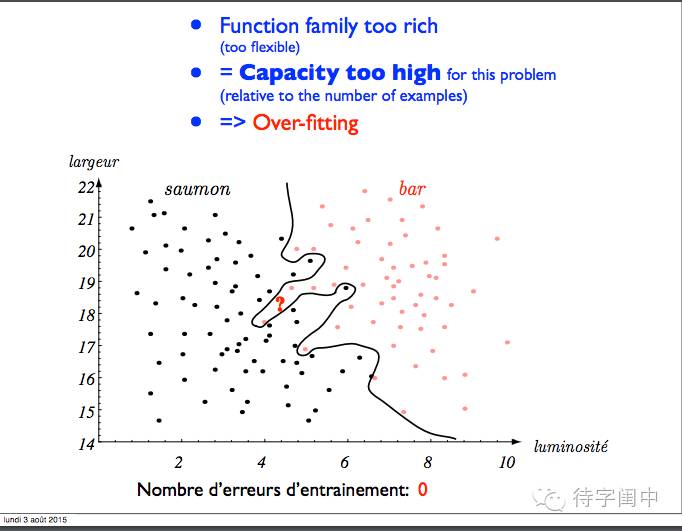
函数太强,能力高,过拟合。
最优的,最好的泛化能力。
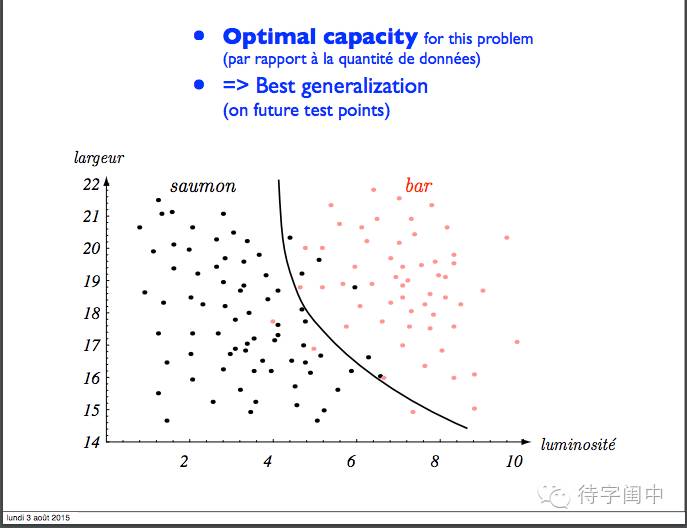
泛化错误分解。

方差的影响因素。

最优化和偏差方差的困境。

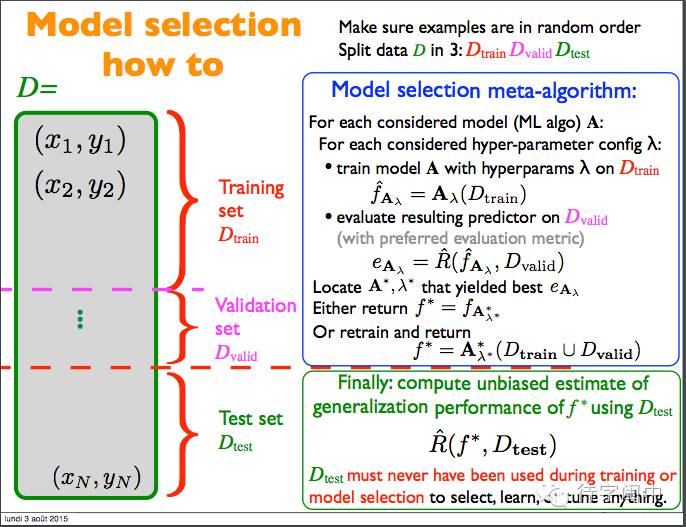
模型选择指南!!!
举例:模型的超参数选择。
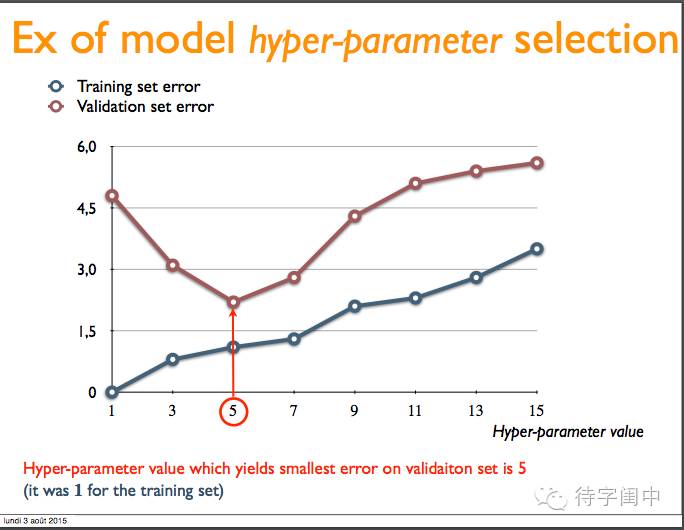
几个问题:
如果选择在训练集上效果最好的超参数会怎么样?我们倾向于选择什么?

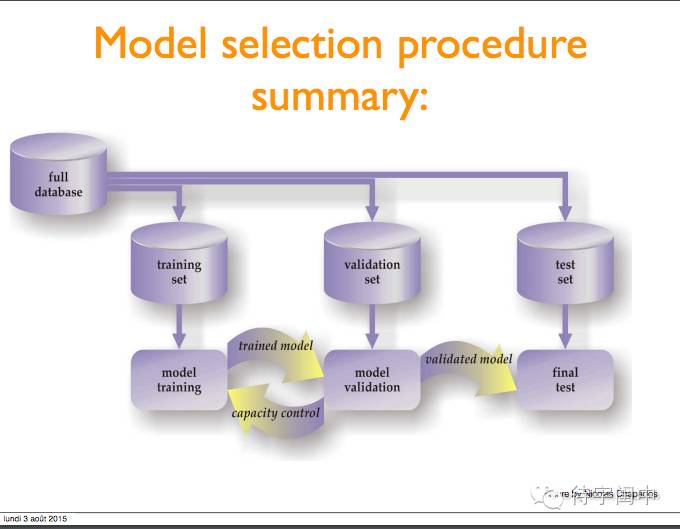
模型选择流程总结。
集成算法。
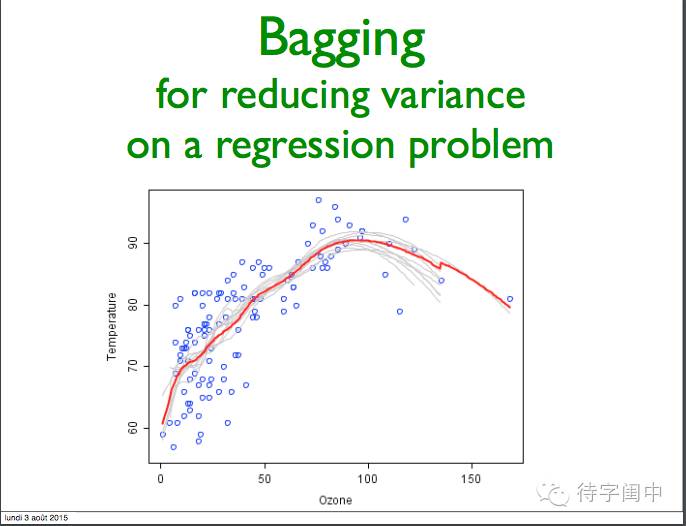
对于Bagging,其驱动的原则是通过独立的建立几种预测器进行预测,然后平均这些预测器的预测结果。在平均意义下,合并后的预测器因为减小了方差,因此其通常优于单个的预测器。
对于Boosting ,基本的预测器被以此建立,并且每一个预测器都尽量去减小合并后的预测器某一项的偏差。其动机是通过合并几个弱模型从而形成一个强有力的集成。

Bagging 减少回归问题的方差。
如何从线性预测器获取非现象预测器。

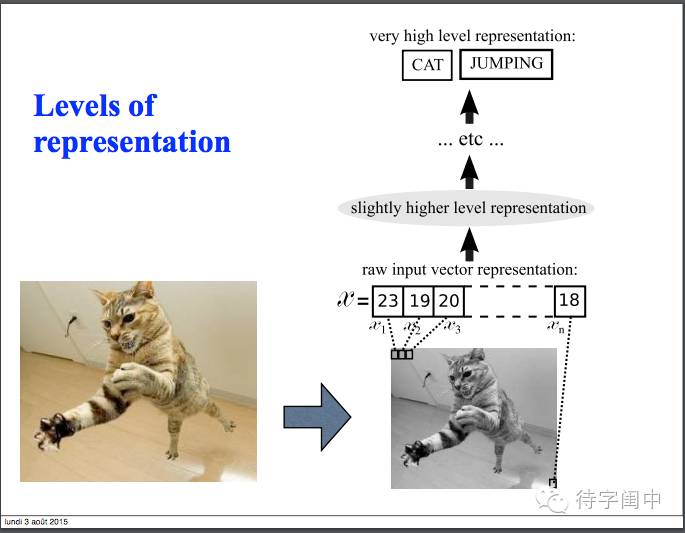
分层表示。神经元网络。