pandas主要有两种数据对象:
Series、DataFrame
注:
后面代码使用pandas版本0.20.1,通过import pandas as pd引入
1. Series
Series是一种带有索引的序列对象。
简单创建如下:
s1=pd.Series(list("1234"))print(s1)0 11 22 33 4dtype:object
2. DataFrame
类似与数据库table有行列的数据对象。
创建方式如下:
import numpy as npdf1 = pd.DataFrame(np.random.randn(6,4))print(df1) 0 1 2 30 -0.646340 -1.249943 0.393323 -1.5618731 0.371630 0.069426 1.693097 0.9074192 -0.328575 -0.256765 0.693798 -0.7873433 1.875764 -0.416275 -1.028718 0.1582594 1.644791 -1.321506 -0.337425 0.8206895 0.006391 -1.447894 0.506203 0.977295
df2 = pd.DataFrame({ 'A' : 1., 'B' : pd.Timestamp('20130102'), 'C' :pd.Series(1,index=list(range(4)),dtype='float32'), 'D' : np.array([3] * 4,dtype='int32'), 'E' : pd.Categorical(["test","train","test","train"]), 'F' : 'foo' })print(df2)
A B C D E F0 1.0 2013-01-02 1.0 3 test foo1 1.0 2013-01-02 1.0 3 train foo2 1.0 2013-01-02 1.0 3 test foo3 1.0 2013-01-02 1.0 3 train foo
3. 索引
不管是Series对象还是DataFrame对象都有一个对对象相对应的索引,
Series的索引类似于每个元素, DataFrame的索引对应着每一行。
查看:
在创建对象的时候,每个对象都会初始化一个起始值为0,自增的索引列表, DataFrame同理。
print(s1)0 11 22 33 4dtype: object
print(s1.index)
这里的增删查改主要
基于DataFrame对象,
为了有足够数据用于展示,这里选择
tushare
的数据。
1. tushare安装
创建数据对象如下:
import tushare as tsdf = ts.get_k_data("000001")
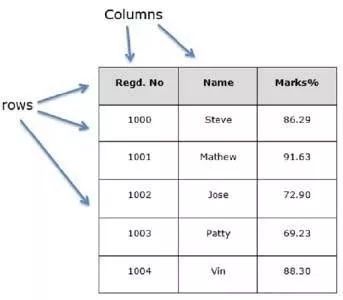
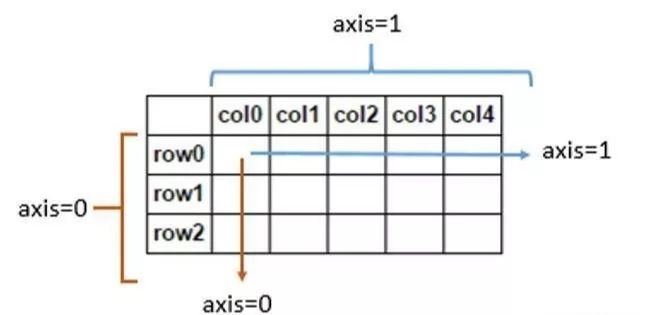
DataFrame 行列,axis 图解:
2. 查询
查看每列的数据类型
df.dtypesdate objectopen float64close float64high float64low float64volume float64code objectdtype: object
查看指定指定数量的行:
head函数默认查看前5行,tail函数默认查看后5行,可以传递指定的数值用于查看指定行数。
查看前5行df.head()date open close high low volume code0 2015-12-23 9.927 9.935 10.174 9.871 1039018.0 0000011 2015-12-24 9.919 9.823 9.998 9.744 640229.0 0000012 2015-12-25 9.855 9.879 9.927 9.815 399845.0 0000013 2015-12-28 9.895 9.537 9.919 9.537 822408.0 0000014 2015-12-29 9.545 9.624 9.632 9.529 619802.0 000001# 查看后5行df.tail()date open close high low volume code636 2018-08-01 9.42 9.15 9.50 9.11 814081.0 000001637 2018-08-02 9.13 8.94 9.15 8.88 931401.0 000001638 2018-08-03 8.93 8.91 9.10 8.91 476546.0 000001639 2018-08-06 8.94 8.94 9.11 8.89 554010.0 000001640 2018-08-07 8.96 9.17 9.17 8.88 690423.0 000001# 查看前10行df.head(10)date open close high low volume code0 2015-12-23 9.927 9.935 10.174 9.871 1039018.0 0000011 2015-12-24 9.919 9.823 9.998 9.744 640229.0 0000012 2015-12-25 9.855 9.879 9.927 9.815 399845.0 0000013 2015-12-28 9.895 9.537 9.919 9.537 822408.0 0000014 2015-12-29 9.545 9.624 9.632 9.529 619802.0 0000015 2015-12-30 9.624 9.632 9.640 9.513 532667.0 0000016 2015-12-31 9.632 9.545 9.656 9.537 491258.0 0000017 2016-01-04 9.553 8.995 9.577 8.940 563497.0 0000018 2016-01-05 8.972 9.075 9.210 8.876 663269.0 0000019 2016-01-06 9.091 9.179 9.202 9.067 515706.0 000001
查看某一行或多行,某一列或多列
# 查看第一行df
[0:1] date open close high low volume code0 2015-12-23 9.927 9.935 10.174 9.871 1039018.0 000001
# 查看 10到20行df[10:21] date open close high low volume code10 2016-01-07 9.083 8.709 9.083 8.685 174761.0 00000111 2016-01-08 8.924 8.852 8.987 8.677 747527.0 00000112 2016-01-11 8.757 8.566 8.820 8.502 732013.0 00000113 2016-01-12 8.621 8.605 8.685 8.470 561642.0 00000114 2016-01-13 8.669 8.526 8.709 8.518 391709.0 00000115 2016-01-14 8.430 8.574 8.597 8.343 666314.0 00000116 2016-01-15 8.486 8.327 8.597 8.295 448202.0 00000117 2016-01-18 8.231 8.287 8.406 8.199 421040.0 00000118 2016-01-19 8.319 8.526 8.582 8.287 501109.0 00000119 2016-01-20 8.518 8.390 8.597 8.311 603752.0 00000120 2016-01-21 8.343 8.215 8.558 8.215 606145.0 000001
# 查看看Date列前5个数据df["date"].head() # 或者df.date.head()0 2015-12-231 2015-12-242 2015-12-253 2015-12-284 2015-12-29Name: date, dtype: object
# 查看看Date列,code列, open列前5个数据df[["date","code", "open"]].head() date code open0 2015-12-23 000001 9.9271 2015-12-24 000001 9.9192 2015-12-25 000001 9.8553 2015-12-28 000001 9.8954 2015-12-29 000001 9.545
使用行列组合条件查询
df.loc[10, ["date", "code"]]
date 2016-01-07code 000001Name: 10, dtype: objectdf.loc[10:20, ["date", "code"]]
date code10 2016-01-07 00000111 2016-01-08 00000112 2016-01-11 00000113 2016-01-12 00000114 2016-01-13 00000115 2016-01-14 00000116 2016-01-15 00000117 2016-01-18 00000118 2016-01-19 00000119 2016-01-20 00000120 2016-01-21 000001
df.loc[0, "open"]9.9269999999999996
通过位置查询:
值得注意的是上面的索引值就是特定的位置。
df.iloc[0]date 2015-12-24open 9.919close 9.823high 9.998low 9.744volume 640229code 000001Name: 0, dtype: objectdf.iloc[-1]date 2018-08-08open 9.16close 9.12high 9.16low 9.1volume 29985code 000001Name: 640, dtype: objectdf.iloc[:,0].head()0 2015-12-241 2015-12-252 2015-12-283
2015-12-294 2015-12-30Name: date, dtype: object
df.iloc[2:4,[0,2]]
date close2 2015-12-28 9.5373 2015-12-29 9.624
通过条件筛选:
查看open列大于10的前5行df[df.open > 10].head()
date open close high low volume code378 2017-07-14 10.483 10.570 10.609 10.337 1722570.0 000001379 2017-07-17 10.619 10.483 10.987 10.396 3273123.0 000001380 2017-07-18 10.425 10.716 10.803 10.299 2349431.0 000001381 2017-07-19 10.657 10.754 10.851 10.551 1933075.0 000001382 2017-07-20 10.745 10.638 10.880 10.580 1537338.0 000001
# 查看open列大于10且open列小于10.6的前五行df[(df.open > 10) & (df.open < 10.6)].head() date open close high low volume code378 2017-07-14 10.483 10.570 10.609 10.337 1722570.0 000001380 2017-07-18 10.425 10.716 10.803 10.299 2349431.0 000001387 2017-07-27 10.550 10.422 10.599 10.363 1194490.0 000001388 2017-07-28 10.441 10.569 10.638 10.412 819195.0 000001390 2017-08-01 10.471 10.865 10.904 10.432 2035709.0 000001
# 查看open列大于10或open列小于10.6的前五行df[(df.open > 10) | (df.open < 10.6)].head() date open close high low volume code0 2015-12-24 9.919 9.823 9.998 9.744 640229.0 0000011 2015-12-25 9.855 9.879 9.927 9.815 399845.0 0000012 2015-12-28 9.895 9.537 9.919 9.537 822408.0 0000013 2015-12-29 9.545 9.624 9.632 9.529 619802.0 0000014 2015-12-30 9.624 9.632 9.640 9.513 532667.0 000001
3. 增加
在前面已经简单的说明Series, DataFrame的创建,这里说一些常用有用的创建方式。
s2 = pd.date_range("20180808", periods=7)print(s2)
DatetimeIndex(['2018-08-08', '2018-08-09', '2018-08-10', '2018-08-11', '2018-08-12', '2018-08-13', '2018-08-14'], dtype='datetime64[ns]', freq='D') s3 = pd.date_range("20180808", "20180809", freq="H")print(s2)
DatetimeIndex(['2018-08-08 00:00:00', '2018-08-08 01:00:00', '2018-08-08 02:00:00', '2018-08-08 03:00:00', '2018-08-08 04:00:00', '2018-08-08 05:00:00', '2018-08-08 06:00:00', '2018-08-08 07:00:00', '2018-08-08 08:00:00', '2018-08-08 09:00:00', '2018-08-08 10:00:00', '2018-08-08 11:00:00', '2018-08-08 12:00:00', '2018-08-08 13:00:00', '2018-08-08 14:00:00', '2018-08-08 15:00:00', '2018-08-08 16:00:00', '2018-08-08 17:00:00', '2018-08-08 18:00:00', '2018-08-08 19:00:00', '2018-08-08 20:00:00', '2018-08-08 21:00:00', '2018-08-08 22:00:00', '2018-08-08 23:00:00', '2018-08-09 00:00:00'], dtype='datetime64[ns]', freq='H')s4 = pd.to_datetime(df.date.head())print(s4)
0 2015-12-241 2015-12-252 2015-12-283 2015-12-294 2015-12-30Name: date, dtype: datetime64[ns]
4. 修改
df.index = pd.to_datetime(df.date)df.head()
date open close high low volume code date 2015-12-24 2015-12-24 9.919 9.823 9.998 9.744 640229.0 0000012015-12-25 2015-12-25 9.855 9.879 9.927 9.815 399845.0 0000012015-12-28 2015-12-28 9.895 9.537 9.919 9.537 822408.0 0000012015-12-29 2015-12-29 9.545 9.624 9.632 9.529 619802.0 0000012015-12-30 2015-12-30 9.624 9.632 9.640 9.513 532667.0 000001df.columns = ["Date", "Open","Close","High","Low","Volume","Code"]print(df.head())
Date Open Close High Low Volume Code date2015-12-24 2015-12-24 9.919 9.823 9.998 9.744 640229.0 0000012015-12-25 2015-12-25 9.855 9.879 9.927 9.815 399845.0 0000012015-12-28 2015-12-28 9.895 9.537 9.919 9.537 822408.0 0000012015-12-29 2015-12-29 9.545 9.624 9.632 9.529 619802.0 0000012015-12-30 2015-12-30 9.624 9.632 9.640 9.513 532667.0 000001df.Open = df.Open.apply(lambda x: x+1)df.head()
Date Open Close High Low Volume Code date2015-12-24 2015-12-24 10.919 9.823 9.998 9.744 640229.0 0000012015-12-25 2015-12-25 10.855 9.879 9.927 9.815 399845.0 0000012015-12-28 2015-12-28 10.895 9.537 9.919 9.537 822408.0 0000012015-12-29 2015-12-29 10.545 9.624 9.632 9.529 619802.0 0000012015-12-30 2015-12-30 10.624 9.632 9.640 9.513 532667.0 000001df[["Open", "Close"]].head().apply(lambda x: x.apply(lambda x: x+1))
Open Closedate 2015-12-24 11.919 10.8232015-12-25 11.855 10.8792015-12-28 11.895 10.5372015-12-29 11.545 10.6242015-12-30 11.624 10.632
5. 删除
通过drop方法drop指定的行或者列。
注意:
drop方法并不直接修改源数据,如果需要使源dataframe对象被修改,需要传入inplace=True
,通过之前的axis图解,知道行的值(或者说label)在axis=0,列的值(或者说label)在axis=1。
df.drop("Open", axis=1).head()
Date Close High Low Volume Code date
2015-12-24 2015-12-24 9.823 9.998 9.744 640229.0 0000012015-12-25 2015-12-25 9.879 9.927 9.815 399845.0 0000012015-12-28 2015-12-28 9.537 9.919 9.537 822408.0 0000012015-12-29 2015-12-29 9.624 9.632 9.529 619802.0 0000012015-12-30 2015-12-30 9.632 9.640 9.513 532667.0 000001df.drop(df.columns[[1,3]], axis=1).head() Date Close Low Volume Code date 2015-12-24 2015-12-24 9.823 9.744 640229.0 000001 2015-12-25 2015-12-25 9.879 9.815 399845.0 000001 2015-12-28 2015-12-28 9.537 9.537 822408.0 000001 2015-12-29 2015-12-29 9.624 9.529 619802.0 000001 2015-12-30 2015-12-30 9.632 9.513 532667.0 000001
数值显示格式:
当数值很大的时候pandas默认会使用科学计数法
pd.options.display.float_format = '{:.4f}'.format
1. 统计
# descibe方法会计算每列数据对象是数值的count, mean, std, min, max, 以及一定比率的值df.describe()
Open Close High Low Volumecount 641.0000 641.0000 641.0000 641.0000 641.0000mean 10.7862 9.7927 9.8942 9.6863 833968.6162std 1.5962 1.6021 1.6620 1.5424 607731.6934min 8.6580 7.6100 7.7770 7.4990 153901.000025% 9.7080 8.7180 8.7760 8.6500 418387.000050% 10.0770 9.0960 9.1450 8.9990 627656.000075% 11.8550 10.8350 10.9920 10.7270 1039297.0000max 15.9090 14.8600 14.9980 14.4470 4262825.0000
# 单独统计Open列的平均值df.Open.mean()10.786248049922001
# 查看居于95%的值, 默认线性拟合df.Open.quantile(0.95)14.187
# 查看Open列每个值出现的次数df.Open.value_counts().head()
9.8050 129.8630 109.8440 109.8730 109.8830 8Name: Open, dtype: int64
2. 缺失值处理
删除或者填充缺失值。
# 删除含有NaN的任意行df.dropna(how='any')
# 删除含有NaN的任意列df.dropna(how='any', axis=1)
# 将NaN的值改为5df.fillna(value=5)
3. 排序
按行或者列排序, 默认也不修改源数据。
df.sort_index(axis=1).head()
Close Code Date High Low Open Volumedate2015-12-24 9.8230 000001 2015-12-24 9.9980 9.7440 10.9190 640229.00002015-12-25 1.0000 000001 2015-12-25 1.0000 9.8150 10.8550 399845.00002015-12-28 1.0000 000001 2015-12-28 1.0000 9.5370 10.8950 822408.00002015-12-29 9.6240 000001 2015-12-29 9.6320 9.5290 10.5450 619802.00002015-12-30 9.6320 000001 2015-12-30 9.6400 9.5130 10.6240 532667.0000
df.sort_index(ascending=False).head()
Date Open Close High Low Volume Code date2018-08-08 2018-08-08 10.1600 9.1100 9.1600 9.0900 153901.0000 0000012018-08-07 2018-08-07 9.9600 9.1700 9.1700 8.8800 690423.0000 0000012018-08-06 2018-08-06 9.9400 8.9400 9.1100 8.8900 554010.0000 0000012018-08-03 2018-08-03 9.9300 8.9100 9.1000 8.9100 476546.0000 0000012018-08-02 2018-08-02 10.1300 8.9400 9.1500 8.8800 931401.0000 000001
安装某一列的值排序
# 按照Open列的值从小到大排序df.sort_values(by="Open") Date Open Close High Low Volume Codedate 2016-03-01 2016-03-01 8.6580 7.7220 7.7770 7.6260 377910.0000 0000012016-02-15 2016-02-15 8.6900 7.7930 7.8410 7.6820 278499.0000 0000012016-01-29 2016-01-29 8.7540 7.9610 8.0240 7.7140 544435.0000 0000012016-03-02 2016-03-02 8.7620 8.0400 8.0640 7.7380 676613.0000 0000012016-02-26 2016-02-26 8.7770 7.7930 7.8250 7.6900 392154.0000 000001
4. 合并
concat, 按照行方向或者列方向合并。
split_rows = [df.iloc[0:2,:],df.iloc[2:4,:], df.iloc[4:9]]pd.concat(split_rows)
Date Open Close High Low Volume Codedate2015-12-24 2015-12-24 10.9190 9.8230 9.9980 9.7440 640229.0000 0000012015-12-25 2015-12-25 10.8550 1.0000 1.0000 9.8150 399845.0000 0000012015-12-28 2015-12-28 10.8950 1.0000 1.0000 9.5370 822408.0000 0000012015-12-29 2015-12-29 10.5450 9.6240 9.6320 9.5290 619802.0000 0000012015-12-30 2015-12-30 10.6240 9.6320 9.6400 9.5130 532667.0000 0000012015-12-31 2015-12-31 10.6320 9.5450 9.6560 9.5370 491258.0000 0000012016-01-04 2016-01-04 10.5530 8.9950 9.5770 8.9400 563497.0000 0000012016-01-05 2016-01-05 9.9720 9.0750 9.2100 8.8760 663269.0000 0000012016-01-06 2016-01-06 10.0910 9.1790 9.2020 9.0670 515706.0000 000001
split_columns = [df.iloc[:,1:2], df.iloc[:,2:4], df.iloc[:,4:]]pd.concat(split_columns, axis=1).head()
Open Close High Low Volume Code date2015-12-24 10.9190 9.8230 9.9980 9.7440 640229.0000 0000012015-12-25 10.8550 1.0000 1.0000 9.8150 399845.0000 0000012015-12-28 10.8950 1.0000 1.0000 9.5370 822408.0000 0000012015-12-29 10.5450 9.6240 9.6320 9.5290 619802.0000 0000012015-12-30 10.6240 9.6320 9.6400 9.5130 532667.0000 000001
追加行, 相应的还有insert, 插入插入到指定位置
df.append(df.iloc[0,:], ignore_index=True).tail()
Date Open Close High Low Volume Code637 2018-08-03 9.9300 8.9100 9.1000 8.9100 476546.0000 000001638 2018-08-06 9.9400 8.9400 9.1100 8.8900 554010.0000 000001639 2018-08-07 9.9600 9.1700 9.1700 8.8800 690423.0000 000001640 2018-08-08 10.1600 9.1100 9.1600 9.0900 153901.0000 000001641 2015-12-24 10.9190 9.8230 9.9980 9.7440 640229.0000 000001
5. 对象复制
由于dataframe是引用对象,所以需要显示调用copy方法用以复制整个dataframe对象。
pandas的绘图是使用matplotlib,如果想要画的更细致, 可以使用matplotplib,
不过简单的画一些图还是不错的。
因为上图太麻烦,这里就不配图了,可以在资源文件里面查看pandas-blog.ipynb文件或者自己敲一遍代码。
# 这里使用notbook,为了直接在输出中显示,需要以下配置%matplotlib inline# 绘制Open,Low,Close.High的线性图df[["Open", "Low", "High", "Close"]].plot()
# 绘制面积图df[["Open", "Low", "High", "Close"]].plot(kind="area")