(请击点图片上方蓝色的
“
生命季刊
”
,选择
“
关注
”
,您就会每天收到生命季刊播发的文章)
亚当、夏娃长的什么样子? DNA告诉你!
——“
DNA
见证了神的创造”系列之四
文/维克
《生命与信仰》第32期
一.生命的遗传信息
1.
什么是人之初?
一本“三字经”已经读了几百年,“人之初,性本善”是这本书的第一句。那么什么是“人之初”呢?也许,您会认为,那是指每一个人离开母腹的时候。如果是这样,母腹中的胎儿就不是人了吗?
即使是认为在母腹中的胎儿已经是人的开始了,这里还有一个问题,就是在胎儿多大时,可以看作“初”?从
DNA
的最新科学来看,当一个精子与一个卵子结合成一个受精卵时,一个新的生命就正式开始了。这个受精卵形成的时刻,就是“人之初”。因为受精卵中,已经有了生命的全部信息。
2.
生命的遗传信息
信息这个词汇可能是近百年来使用最为广泛的词汇之一。而近几十年来,一个使我们生活发生巨大改变的角色,就是计算机数码信息。这简单的‘
0
’和‘
1
’给我们带来了许多意想不到的礼物:计算机、无人飞机、机器人、数码照相机、手机以及卫星通讯、互联网等等,它们都是基于这两个数码组成并传递各式各样的信息在工作。被人称作第
3
次工业革命,也叫数码化革命。数码世界由‘
0
’和‘
1
’承载全部的信息,绝对的精准。
您知道吗?生命也是靠信息来承载和遗传的。本世纪,生命科学最重要的一个结论,应该是“
DNA
是生命遗传信息的唯一载体”这一个结论了。人们意想不到的是:一切生命的信息和计算机信息十分类似,是
4
个基本编码在承载、传递和运行着。这
4
个编码就是
DNA
的
4
个碱基——用四个字母
A
、
T
、
C
、
G
代表着。什么样的
DNA
编码就有什么样的生命。由于生物
DNA
编码的恒定性,决定了一切物种不可能进化,连微进化也不会发生。
DNA
编码的恒定是基于数码化(编码与数学)的运行方式,因此和计算机数码信息的传递一样,保证了绝对的精准。
3. 人类的遗传信息
人类的遗传信息就是从父母双方来的DNA遗传信息,分别包含在精子和卵子中。精子的细胞核只有
PM2.5
的一个雾霾颗粒大小,卵子细胞核也只有
3
个雾霾颗粒大小。就是在这样小的体积内,居然各包含了
30
亿
DNA
编码。而且,正是这些编码,编制出了你和我。
是这些DNA信息确定了我们的外貌,也包含了我们的性格、智慧、天性和情感等看不见的非物质性信息。全世界人的
DNA
遗传信息,无论种族和居住的地域,差别仅仅只有千分之一左右。因此,不同民族的情感并没有差别,也都能够相互输血、器官移植,相互结婚生子、生孙。
受精卵包含了一个人全部的DNA遗传信息,其中
46
条染色体有
23
条来自父亲,包含
30
亿
DNA
编码;
23
条来自母亲,也包含
30
亿
DNA
编码;总共包含
60
亿
DNA
编码。还有来自母亲的线粒体
DNA
,里面包含了
16569
个
DNA
编码。一个针尖大小的受精卵居然包含这样多的信息,实在令人震惊。
为什么说受精卵就是“人之初”呢?因为在这个卵细胞开始分裂以后,
1
变
2
、
2
变
4
、
4
变
8
等等,直到发展成几十万亿的细胞、变成一个成人时,所有细胞里面的
DNA
编码,都是和受精卵细胞中的
DNA
编码几乎完全一样。不同细胞中的
DNA
编码,由于
DNA
复制产生突变的差异十分微小。因此说我们都是
DNA
“编织”出的人,一点也不夸张。例如,
3
个同卵双胞胎有着几乎完全相同的
DNA
编码,因此有着几乎相同的外貌。当他们长大以后,也会发现他们有着非常相近的性格。
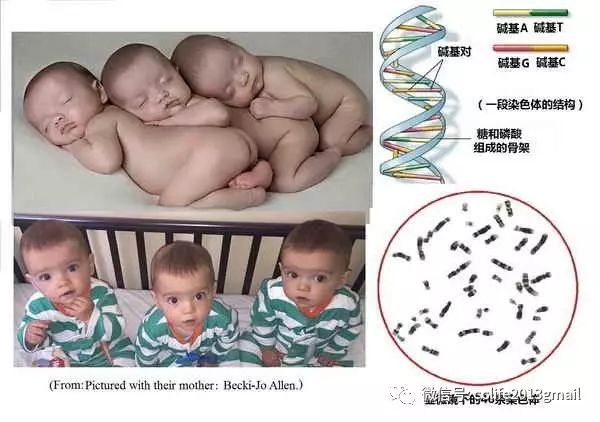
二.男女遗传信息的差别
这里,我们还要摘要一些在前3篇《生命与信仰》刊登的内容。
1. 染色体是
DNA
编码的序列
DNA的化学名称是脱氧核糖核酸,它由
4
种碱基组成。我们可以称它们是
4
种
DNA
编码,即
A
、
T
、
C
、
G
。这四种编码的序列,构成了人类
24
条染色体。男人细胞中有
22
对常染色体和一条
Y
染色体再加上一条
X
染色体;女人和男人不同的是有两条
X
染色体,没有
Y
染色体。另外,男人和女人都有由
16569
个
DNA
编码构成的环状线粒体。其中
22
条常染色体、
X
染色体和线粒体的
DNA
编码序列,男女都一样,它们占一个人的
DNA
编码数量的
98%
。
2. 人类的基因组?
人类“基因组”是指人类全套染色体(包含
22
条常染色体、
X
染色体和
Y
染色体),再加上线粒体。基因组包含有大约
31
亿
DNA
编码,男人和女人因为有双倍(
22
条)的常染色体,因此总共有约
60
亿
DNA
编码。
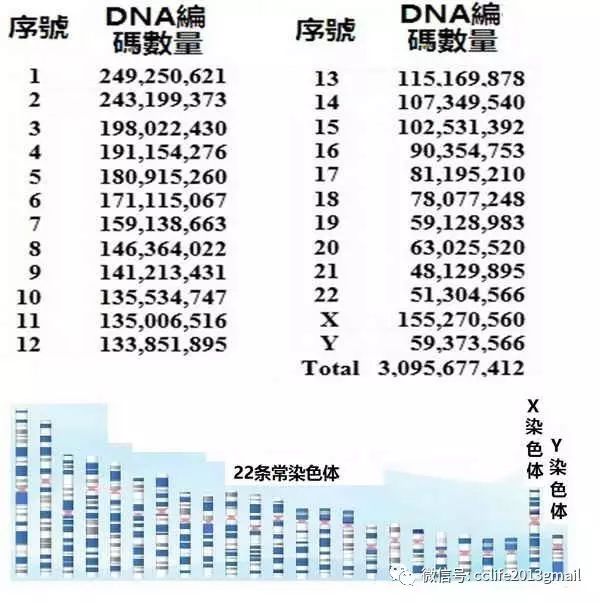
3. 女人出自男人
从人类基因组展现的事实——“男人和女人的常染色体、
X
染色体编码序列”的
29
亿
DNA
编码没有区别,归结出一个结论:人类的第一个祖先是男人,而且第一个女人出自男人。
三.生命信息遗传的减半定律
1. 从该隐、亚伯和塞特谈起
在本系列前3篇内容中,已经详述了为什么全世界人染色体的
DNA
编码都是出自最早的一位男人——科学亚当,而且最早的一位女人——科学夏娃染色体的DNA编码也是出自科学亚当。那么他们孩子们的
DNA
编码又是什么样子的呢?我们现在来回答这个问题。
我们还是使用圣经中的名字,由此来看科学亚当和科学夏娃3个儿子——科学该隐、亚伯和塞特的DNA编码。他们
3
人在成为受精卵时候,各人的
DNA
编码都是从父母那里来的,应该是一样的。然而,当他们出生时,由于已经从一个细胞复制成几万亿的细胞,经历了这几十次的复制后,他们的
DNA
编码就有了一定的差异。这个差异,就是在复制中,由于
DNA
复制中“出错”所产生的。这种出错,通常叫着
DNA
突变。
那么这些突变有多少呢?目前的研究结果是:“
DNA
复制过程中,复制速度可高达每秒复制100个碱基—DNA编码,并能达到每复制
10
亿对
DNA
编码才出错一对的准确率。”
[
注
1]
卵细胞中有60亿的
DNA
编码,每复制一次,就有
6
个突变。成长为少年时,大约有
50
次的复制,因此,突变量大约是
300
个
DNA
编码。科学该隐、亚伯和塞特和他们的爸爸、妈妈分别有
300
个
DNA
编码的差异。如果没有这些
DNA
突变,三个孩子就完全没有区别了。而且以后的人类,都会是一个样子。由此看来,
DNA
突变就不是“出错”,而是一个预先设定的、“创造生物”必须包含的规律,真是奇妙无比。
2. DNA编码遗传差异减半定律
从受精卵到成人,细胞大约经历了50次的分裂,
DNA
编码也就经历了
50
次的复制。人类细胞中的
60
亿编码,每复制一次,会有
6
个突变,
50
次的复制,将带来
300
个
DNA
编码的突变。
由于人类细胞核包含多达60亿的
DNA
编码,孩子们的
DNA
随机突变点,不可能发生在相同位置上。就如将
300
个小球,随机地撒向
60
亿个球洞,当这么多球洞都有均等的进球机会时,
3
次抛撒的
300
个球,进入同一个球洞的机会微乎其微。因此,孩子们的
300
个突变点,也基本不会都发生在同一个位点上。这样,该隐、亚伯和塞特之间的
DNA
差异,就是
600
个点。而他们与爸爸、妈妈的
DNA
差异仍然都是
300
个点。
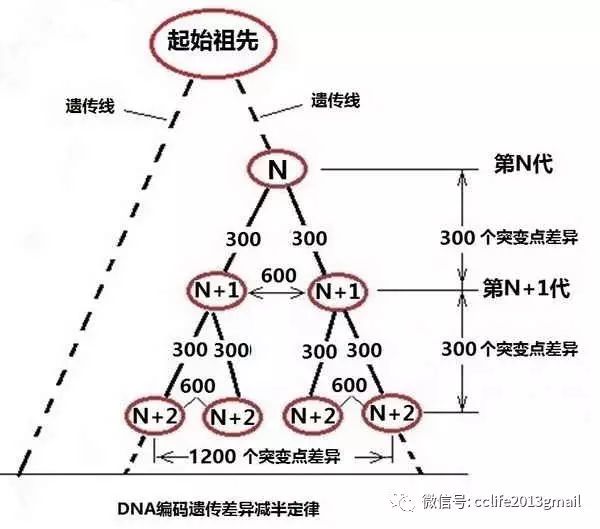
我们和自己的父母的DNA差异也是这样。由这里可以得出一个定律:孩子和父母之间
DNA
编码的差异,是孩子之间差异的一半。可以称这个定律为:
DNA
编码遗传差异减半定律。
四.亚当、夏娃长得什么样子?
1.千分之
0.5
的差异
科学亚当、夏娃的DNA编码与我们相比会有多大差异呢?这里首先要确定我们这些子孙间的
DNA
编码差异有多少?
2006年美国国立人类基因组研究所发布报告说:“
2003
年
4
月,当研究人员完成了人类基因组计划的最后分析,他们确认,人类基因组的三十亿个碱基对的遗传字母,在每个人身上都是
99.9
%的相同。这也意味着在这个星球上的个人的
DNA
差异,平均只有
0.1
%(千分之一)。”以后对世界各地一千多人(男女各半)基因组的测试结果,都证实了这个结论。
依据上述的DNA编码遗传差异减半定律,我们可以满有信心地回答:科学亚当、夏娃的
DNA
编码与我们的差异,是
0.05%(
千分之
0.5)
。
2. 科学亚当、夏娃的形象和我们的差别
以夏娃和公众人物米歇尔(又译蜜雪儿)、希拉里的DNA差异为例,可以认为米歇尔和希拉里的差异是由两条承传母线发展积累而来。她们之间积累的
DNA
差异是千分之一,那么,每条母线上的差异就应该大约是千分之一的一半。也就是说,她们分别与科学夏娃的
DNA
差异,仅仅是千分之
0.5
。

从DNA上来看,科学夏娃比米歇尔更像希拉里,或者说她比希拉里更像米歇尔。也许,由于营养没有米歇尔和希拉里那样好,她要瘦一些。这样,我们就可以推论出科学夏娃的形象了:她的样子应该介于米歇尔和希拉里的样子之间,肤色可能略偏于米歇尔。
3.非物质遗传信息的差别
人类细胞中的DNA编码,也是存储非物质遗传信息的载体。人类学习听说读写的能力、喜怒哀乐的情感,这些“非物质的遗传信息”,也必然是承载于
DNA
编码之上,代代相传。从这里可以看到,米歇尔或者希拉里,她们与科学夏娃的“非物质的遗传信息”差异,也应该仅仅是千分之
0.5
。
科学夏娃一定和她们同样的美丽、同样的聪明,所欠缺的只是没有像她们那样,分享了人类多年来积累的科学知识。简而言之,她就是一个和你我相同的人。事实上,她就像一位住在深山里的小姑娘,只要给她机会,她——科学夏娃,同样会成为普林斯顿或者耶鲁大学的优秀毕业生。
关于我们与科学亚当的差别,也应该是如此。还必须注意,减半定律是建立在我们全部人类,有一对共同的老老祖先——科学亚当科学夏娃这个前提之下。
五.没有所谓的微进化
从这里我们也可以看到:人类没有发生进化,连微进化也没有发生。这些是否十分出于您的意料之外呢?我们再来看看其它的一些证据。
1. 付巧妹的发现
最近,有一个新的古人DNA编码资料发表在“自然”期刊上。这是华裔女科学家付巧妹领衔发表的科学报告。他们从俄罗斯西伯利亚的一块
4
万
5
千年的古人遗骨上,得到了最古老人类的完整基因组。对比现代人的
DNA
样本进行的测算,结论是:常染色体的突变率是
10
亿分之
0.4
到
0.6(
每点
-
每年
)
,
Y
染色体的突变率是
10
亿分之
0.7
到
0.9(
每点
-
每年
)
。
依上述数据推算,4万
5
千年来,常染色体
DNA
的突变量,即与现代人
DNA
样本的差异,大约是千分之
0.027
。而现代人之间
DNA
的差异是千分之一,因此可以确定,这个古人与现代人
DNA
编码几乎没有区别。也说明
4
万
5
千年来,人类根本没有发生任何进化。
2. 化石的证据
1967年,埃塞俄比亚东非奥莫(
Omo
)河附近,发现了两个古人类的头骨化石。这两个被称为
Omo
人化石,经氩同位素测定法确定他们生活在距今
19.6
万年前,是迄今发现的最为古老现代人化石。
科学家依据头骨化石,制作出Omo人的面貌复原模型。头骨的面貌复原工艺技术,在现代的法医学、人类学、和电脑三
D
等技术的支援下,已经发展得相当成熟。目前采用的泥塑面貌法是首先制作一个头骨的石膏模型,根据解剖学参数,在石膏模型上打下许多孔,在每个孔中插入一根木条,使木条向外突出的长度等于该处的软组织厚度。再在眼窝处用塑胶眼球填充,面部的肌肉则用一层层堆积起来的陶土表现,直到所有的木条被覆盖,最后加上五官,进行整体修饰。
对这种技术的验证,是让这方面的专家不看头骨原人的照片,制作出其人的面貌复原模型,再与此人的照片进行对照,技术精湛的专家能够制作出非常逼真的面貌复原模型。所以,专家们制作出的Omo人的面貌复原模型
(
见下图
)
,应该是可信的。
此外,2002年,在罗马尼亚的山洞中,又发现了
3.4
万年前古人化石。法医学艺术家理查尼夫重建了他的复原像。他说
:
“实际上这个头像看起来是欧洲人、亚洲人和非洲人三者的混合体,这大概就是最早来到欧洲的现代人”。

对照这两个复原像 (上图
)
,可以看出,它与现代人几乎没有区别。
3.为什么不相信微进化
有人不相信宏观进化论,但是相信有“科、属、种”内的进化,即微进化论。持这种观点认为人就是由“能人和直立人”进化而来。










