MQ 异步队列是微信后台自研的重要组件,广泛应用在各种业务场景中,为业务提供解耦、缓冲、异步化等能力。本文介绍该组件2.0版本的功能特点及优化,为队列设计提供参考。 MQ 1.0 发布之初,基本满足了一般业务场景的异步化需求,实现了单机下高性能的任务持久化和消费调度。1.0 的基本框架如下图所示:
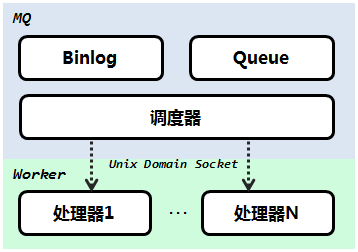
可以看到,其主要分为 MQ 和 Worker 两部分。MQ 是任务的持久化和调度框架,Worker 是任务的处理框架。该组件与常见的队列相比,有几个特点:
随着业务发展,面对日益复杂的业务场景,1.0 版本逐渐显得力不从心。因此,在 1.0 的基础上,我们实现了 MQ 2.0 版本,主要优化点包括以下几方面:
下面对各个优化点详细讲解。
IOS消息通知功能,是MQ组件的一个典型应用场景。微信的后台具有多IDC分布的特点,不同IDC与苹果推送服务(APNs)之间的网络质量参差不齐,部分链路故障频发。
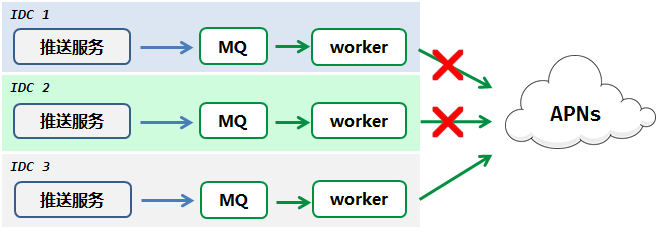
由于MQ 1.0 的任务只能本机消费,网络质量的下降将直接导致 Worker 消费能力的下降,进而产生积压,最终使消息服务质量受损。
为此,我们提出了跨机消费模式。其目标是实现一个去中心化、自适应的弹性消费网络,以解决系统中出现的局部积压问题。
消费模式从单机扩展到多机后,我们要面临的核心问题是,哪些任务给哪个 Worker 去处理。其实,考虑多机房、多IDC、带宽成本、任务延时等因素,我们很容易得到一个直观而朴素的思想:
任务优先在本机消费,产生积压时才发生跨机消费。
如何实现我们想要的跨机消费呢?经过思考,我们将问题分解为三个子问题:
拉任务还是推任务?
Worker 如何感知 MQ 的积压?
Worker 如何消除 MQ 的积压?
下面逐一进行讨论。
MQ 1.0 下,MQ 可以准确观察到本机 Worker 的负载状态,并由其将任务推送给空闲的 Worker 进行处理。推送的方式可以将任务的处理延时做到极低。
扩展到跨机消费后,Worker 可以消费任意 MQ 的任务。对 MQ 而言,已经难以精确地维护全网每个 Worker 的状态了。若继续沿用推任务的方式,很可能会出现 Worker 接收到超过其处理能力的任务量,从而产生积压。
若使用 Worker 拉取任务的方式,则拉取的速度可以根据 Worker 自身的消费能力调整,但在任务延时上,需要有所牺牲。
经过简单的权衡,我们选用了拉任务的方式,毕竟,我们难以接受任务积压在 Worker 侧的情况。
前面提到,系统应该在任务出现积压时,才产生跨机消费。因此,MQ 在产生积压时,应该要能以某种形式通知 Worker。同时,积压量的变化是很快的,通知的方式应该做到以下几方面的高效:
速度:尽可能地快;
精度:尽可能少地发送通知,减少无效通知的发送;
为此,我们实现了广播模式,将 MQ 产生的积压量信息作为一个消息,广播给 多个Worker。
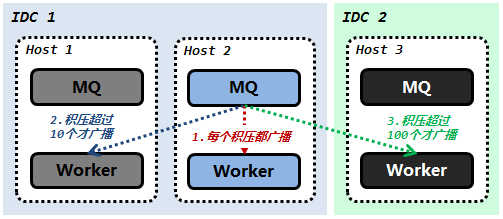
它在实现上如何满足高效的积压通知要求呢?
通过广播模式,我们高效地解决了 MQ 积压的感知问题。
通过广播模式,每个Worker 都可以观察到所有它感兴趣的 MQ 的积压情况,并以此构建出整个系统的积压分布统计。拿到这些信息后,Worker 如何决定拉取哪个 MQ 的任务呢?
还是回到我们的原始诉求,尽量做到本机消费。所以我们的策略是说,Worker 应该优先消除本机的积压,当它有余力的时候,才去帮助其它Worker。
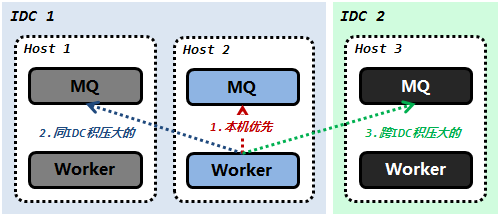
通过分优先级地拉取,既可在队列系统正常时大量降低跨机消费,同时也可以在故障发生时,有效地消除局部积压。
跨机消费模式,从整个系统角度来看,是完全去中心化的,任意一个 MQ 和 Worker 个体都可以独立、自由地加入或退出系统。
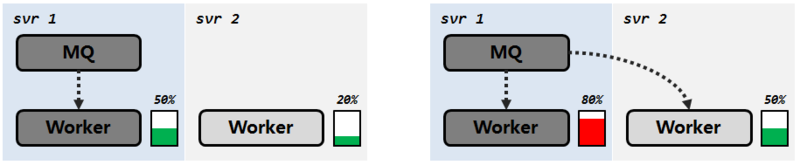
在这个竞争式的消费系统里,根据具体的部署情况、不同机型消费能力不同等因素,无法达到完全的负载均衡状态。但在系统产生局部过载时,则可以自适应调节,达到相对的均衡。
从实际应用效果来看,MQ 2.0实现了通知推送服务的IDC级别容灾,即使只剩下一个IDC可用,也可以做到推送质量纹丝不动。
MQ 2.0 对跨机消费模式的支持,为业务提供了一种新的队列容灾模式:
MQ 与 Worker 可完全分离部署,分别规划机器数量,按需部署,互不影响;
MQ 的局部积压可以通过扩容 Worker进行消除;
Worker 的局部消费能力下降可以由其它 Worker 自动容灾;
微信发布已有6年多的时间,后台的业务逻辑演化至今,往往是非常的复杂,我们来看一个比较极端的例子 —— 群聊批量并行化投递。

上图是群消息投递业务的简化流程示意。随着微信群消息体量的高速膨胀,其带来的成本压力越来越大,业务同学提出了批量并行化的优化方式。简单来说,就是将每个步骤中产生的 RPC 访问按实际访问机器聚合成一系列的批量操作,然后并行化执行。
通常来说,单次的批量并行化并不难写,一般而言,业务同学可能会选择裸写。但如果涉及多次的批量并行化,其中还存在嵌套的话,事情就不那么简单了。最终代码将变得异常复杂,业务开发的同学苦不堪言。MQ 能否从框架上解决这类问题?
其实,深入分析群消息投递的优化需求,可以看到:
所以,为了从根本上解决这一类问题,MQ 为业务提供了类 MapReduce 任务处理框架。
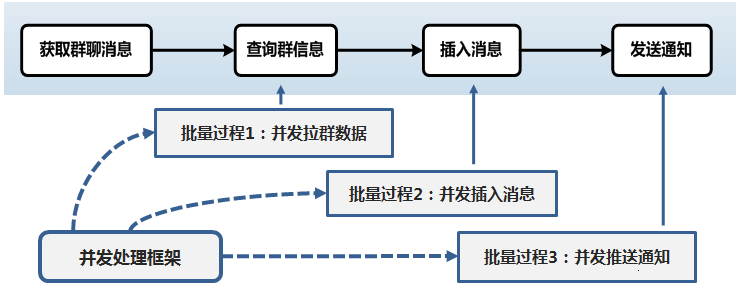
该框架提供封装了通用的 MR 过程,以及并发的调度过程,同时提供并发池隔离能力,解决了并发池饿死的问题。让业务同学可以从冗繁的代码中解放出来,将更多的精力投入到实际业务中。
除了批量并行化的需求,业务经常提到的一个需求是,任务处理时会产生一些新的任务需要加到队列中。一般来说是走一次 RPC 来执行任务入队。在 MQ 2.0 下,流式任务可以帮忙完成这个事情。
所谓流式任务,就是在任务处理结束时,除了返回任务结果,还可以返回一系列新的任务。这些任务通过 MQ 内部框架流转入队,更轻量,事务性更强。
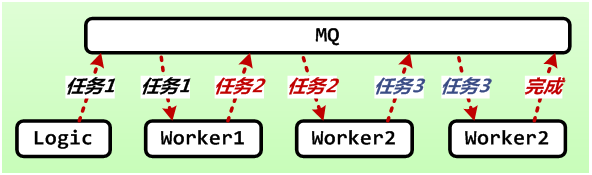
相比常规的同步处理模型,它提供了一种轻量的逻辑异步化模型。一个冗长的逻辑可以切分为很多小的功能块进行串联和复用,每一级之间都有 MQ 去充当缓冲和调度。
虽然这种处理模式并不适用于所有逻辑,但作为组件功能的一部分,它提供了一种新的解决问题的能力。
MQ 2.0 提供的类 MapReduce任务处理框架和流式任务处理框架,为业务的实现提供了便利的支持。
MQ的重要作用是充当系统中的缓冲节点,流量控制的能力是非常关键的。在 MQ 1.0 下,只能通过配置队列的任务出队速度来实现流量控制。其问题有几个:
配置需要人工调整,难以估算对后端的实际访问;
后端处于过载状态时无法自适应调整;
自己处于过载状态时无法自适应调整;
从需求来看,MQ 的过载保护需求有两个方面,一是保护自己不过载,二是保护后端不过载。
导致过载的因素很多,从 MQ 的角度来看,这些因素可以分为两大类。一种是它能直接观察的因素,如自身的 CPU 使用率,内存使用率,任务执行的成功率;另一种是无法直接观察的因素,如业务实际对后端产生的调用量。
从这两类因素出发,我们将过载保护的策略分为两大策略:
下面分别讨论两种策略。
该限速策略很好理解,就是在 CPU 使用率过高时,降低任务处理速度,以将 CPU 资源优先用于保证队列的缓存能力。
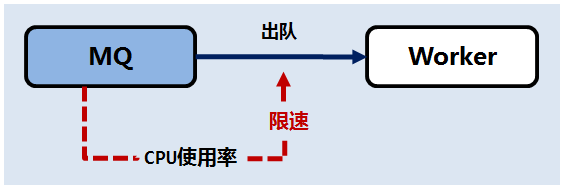
后端模块故障时,往往会导致队列任务出现大量的失败和重试,这些重试的量级往往会远超该后端模块设计的有效输出,给故障恢复带来很大的困难。
该流控策略的通过收集任务执行的成功率信息,评估后端的有效输出,并通过反馈计算限制任务重试的速度。
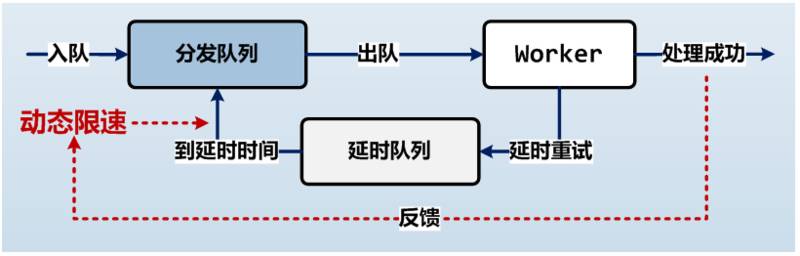
MQ 实现了通用的后向限速能力,业务通过特定接口往 MQ 回传控制量,达到速度调控的目的。
我们经常会遇到一些业务在处理任务时,存在不同程度的对后端的扩散访问。仅对任务处理速度进行限制,无法准确限制对后端产生的实际调用量。
该策略通过收集业务对后端产生的实际调用量,反向调节任务处理的速度。
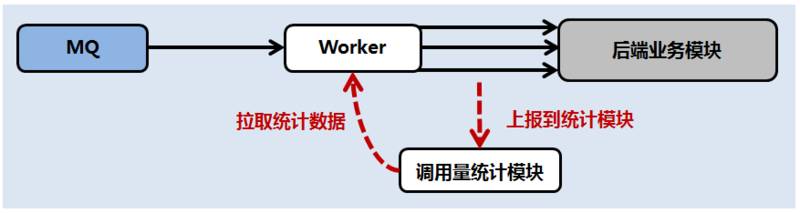
MQ 2.0 通过分析流控需求,在前向和后向分别提供了有效的流控手段,并且为后续更精细的流控策略预留了拓展的能力,增强了过载保护的能力。
微信的队列组件,与业界其他队列相比,其突出的特点是更贴近实际业务场景,极大地解放了业务同学的生产力。
MQ 2.0 在 1.0 的基础上,在任务调度、任务处理、过载保护这几方面做了大量的工作和尝试,目前已在微信各个核心业务模块运行,并经历了2017年除夕流量洪峰的考验。
后续,将在任务持久化容灾和调度性能上,对该组件进行持续的优化。关于 MQ 有任何疑问及想法,欢迎与作者讨论。
作者介绍
廖文鑫,2013年加入腾讯,从事微信后台基础功能及架构的开发和运营,先后参与了消息通知推送系统、任务队列组件、春晚摇红包活动等项目,在海量分布式高性能系统方面有丰富的经验。
今日荐文
点击下方图片即可阅读

360胡宁:通往CTO的道路上就是四个字......










