大家都说“我要做大数据”, 然后“你想象中的做大数据到底是做什么?”,大多数人往往说不出来。
大数据行业的生态、未来大数据领域都有哪些发展机会、不同岗位需要具备什么能力,对于这些问题,显然很多人都不了解。
大数据业务流程有4个基本环节,分别是:业务理解、数据准备、数据挖掘、分析应用。在这个流程里有三个职能领域:
大数据抽取转换及加载过程(ETL)是大数据的一个重要处理环节,Extract即是从业务数据库中抽取数据,Transform即是根据业务逻辑规则对数据进行加工的过程,Load即是把数据加载到数据仓库的过程。
数据抽取工具实现db到hdfs数据导入功能,提供高效的分布式并行处理能力,可以采用数据库分区、按字段分区、分页方式并行批处理抽取db数据到hdfs文件系统中,能有效解决按字段分区数据导致各分区数据不均匀导致作业负载不均衡的问题。
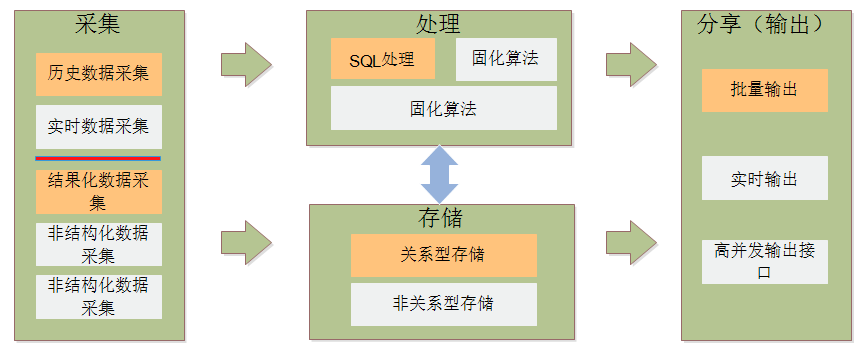
数据采集可以是历史数据采集也可以是实时数据采集,可以采集存储在数据库这种结构化数据,也可以采集各类文本、图片、图像、音频、视频等等非结构化数据,另外还可以采集结构变化很大的半结构化数据,数据采集完毕后可以直接存储在交通状态分析平台上(存储方式有两种:关系型存储、非关系型存储),经过处理、存储的数据可以进行批量输出、实时输出以及高并发输出接口。
支持使用传统ETL的方式从关系数据库(Oracle、DB2、SQL Server、MySQL、PostgreSQL)获取关系型数据,保存到分布式存储系统中。支持使用自主研发的适配器、组件从Excel、文本文件解析数据,保存到分布式存储,以及使用适配器采集视频、音频等。
支持从Kafka实时接收业务数据,保存到分布式存储系统中。
支持通过Flume实时获取日志数据包括从Linux console、RPC(Thrift-RPC)、文本文件、Unix tail、syslog日志系统获取日志数据,并保存到分布式数据库中。
分布式存储系统用于将数据分散存储在多台独立的设备上,以避免传统的集中式存储导致系统性能、可靠性瓶颈的产生的问题,以满足大规模存储应用的需要。
支持采用HDFS(Hadoop Distribution File System)、Hive、HBase作为分布式存储系统。这些Hadoop核心组件同时也提供了底层的访问接口,用于数据访问。
可为每个作业分配独立的作业任务处理工作线程和任务执行队列,作业之间互不干扰 。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理,以达到节约整体计算时间,大大提高计算效率的目的。
支持以HTTP Restful接口方式、Web Service接口方式,以及JDBC/ODBC等方式分享数据。可采用批量输出、实时输出和高并发输出的形式,不同的输出形式可以使用不同的大数据组件来完成。
CDA大数据就业班适合时间充裕、零基础想转行大数据的学员。比如在校数学、经济、计算机、统计等专业教师和学生,想职位晋升、薪酬提高学员系统学习,毕业可推荐相关工作单位。
培训师资均来自实务界相关领域的讲师、教授、专家、工程师以及企业资深分析师。CDA大数据课程符合企业用人需求,从大数据编程——数据库编程——大数据仓库——大数据分析方法——数据挖掘算法——大数据真实项目应用——大数据解决方案等,主要软件应用Hadoop、HDFS、MapReduce、Hbase、Hive、Sqoop等理论知识和大数据平台生态环境,重点学习数据分析基础和数据挖掘经典算法应用,Spark大数据分析工具和Python完美结合让你事半功倍。
大数据在企业应用公开课视频
工资要加剧,就学大数据,转行大数据领域的朋友要抓紧了,近期6月18日开课,提前报名有优惠,赠送往期预习视频。
座机:010-68456523(张老师)
Q Q: 2931495854
邮箱:[email protected]








