作者:CSDN优秀博主 专栏作家 「不会停的蜗牛」
目录:
-
kaggle 是什么?
-
如何参赛?
-
解决问题一般步骤?
-
进一步:
-
提交结果
Kaggle 是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决。
https://www.kaggle.com/
点击导航栏的 competitions 可以看到有很多比赛,其中正式比赛,一般会有奖金或者工作机会,除了正式比赛还有一些为初学者提供的 playground,在这里可以先了解这个比赛,练习能力,再去参加正式比赛。
https://www.kaggle.com/competitions
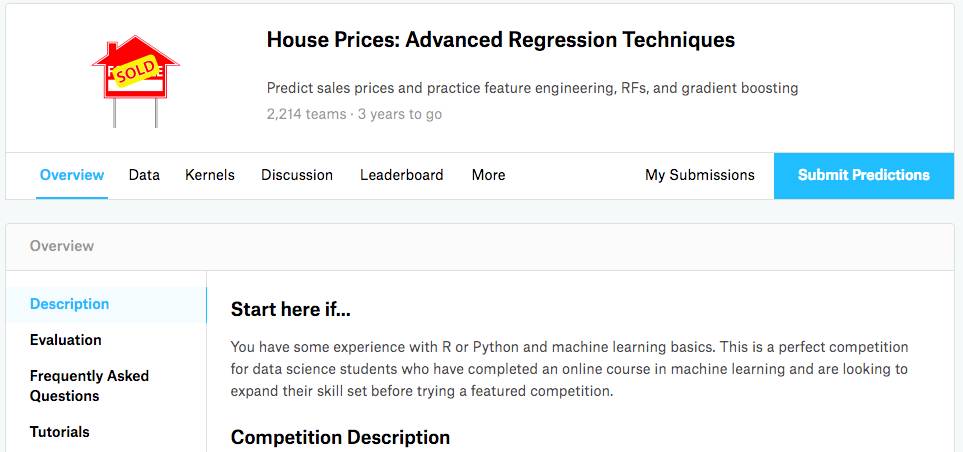
以 playground 中的这个 House Prices 预测为例
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
-
Overview: 首先在 overview 中仔细阅读问题的描述,这个比赛是让我们预测房价,它会给我们 79 个影响房价的变量,我们可以通过应用 random forest,gradient boosting 等算法,来对房价进行预测。
-
Data:在这里给我们提供了 train 数据集,用来训练模型;test 数据集,用来将训练好的模型应用到这上面,进行预测,这个结果也是要提交到系统进行评价的;sample_submission 就是我们最后提交的 csv 文件中,里面的列的格式需要和这里一样。
-
Kernels:可以看到一些参赛者分享的代码。
-
Discussion:参赛者们可以在这里提问,分享经验。
-
Leaderboard:就是参赛者的排行榜。
参加 kaggle 最简单的流程就是:
-
第一步:在 Data 里面下载三个数据集,最基本的就是上面提到的三个文件,有些比赛会有附加的数据描述文件等。
-
第二步:自己在线下分析,建模,调参,把用 test 数据集预测好的结果,按照 sample_submission 的格式输出到 csv 文件中。
-
第三步:点击蓝色按钮 ’Submit Predictions’ ,把 csv 文件拖拽进去,然后系统就会加载并检验结果,稍等片刻后就会在 Leaderboard 上显示当前结果所在的排名位置。
上传过一次结果之后,就直接加入了这场比赛。正式比赛中每个团队每天有 5 次的上传机会,然后就要等 24 小时再次传结果,playground 的是 9 次。
应用算法解决 Kaggle 问题,一般会有以下几个步骤:
-
识别问题
-
探索数据
-
数据预处理
-
将 train.csv 分成 train 和 valid 数据
-
构造新的重要特征数据
-
应用算法模型
-
优化模型
-
选择提取重要特征
-
再次选择模型,进行训练
-
调参
-
重复上述过程,进一步调优
-
预测
当然上面是相对细的分步,如果简化的话,是这么几大步:
-
探索数据
-
特征工程
-
建立模型
-
调参
-
预测提交
之前写过一篇文章,《一个框架解决几乎所有机器学习问题》
http://blog.csdn.net/aliceyangxi1987/article/details/71079448
里面的重点是介绍了常用算法模型一般需要调节什么参数,即第四步。
还有这篇,《通过一个kaggle实例学习解决机器学习问题》
http://blog.csdn.net/aliceyangxi1987/article/details/71079473
主要介绍了第三步建立模型的部分,包括 ensemble 的例子。
今天这篇文章算是一个补充,在观察数据和特征构造上学习几种常用的方式。
以 House prices 为例,探索数据常用方法有以下 6 步。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
1. 首先,在 data_description.txt 这里有对 79 个变量含义非常详细的描述
我们可以先通过阅读变量含义,根据常识猜测一下,哪些变量会对预测结果有比较重要的影响。
例如:
OverallQual: Overall material and finish quality 物料和质量应该是很重要的组成。
GrLivArea: Above grade (ground) living area square feet 面积也是明显的因素。
YearBuilt: Original construction date 时间也有影响。
2. 接着,对要预测的目标数据 y 有一个宏观的把握,这里是输出 summary,也可以用 boxplot,histogram 等形式观察
df_train['SalePrice'].describe()
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64
count 就是有多少行观察记录,另外注意一下 min 并未有小于 0 的这样的不合理的数值。
3. 通过 Correlation matrix 观察哪些变量会和预测目标关系比较大,哪些变量之间会有较强的关联
corrmat = df_train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);
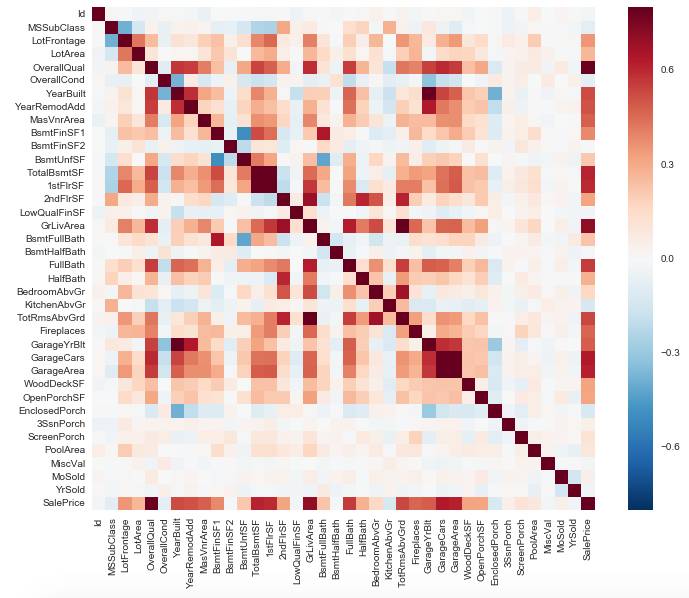
我们可以看上图的最右边一列(也可以是下面最后一行),颜色由深到浅查看,可以发现 OverallQual 和 GrLivArea 的确是对目标影响较大的因素,另外观察中间区域的几个深色块,例如 ‘TotalBsmtSF’ 和 ‘1stFlrSF’ 二者关系较强,回看它们的定义,它们所包含的信息差不多所以才有显示出强关联:
TotalBsmtSF: Total square feet of basement area
1stFlrSF: First Floor square feet
那这种时候,我们可以只取其中一个特征。
或者我们可以把与目标 ‘SalePrice’ 最紧密关联的 10 个变量的关联度打印出来:
k = 10 cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True,
fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values,
xticklabels=cols.values)
plt.show()
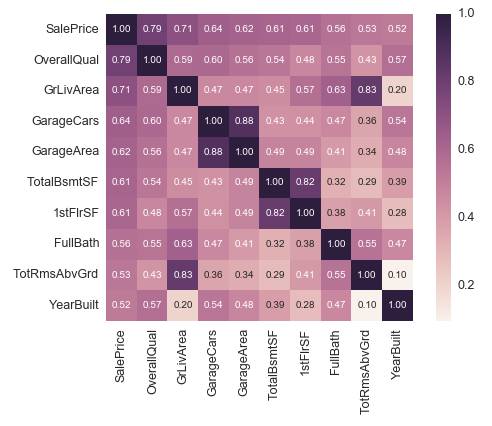
通过这些数值,我们再一一观察变量含义,判断一下是否可以把其中某些变量删除。
4. 接下来看 missing value
total = df_train.isnull().sum().sort_values(ascending=False)
percent =
(df_train.isnull().sum()/df_train.isnull().count())
.sort_values(ascending=False)missing_data =
pd.concat([total, percent], axis=1,
keys=['Total', 'Percent'])missing_data.head(20)
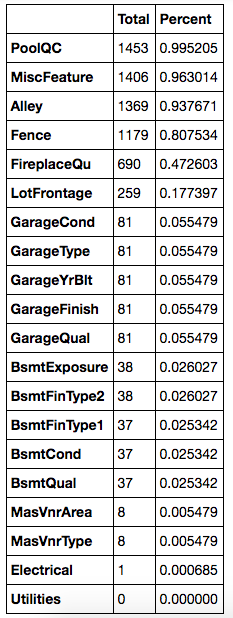
先把每个变量的 NaN 记录个数求和算出来,再把所占的比例计算一下,对于占比例太大的变量,例如超过了 15%,就看看它的含义,如果不是很重要,这种数据是可以删掉的,对于剩下的,再一个一个查看变量的含义,及比例,判断是否可以删掉,最后一个变量只有一条是 missing 的,那么就可以只删掉这一个记录。
此外,我们还可以通过补充 missing 的值,通过实际变量的含义进行补充,例如类别型变量,就可以补充成 No,数值型变量可以补充成 0,或者用平均值来填充。
df_train = df_train.drop((missing_data[missing_data['Total'] >
1]).index,1)
df_train =
df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index)
5. 下面是看 outliers
我们可以先来看主要的几个变量的 outliers
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
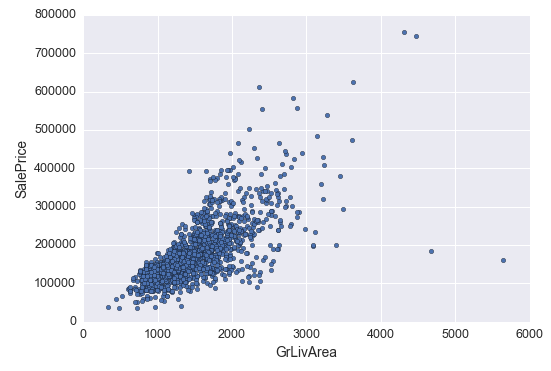
例如 ‘GrLivArea’ 这个变量,它的右下角这几个点离主体就比较远,可以猜测一下产生这样数据的原因,但因为不能代表主体的,所以此时先删掉:
df_train.sort_values(by = 'GrLivArea', ascending = False)[:2]
df_train = df_train.drop(df_train[df_train['Id'] == 1299].index)
df_train = df_train.drop(df_train[df_train['Id'] == 524].index)
6. 很重要的一步是把不符合正态分布的变量给转化成正态分布的
因为一些统计检验方法需要数据满足正态分布的条件。
sns.distplot(df_train['SalePrice'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['SalePrice'









