作者:
周雷皓 ,百度外卖大数据工程师。
来自:
《程序员》3月技术板原创投稿。
摘要:
本文介绍了大数据引擎Greenplum的架构和部分技术特点,从GPDB基本背景开始,在架构的层面上讲解GPDB系统内部各个模块的概貌,然后围绕GPDB的自身特性,并行执行和运维等技术细节,阐述了为什么选择使用Greenplum作为下一代的查询引擎解决方案。
Greenplum的MPP架构
Greenplum(以下简称GPDB)是一款开源数据仓库。基于开源的PostgreSQL改造,主要用来处理大规模数据分析任务,相比Hadoop,Greenplum更适合做大数据的存储、计算和分析引擎。
GPDB是典型的Master/Slave架构,在Greenplum集群中,存在一个Master节点和多个Segment节点,其中每个节点上可以运行多个数据库。Greenplum采用shared
nothing架构(MPP)。典型的Shared
Nothing系统会集数据库、内存Cache等存储状态的信息;而不在节点上保存状态的信息。节点之间的信息交互都是通过节点互联网络实现。通过将数据分布到多个节点上来实现规模数据的存储,通过并行查询处理来提高查询性能。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。

图1 GPDB的基本架构
如上图1为GPDB的基本架构,客户端通过网络连接到gpdb,其中Master
Host是GP的主节点(客户端的接入点),Segment
Host是子节点(连接并提交SQL语句的接口),主节点是不存储用户数据的,子节点存储数据并负责SQL查询,主节点负责相应客户端请求并将请求的SQL语句进行转换,转换之后调度后台的子节点进行查询,并将查询结果返回客户端。
Greenplum Master
Master只存储系统元数据,业务数据全部分布在Segments上。其作为整个数据库系统的入口,负责建立与客户端的连接,SQL的解析并形成执行计划,分发任务给Segment实例,并且收集Segment的执行结果。正因为Master不负责计算,所以Master不会成为系统的瓶颈。
Master节点的高可用(图2),类似于Hadoop的NameNode
HA,如下图,Standby Master通过synchronization process,保持与Primary
Master的catalog和事务日志一致,当Primary Master出现故障时,Standby Master承担Master的全部工作。
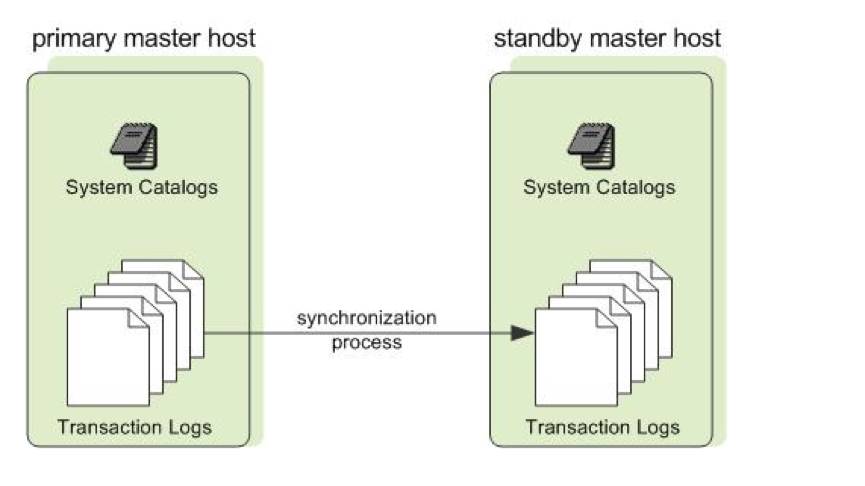
图2 Master节点的高可用
Segments
Greenplum中可以存在多个Segment,Segment主要负责业务数据的存储和存取(图3),用户查询SQL的执行,每个Segment存放一部分用户数据,但是用户不能直接访问Segment,所有对Segment的访问都必须经过Master。进行数据访问时,所有的Segment先并行处理与自己有关的数据,如果需要关联处理其他Segment上的数据,Segment可以通过Interconnect进行数据的传输。Segment节点越多,数据就会打的越散,处理速度就越快。因此与Share
All数据库集群不同,通过增加Segment节点服务器的数量,Greenplum的性能会成线性增长。
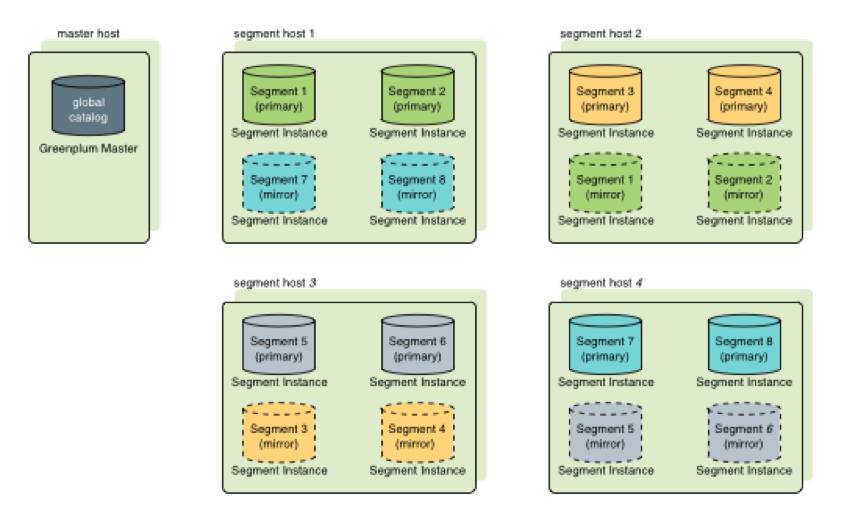
图3 Segment负责业务数据的存取
每个Segment的数据冗余存放在另一个Segment上,数据实时同步,当Primary
Segment失效时,Mirror Segment将自动提供服务,当Primary
Segment恢复正常后,可以很方便的使用gprecoverseg -F工具来同步数据。
Interconnect
Interconnect是Greenplum架构中的网络层(图4),是GPDB系统的主要组件,默认情况下,使用UDP协议,但是Greenplum会对数据包进行校验,因此可靠性等同于TCP,但是性能上会更好。在使用TCP协议的情况下,Segment的实例不能超过1000,但是使用UDP则没有这个限制。
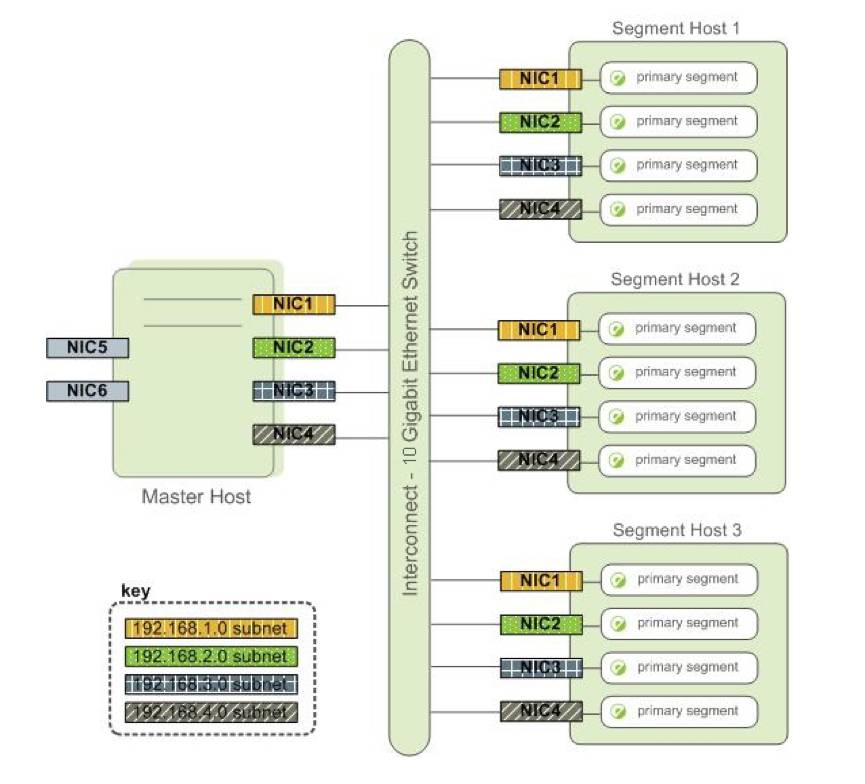
图4 Greenplum网络层Interconnect
Greenplum,新的解决方案
前面介绍了GPDB的基本架构,让读者对GPDB有了初步的了解,下面对GPDB的部分特性描述可以很好的理解为什么选择GPDB作为新的解决方案。
丰富的工具包,运维从此不是事儿
对比开源社区的其他项目在运维上的困难,GPDB提供了丰富的管理工具,图形化的web监控页面,帮助管理员更好的管理集群,监控集群本身以及所在服务器的运行状况。
最近的公有云集群迁移过程中,impala总查询段达到100的时候,系统开始变得极不稳定,后来在外援的帮助下发现是系统内核本身的问题,在恶补系统内核参数的同时,发现GPDB的工具也变相的填充了我们的短板,比如提供了gpcheck和gpcheckperf等命令,用以检测GPDB运行所需要的系统配置是否合理以及对相关硬件做性能测试,如下,执行gpcheck命令后,检测sysctl.conf中参数的设置是否符合要求,如果对参数的含义感兴趣,可以自行百度学习。

(点击可查看高清版)
另外,在安装过程中,用其提供的gpssh-exkeys命令打通所有机器免密登录后,可以很方便的使用gpassh命令对所有的机器批量操作,如下图演示了在master主机上执行gpssh命令后,在集群的五台机器上批量执行pwd命令。
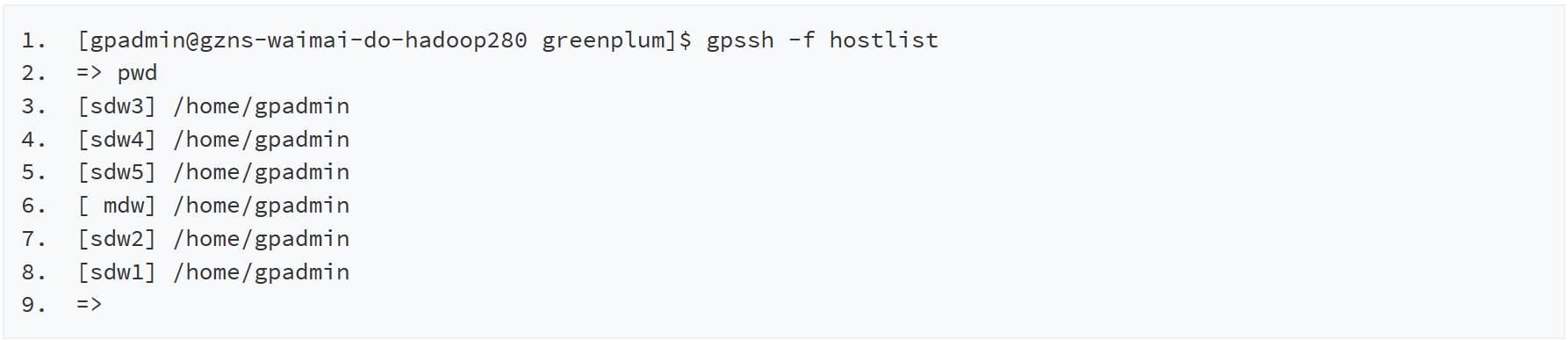
(点击可查看高清版)
诸如上述的工具GPDB还提供了很多,比如恢复segment节点的gprecoverseg命令,比如切换主备节点的gpactivatestandby命令,等等。这类工具的提供让集群的维护变得很简单,当然我们也可以基于强大的工具包开发自己的管理后台,让集群的维护更加的傻瓜化。
查询计划和并行执行,SQL优化利器
查询计划包括了一些传统的操作,比如:扫表、关联、聚合、排序等。另外,GPDB有一个特定的操作:移动(motion)。移动操作涉及到查询处理期间在Segment之间移动数据。
下面的SQL是TPCH中Query 1的简化版,用来简单描述查询计划。

(点击可查看高清版)
执行计划执行从下至上,可以看到每个计划节点操作的额外信息。
-
Segment节点扫描各自所存储的customer表数据,按照过滤条件生成结果数据,并将自己生成的结果数据依次发送到其他Segment。
-
每个Segment上,orders表的数据和收到的rs做join,并把结果数据返回给master
上面的执行过程可以看出,GPDB是将结果数据给每个含有orders表数据的节点都发了一份。为了最大限度的实现并行化处理,GPDB会将查询计划分成多个处理步骤。在查询执行期间,分发到Segment上的各部分会并行的执行一系列的处理工作,并且只处理属于自己部分的工作。重要的是,可以在同一个主机上启动多个postgresql数据库进行更多表的关联以及更复杂的查询操作,单台机器的性能得到更加充分的发挥。
如何查看执行计划?
如果一个查询表现出很差的性能,可以通过查看执行计划找到可能的问题点。
• 计划中是否有一个操作花费时间超长?
• 规划期的评估是否接近实际情况?
• 选择性强的条件是否较早出现?
• 规划期是否选择了最佳的关联顺序?
• 规划其是否选择性的扫描分区表?
• 规划其是否合适的选择了Hash聚合与Hash关联操作?
高效的数据导入,批量不再是瓶颈









